sample.docx內容僅有一小段文字
下方插入一張大圖檔,
容量1021KB:

🎯 教學目標
用一個只有「一段文字 + 一張圖片」的 sample.docx(原始約 1020.6 KB)示範:
為什麼刪掉顯示圖片的段落,檔案幾乎不會變小
正確刪除圖片所需的「關係 (relationship) + 圖片檔」雙重步驟
如何掃描圖片引用的 rId
如何 prune(精簡)後將檔案縮到 9.8 KB
如何建立純文字極簡版本(約 35.8 KB)
延伸:何時選擇「保留圖片」 vs 「全砍」模式
🔍 前置:DOCX 內部結構速覽
DOCX 本質是 ZIP 封包,圖片不是「塞在段落裡」,而是獨立檔案,段落只是引用它:
一張圖片若 1000 KB,
刪掉它所在的 <w:p> 只會減少幾百 bytes(XML 壓縮後很小),
真正要「瘦」必須刪它的 media 檔與關係。
🧪 實驗基準
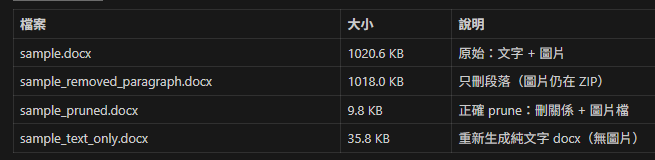
🧬 圖片引用核心結構(簡化 XML)
<w:p>
<w:r>
<w:drawing>
<wp:inline>
<a:graphic>
<a:graphicData>
<pic:pic>
<pic:blipFill>
<a:blip r:embed="rId4"/>
</pic:blipFill>
</pic:pic>
</a:graphicData>
</a:graphic>
</wp:inline>
</w:drawing>
</w:r>
</w:p>document.xml:

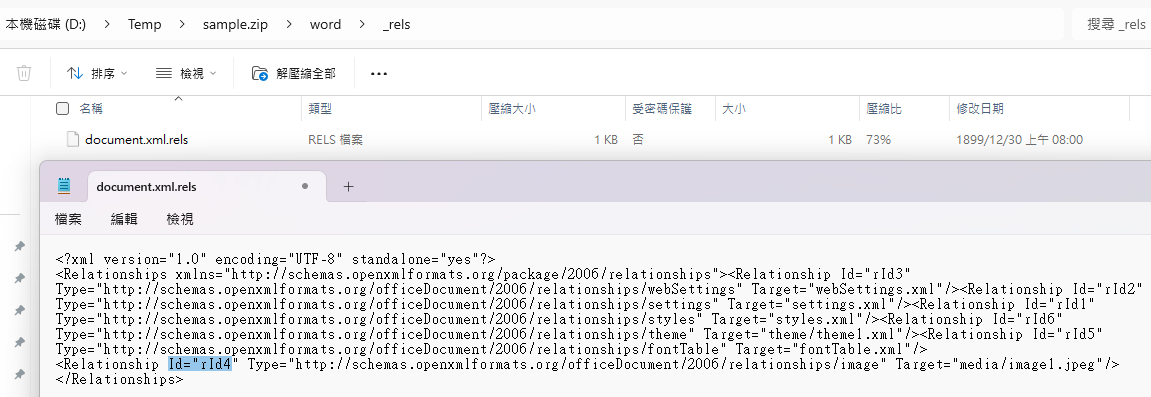
對應在 word/_rels/document.xml.rels:
<Relationship Id="rId4"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media/image1.jpeg"/>只刪 <w:p>:顯示消失,但 image1.jpeg 還在。
刪 <Relationship> 但不刪圖檔:圖檔仍佔空間。
必須「雙刪」:才真正瘦。
🛠️ 全部流程一鍵示範(Python 腳本)
保存為 docx_image_demo.py,執行:python docx_image_demo.py
(需先 pip install python-docx)
import zipfile, re, shutil, os
from pathlib import Path
from docx import Document
from docx.oxml import OxmlElement
from docx.oxml.ns import qn
SOURCE = Path(r"D:\Temp\sample.docx")
OUT_DIR = Path(r"D:\Temp\docx_demo_out"); OUT_DIR.mkdir(exist_ok=True)
def kb(p: Path): return f"{p.stat().st_size/1024:.1f} KB"
def read(zpath: Path, name: str):
"""
讀取 DOCX (其實是 ZIP) 容器內部指定成員的文字內容。
參數:
zpath: 外層 .docx 檔案路徑 (Path 或 str)。
name: ZIP 內部『相對路徑 / part 路徑』,必須與 ZipFile.namelist() 之一完全一致。
常見範例:
'[Content_Types].xml'
'_rels/.rels'
'word/document.xml'
'word/_rels/document.xml.rels'
'word/media/image1.jpeg'
'word/theme/theme1.xml'
'word/settings.xml'
'word/styles.xml'
'word/webSettings.xml'
'word/fontTable.xml'
'docProps/core.xml'
'docProps/app.xml'
"""
with zipfile.ZipFile(zpath,'r') as zf:
return zf.read(name).decode('utf-8','ignore')
def read_bytes(zpath: Path, name: str) -> bytes:
"""
讀取 ZIP / DOCX 內部任意成員的原始 bytes(適用圖片、二進位資源)。
"""
with zipfile.ZipFile(zpath, 'r') as zf:
return zf.read(name)
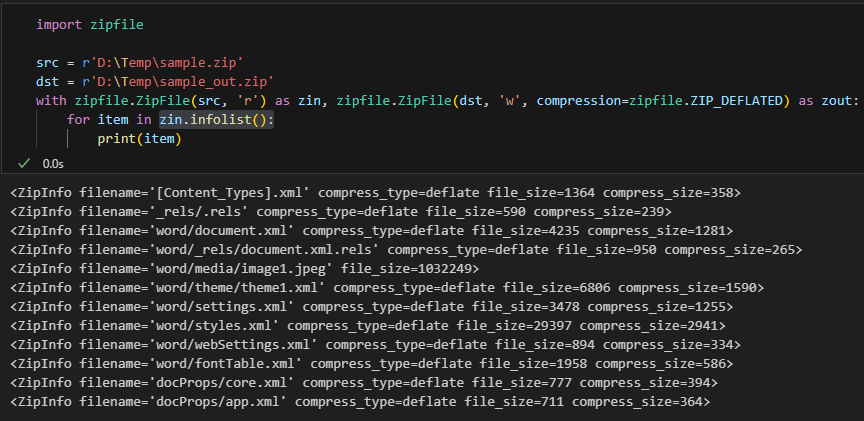
def list_media(zpath: Path):
with zipfile.ZipFile(zpath,'r') as zf:
media = [i for i in zf.namelist() if i.startswith("word/media/")]
print(f"[media] {len(media)} files")
for m in media:
print(" -", m, f"({zf.getinfo(m).file_size/1024:.1f} KB)")
print()
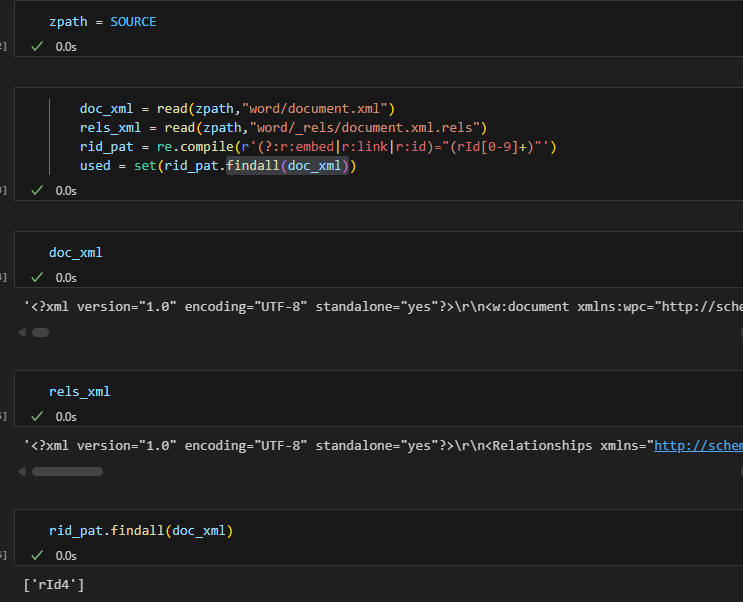
def find_rids(zpath: Path):
doc_xml = read(zpath,"word/document.xml")
rels_xml = read(zpath,"word/_rels/document.xml.rels")
rid_pat = re.compile(r'(?:r:embed|r:link|r:id)="(rId[0-9]+)"')
used = set(rid_pat.findall(doc_xml))
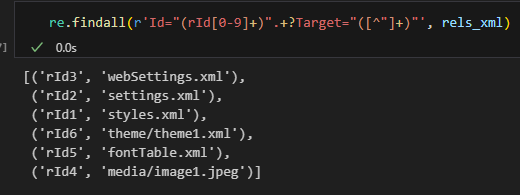
rel_map = dict(re.findall(r'Id="(rId[0-9]+)".+?Target="([^"]+)"', rels_xml))
image_rids = {rid:tgt for rid,tgt in rel_map.items() if tgt.startswith("media/")}
print("[rIds used in document.xml]:", used)
print("[image relationships]:")
for rid,tgt in image_rids.items():
