這篇用 Jupyter 可直接驗證的方式,帶你搞懂:
Path.read_text()/Path.write_text()能不能取代open()?- 什麼情境適合用「一行搞定」的便利方法
- 什麼情境必須回到
open()/Path.open()
(逐行、大檔、追加、二進位、細節控制) - 範例檔案一律輸出到:
D:\Temp
注意:以下以 Windows 路徑
D:\Temp為準;
若你機器沒有 D 槽,請把路徑改成你存在的資料夾。
0) Jupyter 先做準備:建立輸出資料夾 & 測試檔名前綴
把下面整段當成第一個 cell 執行:
from pathlib import Path
from datetime import datetime
# 你指定的輸出位置
BASE_DIR = Path(r"D:\Temp")
BASE_DIR.mkdir(parents=True, exist_ok=True)
# 為了避免覆蓋舊檔,用時間戳做一個前綴
stamp = datetime.now().strftime("%Y%m%d_%H%M%S")
PREFIX = f"path_demo_{stamp}"
BASE_DIR, PREFIX1) 一句話結論:不能「完全取代」,但能涵蓋很多日常情境
Path.read_text()/Path.write_text():適合小~中型「文字檔」整檔讀寫open()/Path.open():需要串流、追加、二進位、或精細控制時必用
你可以把它記成:
read_text/write_text是「整碗端走」;open是「想吃多少盛多少、想怎麼吃都行」。
2) 最常用:read_text() / write_text()(整檔文字讀寫)
2.1 寫入文字(覆寫)
p = BASE_DIR / f"{PREFIX}_hello.txt"
content = "第一行:你好\n第二行:Hello\n第三行:股東會旺季\n"
p.write_text(content, encoding="utf-8")
print("已寫入:", p)
print("檔案大小(bytes):", p.stat().st_size)2.2 讀出文字(整檔讀回字串)
text = p.read_text(encoding="utf-8")
print(text)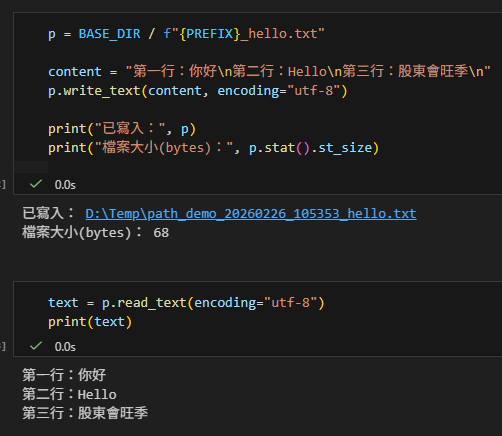
適用情境
- 設定檔、README、模板、較小 JSON、程式產生的文字報表
不適用 - 超大檔案(會一次全部載入記憶體)
3) write_text() 的限制:沒有「追加」模式(append)
想要「每次寫一行 log」那種需求:要用 open() / Path.open() 的 "a"。
logp = BASE_DIR / f"{PREFIX}_app.log"
# 追加兩行
with logp.open("a", encoding="utf-8") as f:
f.write("log: start\n")
f.write("log: next step\n")
print(logp.read_text(encoding="utf-8"))4) 大檔/逐行處理:用 Path.open()(或 open())串流讀
read_text() 會把整個檔案讀進 RAM;若檔案大,建議逐行。
先生成一個稍微多行的檔案做示範:
bigp = BASE_DIR / f"{PREFIX}_many_lines.txt"
with bigp.open("w", encoding="utf-8") as f:
for i in range(1, 51):
f.write(f"line {i}\n")
# 逐行讀 + 統計
count = 0
with bigp.open("r", encoding="utf-8") as f:
for line in f:
count += 1
print("逐行讀取行數:", count)5) 二進位檔案:用 read_bytes() / write_bytes() 或 open('rb'/'wb')
文字 API(read_text/write_text)不適合圖片、壓縮檔等二進位內容。
binp = BASE_DIR / f"{PREFIX}_data.bin"
data = bytes(range(256)) # 0..255
binp.write_bytes(data)
read_back = binp.read_bytes()
print("二進位長度:", len(read_back))
print("前10個位元組:", read_back[:10])6) 需要「細節控制」時:Path.open() 完勝 read_text/write_text
例如:
errors="replace":遇到無法解碼的字元別報錯,改用替代符號newline="":控制換行處理- 讀一小段
read(1024)、游標seek/tell、buffering 等
示範:分段讀(chunk):
chunkp = BASE_DIR / f"{PREFIX}_chunk.txt"
chunkp.write_text("A" * 5000 + "B" * 5000, encoding="utf-8")
with chunkp.open("r", encoding="utf-8") as f:
first_100 = f.read(100)
f.seek(4900)
around_boundary = f.read(300)
print("前100字:", first_100[:20], "...", len(first_100))
print("跨邊界片段:", around_boundary.count("A"), "個A,", around_boundary.count("B"), "個B")7) 想「安全寫入」(避免寫到一半中斷造成檔案毀損):用暫存檔 + replace
這類需求通常也離不開 open() 的流程控制。
import os
target = BASE_DIR / f"{PREFIX}_atomic.txt"
tmp = BASE_DIR / f"{PREFIX}_atomic.tmp"
# 寫到 tmp
with tmp.open("w", encoding="utf-8") as f:
f.write("這是一份安全寫入的內容\n")
f.write("寫完才會取代正式檔\n")
# 原子替換(同磁碟分割通常可做到原子性)
os.replace(tmp, target)
print("完成:", target)
print(target.read_text(encoding="utf-8"))8) 最佳選擇速查表

9) 你可以直接套用的「實務習慣」
- 用
Path管路徑(拼路徑更乾淨):p = BASE_DIR / "x.txt" - 讀寫檔案時:
- 整檔小文字:
read_text/write_text - 其他全部:優先
Path.open()(它就是「Path 版本的 open」)
- 整檔小文字:
推薦hahow線上學習python: https://igrape.net/30afN
,計算新光人壽增有利IRR,免費下載IRR計算機")
![Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2024/02/20240208093926_0.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?")
)")

")
")
 ; 如何獲取pandas.DataFrame多層索引MultiIndex中的第二層內容? df.columns.get_level_values(1).unique()")
、ravel()與reshape(-1)的完整指南 #flatten(): 總是建立副本")


近期留言