#Python撲克牌的4種花色,撲克牌洗牌_2
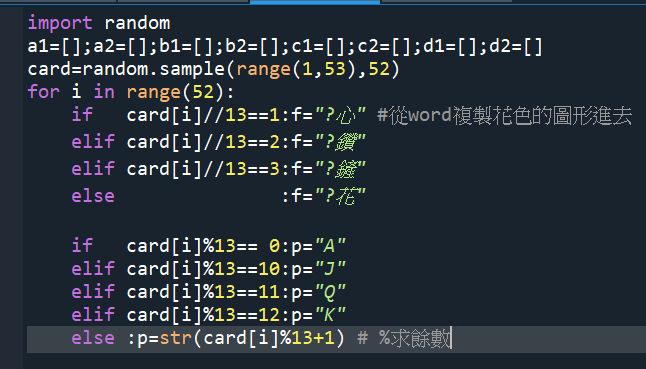
import random
a1=[];a2=[];b1=[];b2=[];c1=[];c2=[];d1=[];d2=[]
card=random.sample(range(1,53),52)
for i in range(52):
if card[i]//13==1:f=”?心” #從word複製花色的圖形進去
elif card[i]//13==2:f=”?鑽”
elif card[i]//13==3:f=”?鏟”
else :f=”?花”
if card[i]%13== 0:p=”A”
elif card[i]%13==10:p=”J”
elif card[i]%13==11:p=”Q”
elif card[i]%13==12:p=”K”
else :p=str(card[i]%13+1) # %求餘數
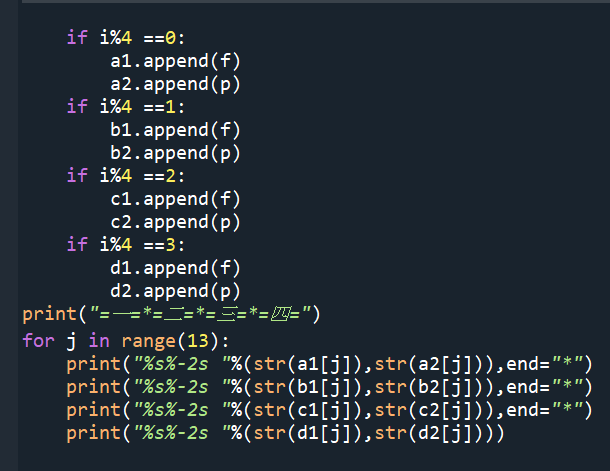
if i%4 ==0:
a1.append(f)
a2.append(p)
if i%4 ==1:
b1.append(f)
b2.append(p)
if i%4 ==2:
c1.append(f)
c2.append(p)
if i%4 ==3:
d1.append(f)
d2.append(p)
print(“=一=*=二=*=三=*=四=”)
for j in range(13):
print(“%s%-2s “%(str(a1[j]),str(a2[j])),end=”*”)
print(“%s%-2s “%(str(b1[j]),str(b2[j])),end=”*”)
print(“%s%-2s “%(str(c1[j]),str(c2[j])),end=”*”)
print(“%s%-2s “%(str(d1[j]),str(d2[j])))
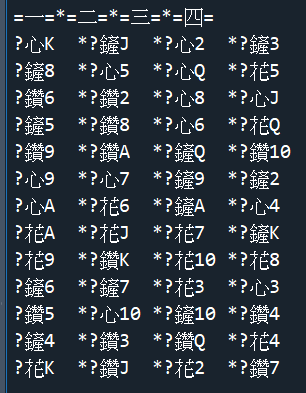
輸出結果:
![Python TQC 510 費氏數列,list[], f.append(n3)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220522152013_66.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC 510 費氏數列,list[], f.append(n3)")

 ; qn(‘w:tbl’) ; qn(‘w:sectPr’)")
 與 os.stat() 讀懂檔案資訊; from pathlib import Path ; type(p).__name__ #’WindowsPath’; p.stat().st_size == os.stat(p).st_size == os.path.getsize(p)")
")
![Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列?](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313160116_63.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列?")
")
![Python如何寫入docx文件? from docx import Document ; doc = Document() ; table = doc.add_table(rows=5, cols=3) ; table.cell(r,c).text = str(tabs[r][c]) ; doc.add_heading ; p = doc.add_paragraph ; p.add_run ; doc.add_picture ; 使用wordPad開啟會少最後一個row,可以用免費的LibreOffice](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220914154313_30.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何寫入docx文件? from docx import Document ; doc = Document() ; table = doc.add_table(rows=5, cols=3) ; table.cell(r,c).text = str(tabs[r][c]) ; doc.add_heading ; p = doc.add_paragraph ; p.add_run ; doc.add_picture ; 使用wordPad開啟會少最後一個row,可以用免費的LibreOffice")
; self.radius=1")


近期留言