print(f" {rid} -> {tgt} (in-use? {'YES' if rid in used else 'NO'})")
return used, image_rids
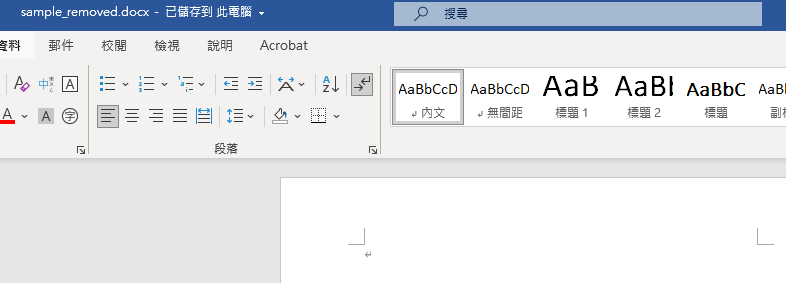
def remove_paragraph_with_rid(zpath: Path, rid: str, out: Path):
xml = read(zpath,"word/document.xml")
new_xml, n = re.compile(r'<w:p[^>]*>.*?'+rid+r'.*?</w:p>', re.DOTALL).subn('', xml, count=1)
#這一段正則應該過度貪婪了,匹配到兩段w:p
with zipfile.ZipFile(zpath,'r') as zin,
zipfile.ZipFile(out,'w',zipfile.ZIP_DEFLATED) as zout:
for item in zin.infolist():
data = zin.read(item.filename)
if item.filename == "word/document.xml":
zout.writestr(item.filename, new_xml if n else xml)
else:
zout.writestr(item, data)
print(f"[remove_paragraph] removed? {bool(n)} -> {out.name}")
def prune_unused_images(zpath: Path, out: Path):
"""
這個函式是透過「找出正文仍在用的 rId → 清掉 rels 內未用 rId →
重建 ZIP 並跳過對應媒體檔」來刪除未使用的圖片,
因此既移除了關聯,也從實體 /word/media 中真正刪掉檔案,
達到瘦身效果。
若追求健壯性與可維護性,建議改用 XML 解析 + 樹操作
來處理 rels 與 used rId,
並擴大掃描範圍以涵蓋所有可能插圖來源。
另一種策略:
getparent().remove(node) 是在已解析的 XML 樹上刪節點
如果想用樹操作版(展示 getparent/remove 的語意),
可參考這個更健壯的實作:
解析所有可能含圖片引用的部件,收集 used rId
解析 document.xml.rels,
刪除未使用且為影像的 Relationship 節點
重建 ZIP 並跳過對應媒體檔案
"""
doc_xml = read(zpath,"word/document.xml")
rels_xml = read(zpath,"word/_rels/document.xml.rels")
used = set(re.findall(r'(?:r:embed|r:link|r:id)="(rId[0-9]+)"', doc_xml))
rel_entries = re.findall(r'(<Relationship [^>]+/>)', rels_xml)
removed_files = set(); kept_xml=[]
for chunk in rel_entries:
attrs = dict(re.findall(r'(\w+)="([^"]+)"', chunk))
rid = attrs.get("Id"); tgt = attrs.get("Target","")
if tgt.startswith("media/") and rid not in used:
removed_files.add("word/"+tgt); continue
kept_xml.append(chunk)
new_rels = '<?xml version="1.0"?>\n<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">\n' + "\n".join(kept_xml) + "\n</Relationships>"
with zipfile.ZipFile(zpath,'r') as zin,
zipfile.ZipFile(out,'w',zipfile.ZIP_DEFLATED) as zout:
for item in zin.infolist():
if item.filename in removed_files: continue
data = zin.read(item.filename)
if item.filename == "word/_rels/document.xml.rels":
zout.writestr(item.filename, new_rels)
else:
zout.writestr(item, data)
print(f"[prune] used_rids={len(used)} removed_media={len(removed_files)} -> {out.name}")
def build_text_only(orig: Path, out: Path):
src = Document(orig)
dst = Document()
for p in src.paragraphs:
t = p.text.strip()
if t: dst.add_paragraph(t)
# 確保 sectPr 存在
if not any(el.tag == qn('w:sectPr') for el in dst.element.body):
dst.element.body.append(OxmlElement('w:sectPr'))
dst.save(out); print(f"[text-only] -> {out.name}")
def main():
if not SOURCE.exists():
print("source missing"); return
print("原始大小:", kb(SOURCE))
list_media(SOURCE)
used, image_rids = find_rids(SOURCE)
if not image_rids:
print("No images."); return
rid = next(iter(image_rids))
removed_para = OUT_DIR/"sample_removed_paragraph.docx"
prune_doc = OUT_DIR/"sample_pruned.docx"
txt_only = OUT_DIR/"sample_text_only.docx"
remove_paragraph_with_rid(SOURCE, rid, removed_para)
print("刪段落後大小:", kb(removed_para), "(vs 原始", kb(SOURCE), ")")
prune_unused_images(removed_para, prune_doc)
print("Prune 後大小:", kb(prune_doc))
build_text_only(SOURCE, txt_only)
print("純文字大小:", kb(txt_only))
print("\n== 對照 ==")
for p in [SOURCE, removed_para, prune_doc, txt_only]:
print(f"{p.name:30s} {kb(p)}")
if __name__ == "__main__":
main()使用 Python × lxml.etree
會比正則表示法好,
正則沒寫好會跨越兩個w:p (段落),導致多刪
若追求健壯性與可維護性,建議改用 XML 解析 + 樹操作
來處理 rels 與 used rId,
並擴大掃描範圍以涵蓋所有可能插圖來源。
🧷 為什麼刪段落只少 2.6 KB?
- 刪的是壓縮效率極佳的 XML 文字(顯示容器)
- 圖片仍完整保留(1008 KB)→ 占比 98% → 檔案幾乎不變
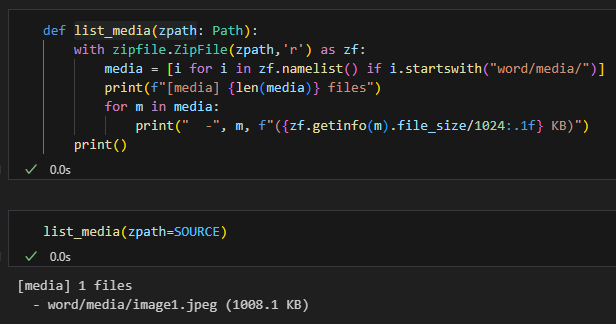
📉 為什麼 prune 後只剩 9.8 KB?
- 移除圖片檔 + relationship 標記
- 剩下的:文件骨架 (document.xml + styles + content types…)
- 這就是「真正瘦身」
🧱 為什麼純文字 docx 不是更小而是 35.8 KB?
- python-docx 仍會產出 styles.xml、fontTable、numbering、theme、rels、metadata
- 你保留了文字段落(多行),不追求極限壓縮
若要再縮:可手動刪除 theme1.xml、fontTable.xml、不必要樣式關係
(高風險,不建議除非做語料訓練)。
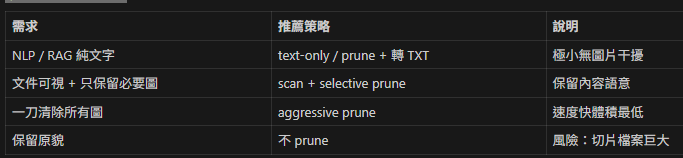
🧪 模式選擇指南
🧩 延伸:如何導出純文字供語料
def export_plain_text(docx_path: str, txt_path: str):
doc = Document(docx_path)
lines = []
for p in doc.paragraphs:
t = p.text.strip()
if t: lines.append(t)
Path(txt_path).write_text("\n".join(lines), encoding="utf-8")
# 使用
export_plain_text(r"D:\Temp\sample.docx", r"D:\Temp\sample.txt")✅ 總結重點一句話
圖片真正佔空間;段落只是引用。
要瘦,就要處理「Relationship + media 檔」,
不只是刪顯示段落。
推薦hahow線上學習python: https://igrape.net/30afN
讀取zip檔(docx):
from pathlib import Path
import zipfile
def read(zpath: Path, name: str):
"""
讀取 DOCX (其實是 ZIP) 容器內部指定成員的文字內容。
參數:
zpath: 外層 .docx 檔案路徑 (Path 或 str)。
name: ZIP 內部『相對路徑 / part 路徑』,必須與 ZipFile.namelist() 之一完全一致。
常見範例:
'[Content_Types].xml'
'_rels/.rels'
'word/document.xml'
'word/_rels/document.xml.rels'
'word/media/image1.jpeg'
'word/theme/theme1.xml'
'word/settings.xml'
'word/styles.xml'
'word/webSettings.xml'
'word/fontTable.xml'
'docProps/core.xml'
'docProps/app.xml'
說明:
- name 不是顯示名稱,而是壓縮包實際儲存的路徑字串 (folder + filename)。
- 在 OPC / DOCX 規範語境中,這是一個 package part 的位址。
- 若目標是媒體 (word/media/*) 等二進位,文字解碼會失真;請改用 read_bytes。
回傳:
UTF-8 (errors='ignore') 解碼後的文字內容。若原始是二進位資源,結果可能不正確。
"""
with zipfile.ZipFile(zpath, 'r') as zf:
return zf.read(name).decode('utf-8', 'ignore')
def read_bytes(zpath: Path, name: str) -> bytes:
"""
讀取 ZIP / DOCX 內部任意成員的原始 bytes(適用圖片、二進位資源)。
"""
with zipfile.ZipFile(zpath, 'r') as zf:
return zf.read(name)詳細講解這個函數 read(zpath: Path, name: str),不跳其他細節。
分 10 個面向:
用途 → 參數 → 流程 → 典型內部路徑 → 回傳值 → 失敗狀況 →
為什麼要 decode → ignore 的意義 → 擴充版本 → 實際對比。
用途 (一句話)
從一個 DOCX(其實是 ZIP)中讀取指定內部檔案的文字內容,回傳成 Python 字串。
參數意義
zpath: 外層壓縮檔路徑(Path 物件)。
例:Path(r”D:\Temp\sample.docx”)
name: 壓縮包裡的檔案路徑字串(相對路徑)。例:
正文 XML: “word/document.xml”
關係表: “word/_rels/document.xml.rels”
樣式: “word/styles.xml”
函數流程(逐行拆解)
with zipfile.ZipFile(zpath,'r') as zf:開啟一個 ZIP 讀取器(因為 .docx = ZIP)。zf 是 ZipFile 物件。
return zf.read(name).decode('utf-8','ignore')zf.read(name):讀內部檔案原始 bytes。
.decode(‘utf-8′,’ignore’):把 bytes 解碼成字串(把非 UTF-8 的錯誤位元組略過)。
回傳字串。
為什麼能讀 DOCX?
DOCX 本質 = ZIP 檔;
你手動改副檔名為 .zip 後解壓可以看到與 zf.namelist() 列出的內容完全一致。
因此 zipfile.ZipFile 可以直接操作它。
典型可用的 name 值(常見)
目的 name
正文段落內容 word/document.xml
圖片引用關係 word/_rels/document.xml.rels
樣式定義 word/styles.xml
編號定義 word/numbering.xml
主題 word/theme/theme1.xml
文件屬性 docProps/core.xml
應用屬性 docProps/app.xml
類型對照表 [Content_Types].xmlzf.namelist():
['[Content_Types].xml',
'_rels/.rels',
'word/document.xml',
'word/_rels/document.xml.rels',
'word/media/image1.jpeg',
'word/theme/theme1.xml',
'word/settings.xml',
'word/styles.xml',
'word/webSettings.xml',
'word/fontTable.xml',
'docProps/core.xml',
'docProps/app.xml']zf.namelist():
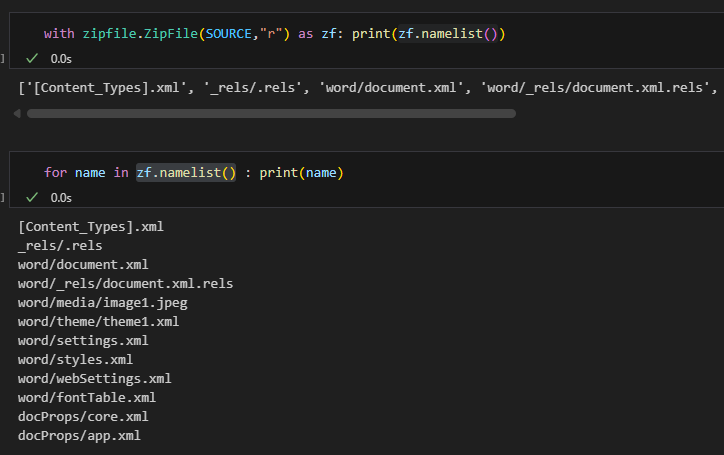
手動改副檔名為 .zip:
查看有哪些 name 可以用:
import zipfile
from pathlib import Path
with zipfile.ZipFile(Path(r"D:\Temp\sample.docx"), 'r') as zf:
for n in zf.namelist():
print(n)輸出:
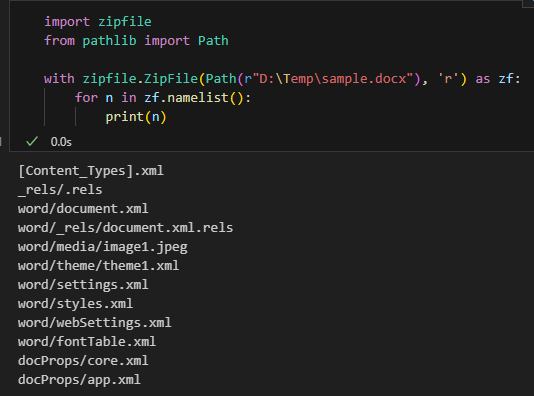
zf.namelist():
[Content_Types].xml
_rels/.rels
word/document.xml
word/_rels/document.xml.rels
word/media/image1.jpeg
word/theme/theme1.xml
word/settings.xml
word/styles.xml
word/webSettings.xml
word/fontTable.xml
docProps/core.xml
docProps/app.xml要記的最小記憶包
正文:word/document.xml
關係表:word/_rels/document.xml.rels
圖片檔:word/media/imageX.*
圖片引用: <a:blip r:embed="rIdX"> + <Relationship Id="rIdX" Target="media/...">
回傳值
成功:回傳指定內部檔案的文字內容(str)
失敗情況:
外部檔案不存在 → FileNotFoundError
指定 name 不存在 → KeyError
內容不是 UTF-8(例如圖片)→ decode 後變成奇怪符號或被忽略
為什麼 decode(‘utf-8′,’ignore’)
內部 XML 檔案都是 UTF-8 編碼;使用 decode 轉字串好操作(搜尋 rId、正則、解析 XML)。
加 ignore 是保底措施:遇到非 UTF-8 位元組(理論上不該在 XML 裡)不拋錯,直接略過。
若你讀圖片(JPEG/PNG),這種 decode 就不合適,應該改成讀 bytes。
ignore 的副作用
好處:不會因單一壞字節中斷流程。
風險:少數特殊標記被丟掉你不會發現。
若要更嚴謹:用 ‘strict’(預設)或 ‘replace’。
例:
zf.read(name).decode('utf-8','strict') # 有編碼錯誤就拋例外
zf.read(name).decode('utf-8','replace') # 用 � 佔位符顯示- 擴充版(加錯誤處理 & 二進位)
文字版(安全):
def read_text(zpath: Path, name: str, default: str = "") -> str:
try:
with zipfile.ZipFile(zpath,'r') as zf:
return zf.read(name).decode('utf-8','ignore')
except (FileNotFoundError, KeyError):
return default二進位版(讀圖片):
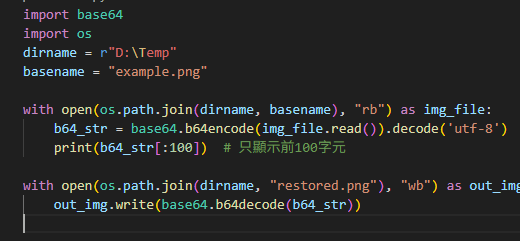
def read_bytes(zpath: Path, name: str) -> bytes:
with zipfile.ZipFile(zpath,'r') as zf:
return zf.read(name)實際對比示例(同一檔案兩種讀法)
from pathlib import Path
import zipfile
docx = Path(r"D:\Temp\sample.docx")
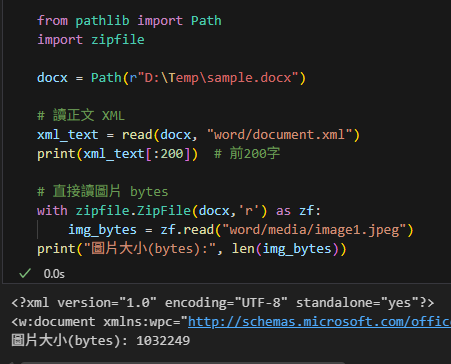
# 讀正文 XML
xml_text = read(docx, "word/document.xml")
print(xml_text[:200]) # 前200字
# 直接讀圖片 bytes
with zipfile.ZipFile(docx,'r') as zf:
img_bytes = zf.read("word/media/image1.jpeg")
print("圖片大小(bytes):", len(img_bytes))輸出:
這裡如果你嘗試:
bad = read(docx, "word/media/image1.jpeg")
print(bad[:200])會得到亂碼或空字串 —— 因為圖片不是 UTF-8 字元資料。
簡短總結
read(zpath, name) = 用 ZIP API 讀 DOCX 裡某個內部檔案 + 以 UTF-8 解碼為字串。zpath 指向外部 .docx;name 是壓縮包內部路徑,來源就是 zf.namelist() 或手動解壓後看到的檔名。
圖片/二進位資源不要用這個函式;用 bytes 版。
推薦hahow線上學習python: https://igrape.net/30afN
import re
from pathlib import Path
def find_rids(zpath: Path):
# 步驟 1:讀取正文 XML (word/document.xml)
# 與關係表 XML (word/_rels/document.xml.rels)
doc_xml = read(zpath, "word/document.xml")
rels_xml = read(zpath, "word/_rels/document.xml.rels")
# 步驟 2:在正文中找所有以 r:embed / r:link / r:id 屬性引用的 rId
# (圖片、外部連結、OLE、圖表等可能型態)
rid_pat = re.compile(r'(?:r:embed|r:link|r:id)="(rId[0-9]+)"')
used = set(rid_pat.findall(doc_xml))
# 正文內“實際被引用”的 rId 集合
# {'rId4'}
# 步驟 3:解析關係表,把每條 Relationship 的 (rId → Target 路徑) 建成映射
# 使用正則擷取 rId 與其 Target;此處採寬鬆匹配,僅為快速抽取,不檢查 Type
# 可使用更精準正則(如 [^>]* 取代 .+?)
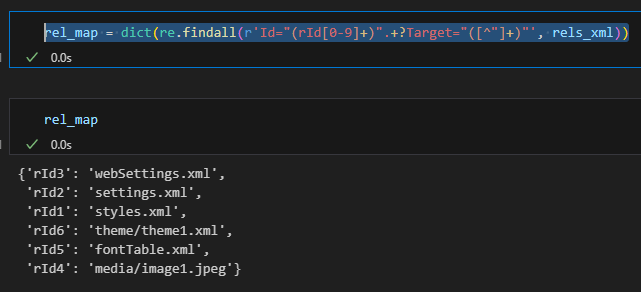
rel_map = dict(re.findall(r'Id="(rId[0-9]+)".+?Target="([^"]+)"', rels_xml))
"""
Type 過濾的核心:不要只靠 Target 路徑 media/ 判斷圖片,
而是讀 <Relationship ... Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image" ...> 的 Type 屬性,僅把 Type 末段是 image 的 rId 視為圖片;其它(styles、theme、fontTable 等)排除。
"""
# 步驟 4:過濾出目標路徑位於 media/ 下的關係 → 視為“圖片資源”
image_rids = {rid: tgt for rid, tgt in rel_map.items() if tgt.startswith("media/")}
# {'rId4': 'media/image1.jpeg'}
# 步驟 5:輸出摘要:顯示正文引用的 rId 集合,並列出所有圖片 rId 及是否被正文使用
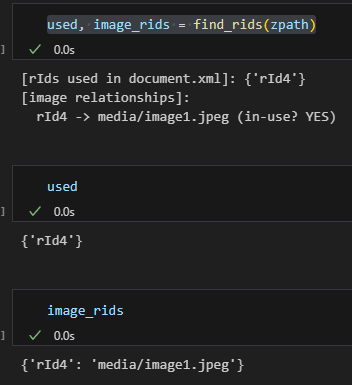
print("[rIds used in document.xml]:", used)
print("[image relationships]:")
for rid, tgt in image_rids.items():
# 若圖片 rId 出現在 used 集合 → 表示正文存在引用;否則為未使用圖片
print(f" {rid} -> {tgt} (in-use? {'YES' if rid in used else 'NO'})")
# 步驟 6:回傳:正文引用的 rId 集合 + 所有圖片 rId→路徑映射(後續可用來判斷刪除未用圖片)
return used, image_rids邏輯概述(純流程):
讀正文 XML 與關係表 XML。
從正文中擷取所有畫面/連結/通用引用的 rId 集合(used)。
從關係表擷取每條關係的 rId → 目標路徑映射(rel_map)。
篩選出目標路徑位於 media/ 下的條目(image_rids)。
對每個圖片 rId 標示是否出現在 used 集合(判斷是否被正文引用)。
輸出:正文引用的 rId 集合與所有圖片 rId→路徑;使用情況標記。
doc_xml ; rels_xml
r:embed | r:link | r:id
簡短結論
- r:embed:指向「內嵌」資源的關聯 ID(如內嵌在檔案裡的圖片)。
- r:link:指向「外部連結」資源的關聯 ID(通常是 URL,或外部檔案)。
- r:id:也是指向關聯的 ID,但用在其他元素/情境,不限於圖片。
它是通用的「relationships 參照屬性」名稱。
詳細說明
- 這些 r: 前綴屬性都來自 OOXML 的 Relationships 命名空間。值像 rId4、rId12 只是關聯的鍵,實際對應在同一部件的 _rels/*.rels 檔中。
- a:blip 元素中,常見的是 r:embed 或 r:link:
- r:embed=”rId4″ → 指向同一 .docx/.pptx 部件內的內嵌影像,例如 word/media/image1.png。
- r:link=”rId8″ → 指向外部資源(網址或外部檔案路徑)。
- r:id 通常出現在其他元素,例如:
- w:drawing、w:hyperlink、w:headerReference、w:footnoteReference、v:imagedata 等等,通用地表達「這個元素參照某個關聯 rIdX」。
- 在某些舊版或 VML 影像標記(如 v:imagedata)上會用 r:id 來連到圖片;而在 DrawingML 的 a:blip 上則規範為 r:embed / r:link。
from bs4 import BeautifulSoup
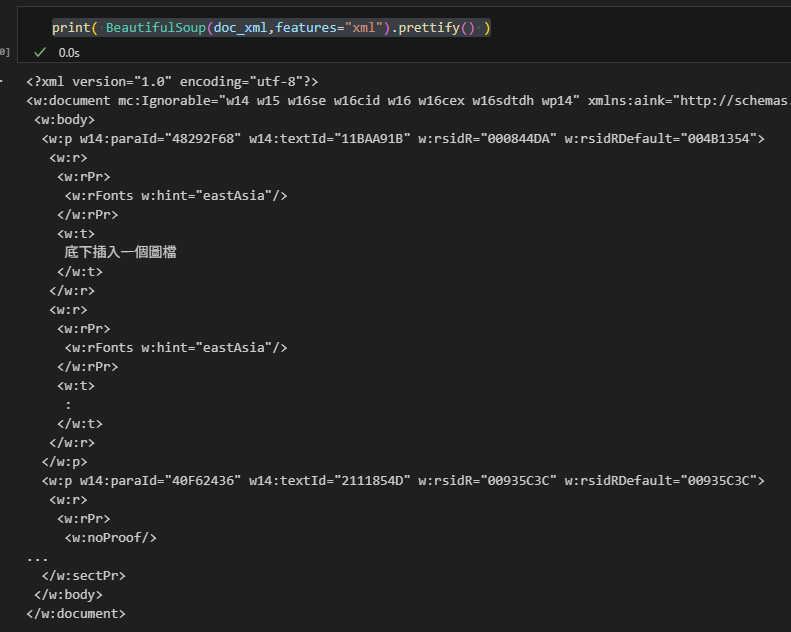
print( BeautifulSoup(doc_xml,features="xml").prettify() )
doc_xml = read(zpath,”word/document.xml“)
D:\Temp\sample.zip\word\document.xml
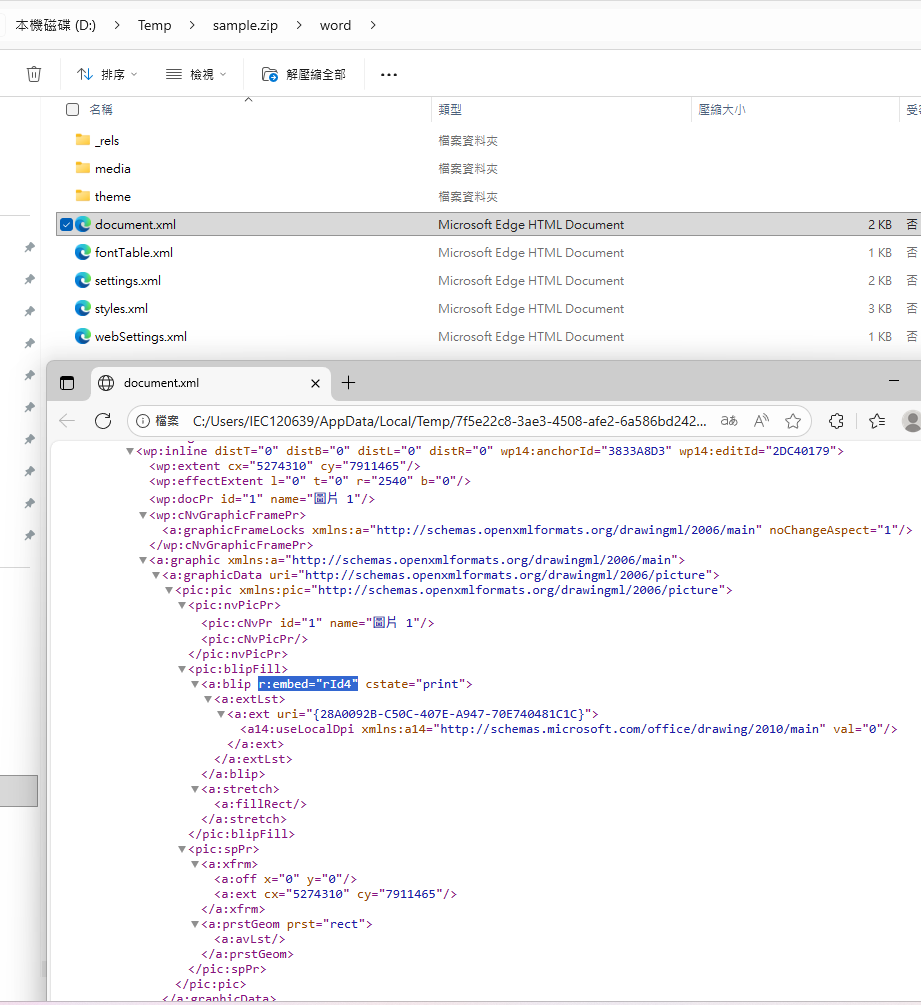
<a:blip cstate="print" r:embed="rId4">blip 的一般意思:
小亮點、短暫的訊號或異常(例如雷達螢幕上出現的一個小點)。
引申為「短暫的波動/插曲」。
是 DrawingML 規範裡的元素名稱,代表一個圖片資源的“引用”節點;
是規範中的技術詞。
它指向一個位圖或影像檔(Binary Large Image/Picture,有人把 blip 理解成
“Binary Large Image/Picture” 的簡寫,標準本身直接用 blip 當元素名)。
核心作用:
不存放圖片像素,只存關係引用(r:embed 或 r:link),以及少量附加屬性。
透過 r:embed=”rId4″ 到 .rels 查 rId4 → Target=media/image1.jpeg 才找到真正檔案。
如果是外部連結圖片,可能用 r:link=”rIdX”。
放在 或其他填充 (fill) 結構裡,作為形狀/圖片框的“填充來源”。
屬性說明:
r:embed=”rId4″:內嵌影像的關係 Id。
r:link=”rIdX”:外部連結(有時同時存在 embed + link)。
cstate=”print”:Compression state(影像壓縮品質狀態),
常見值:email、screen、print、hqprint;表示此影像用於列印品質。
流程概念:
Word 開啟 document.xml,看
去 document.xml.rels 找
載入影像顯示在文件中既定的圖框位置與尺寸。
為什麼要這層引用:
與 OPC (Open Packaging Conventions) 一致:
主 XML 不直接塞二進位,統一經由關係管理資源。
支援替換、快取、不同壓縮狀態,同一影像可以被多個圖形引用。
壓縮狀態 cstate 的意義(簡述):
email:較高壓縮,小尺寸。
screen:螢幕呈現最佳化。
print:列印品質平衡。
hqprint:高品質列印保留較高解析度。
a:blip …
可以理解為「這裡放一張圖片的引用」
D:\Temp\sample.zip\word\document.xml
部分內容:
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:cx="http://schemas.microsoft.com/office/drawing/2014/chartex" xmlns:cx1="http://schemas.microsoft.com/office/drawing/2015/9/8/chartex" xmlns:cx2="http://schemas.microsoft.com/office/drawing/2015/10/21/chartex" xmlns:cx3="http://schemas.microsoft.com/office/drawing/2016/5/9/chartex" xmlns:cx4="http://schemas.microsoft.com/office/drawing/2016/5/10/chartex" xmlns:cx5="http://schemas.microsoft.com/office/drawing/2016/5/11/chartex" xmlns:cx6="http://schemas.microsoft.com/office/drawing/2016/5/12/chartex" xmlns:cx7="http://schemas.microsoft.com/office/drawing/2016/5/13/chartex" xmlns:cx8="http://schemas.microsoft.com/office/drawing/2016/5/14/chartex" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:aink="http://schemas.microsoft.com/office/drawing/2016/ink" xmlns:am3d="http://schemas.microsoft.com/office/drawing/2017/model3d" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:w16cex="http://schemas.microsoft.com/office/word/2018/wordml/cex" xmlns:w16cid="http://schemas.microsoft.com/office/word/2016/wordml/cid" xmlns:w16="http://schemas.microsoft.com/office/word/2018/wordml" xmlns:w16sdtdh="http://schemas.microsoft.com/office/word/2020/wordml/sdtdatahash" xmlns:w16se="http://schemas.microsoft.com/office/word/2015/wordml/symex" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" mc:Ignorable="w14 w15 w16se w16cid w16 w16cex w16sdtdh wp14">
<w:body>
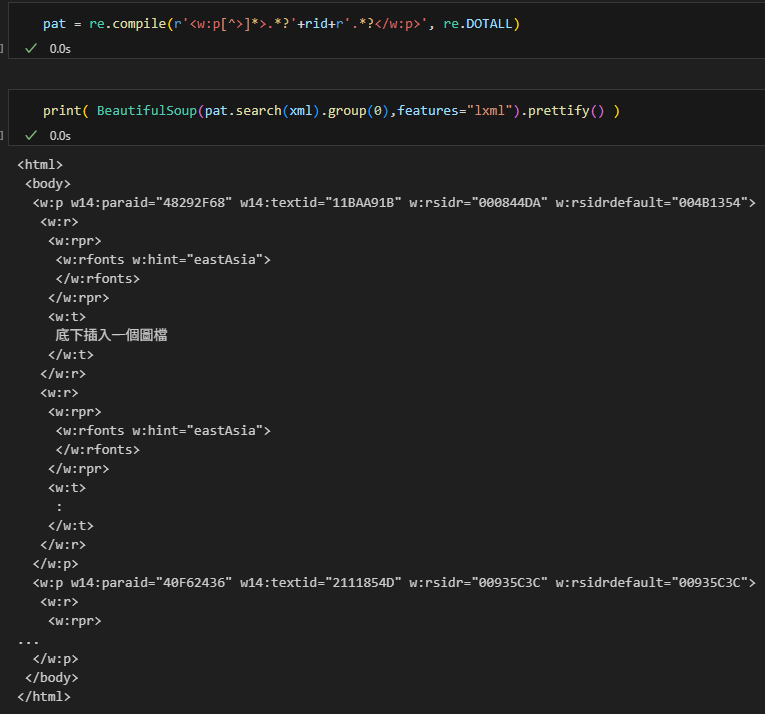
<w:p w14:paraId="48292F68" w14:textId="11BAA91B" w:rsidR="000844DA" w:rsidRDefault="004B1354">
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
<w:t>底下插入一個圖檔</w:t>
</w:r>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
<w:t>:</w:t>
</w:r>
</w:p>rels_xml = read(zpath,”word/_rels/document.xml.rels“)
D:\Temp\sample.zip\word\_rels\document.xml.rels
re.findall(r'Id="(rId[0-9]+)".+?Target="([^"]+)"', rels_xml)List[Tuple[str,str]]
rel_map = dict(re.findall(r'Id="(rId[0-9]+)".+?Target="([^"]+)"', rels_xml))
used, image_rids = find_rids(zpath)
推薦hahow線上學習python: https://igrape.net/30afN
re.sub 與 re.subn
rid #’rId4′
rid #’rId4′,第一段w:p 應該不匹配,
但是輸出的sample_removed.docx
連文字都刪除了,應該是正則有問題,多刪了
def remove_paragraph_with_rid(zpath: Path, rid: str, out: Path):
xml = read(zpath,"word/document.xml")
new_xml, n = re.compile(r'<w:p[^>]*>.*?'+rid+r'.*?</w:p>', re.DOTALL).subn('', xml, count=1)
with zipfile.ZipFile(zpath,'r') as zin, zipfile.ZipFile(out,'w',zipfile.ZIP_DEFLATED) as zout:
for item in zin.infolist():
data = zin.read(item.filename)
if item.filename == "word/document.xml":
zout.writestr(item.filename, new_xml if n else xml)
else:
zout.writestr(item, data)
print(f"[remove_paragraph] removed? {bool(n)} -> {out.name}")輸出:
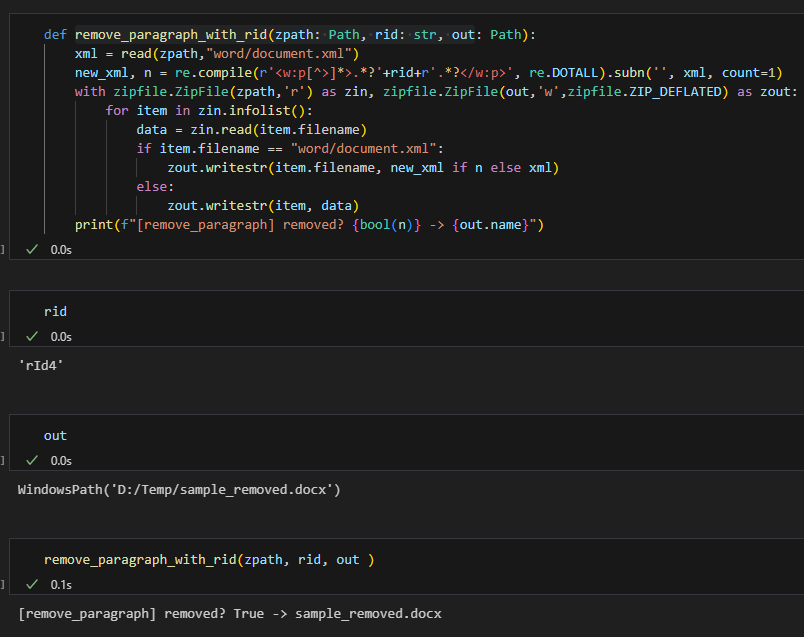
先整體概念一句話:這個函數打開原 DOCX(ZIP),
用正則在 word/document.xml 裡找第一個包含指定 rid 的段落 …,
刪掉後重新打包成新的 DOCX;其它檔案原樣複製。
下面分層詳細解說每一行在做什麼、潛在問題、改良方案。
逐行拆解
def remove_paragraph_with_rid(zpath: Path, rid: str, out: Path):
參數
zpath: 原始 DOCX 路徑(ZIP 格式)。
rid: 你想移除的關聯 ID,例如 rId12,期望這個 rId 出現在某段落的 XML 裡。
out: 新輸出的 DOCX 路徑。
類型標註用於提示與靜態分析,不影響執行。
xml = read(zpath,”word/document.xml”)
讀出整個 word/document.xml 的文字(整份主體 XML)。
這一步把整份 XML 放進記憶體;大文件會佔用 RAM,但一般可以接受。
new_xml, n = re.compile(r’]>.?’+rid+r’.*?’, re.DOTALL).subn(”, xml, count=1)
建立正則模式:
r’]>.?’+rid+r’.?’ ]>:匹配段落開始標籤 (屬性部分用 [^>]* 允許任意)。 .?:懶惰匹配任意字元(不含換行,因為預設 . 不吃 \n),但後面加了 re.DOTALL → 會吃換行。 rid:直接串接輸入的 rId(如 rId12)。 .?:再抓到段落結束前剩餘內容。 :段落結尾。
問題 / 風險:
沒做 re.escape(rid):若 rid 未來包含特殊正則字符(理論上 rId 不會,但泛用時要保護)。
可能跨越多個段落:如果某個段落起始後一直沒遇到 rid,懶惰 .? 會往後找,
直到第一個 rid,再繼續到第一個 ;通常 OK,但若 XML 結構不規則可能吞掉意料以外範圍。
沒限定 rid 必須作為屬性或 r:embed 值,
只要字串出現就刪,容易誤刪(例如文字內容包含同樣字串)。
使用xml-etree會更穩健
re.DOTALL:讓 .? 包括換行,確保跨行匹配。
.subn(”, xml, count=1):替換第一個匹配段為空字串(刪除)。
回傳 (new_string, replacement_count) → 解包成 new_xml, n。
n 為 0 或 1。若沒有找到,new_xml 就是原文。
with zipfile.ZipFile(zpath,’r’) as zin, zipfile.ZipFile(out,’w’,zipfile.ZIP_DEFLATED) as zout:
同時打開來源 ZIP(讀)與目的 ZIP(寫)。
新 ZIP 使用 DEFLATED 壓縮。
for item in zin.infolist():
遍歷來源 ZIP 中每個檔案的 ZipInfo。
data = zin.read(item.filename)
將該檔案完整讀入記憶體(若檔案很大,可能要改成串流方式)。
if item.filename == “word/document.xml”:
只對主體文件做替換,其它全複製。
zout.writestr(item.filename, new_xml if n else xml)
若成功刪除(n==1),寫入修改後的 XML;否則原樣寫回。
注意:使用 writestr(name, data) 會新建一個 ZipInfo(不保留原壓縮屬性/日期);如果你想保留 metadata,應該用 writestr(item, data)。這裡 document.xml 用的是 filename(失去原日期),其他用的是 item(保留 metadata)—有微妙不一致。
else: zout.writestr(item, data)
其它檔案原樣寫入。
print(f”[remove_paragraph] removed? {bool(n)} -> {out.name}”)
紀錄是否有刪除成功(True/False),以及新檔名稱。
bool(n) 只代表至少有一個匹配(實際只會 0 或 1)。
print 那行的解釋
print(f”[remove_paragraph] removed? {bool(n)} -> {out.name}”)
bool(n):顯示是否找到並刪除第一段。n 是替換次數(0 或 1)。
out.name:輸出檔案的檔名(不含路徑)。
推薦hahow線上學習python: https://igrape.net/30afN
")

 ; plt.subplots_adjust( hspace=1 ) 調整子圖間的間距")


 ) ;雙層column name的DF與Series或單層column name的DF做橫向(axis=1)合併會如何? 雙層column name被壓縮成單層的tuple")
")

 客戶端:Azure、OpenAI 與 Poe 整合指南")

近期留言