在做檔案搜尋或文字檢索時,
最怕使用者明明輸入了關鍵字,
系統卻回傳「找不到」。
這通常是因為斷詞斷得「太乾淨」,
導致長詞無法匹配短查詢。
Jieba 提供了專用的
**`lcut_for_search` (搜尋引擎模式)**
來解決這個問題。
## 1. 核心差異:精確模式 vs 搜尋引擎模式

## 2. 實測比較 (關鍵差異!)
**⚠️ 注意:Jieba 對「簡體中文」的拆解能力遠強於繁體!**
如果您使用繁體中文測試,
可能會發現 `lcut` 和 `lcut_for_search` 結果一樣,
這是因為 Jieba 預設詞庫對繁體長詞的支援度較低。
### 測試案例 A:簡體中文 (完美展示)
text = "小明硕士毕业于中国科学院计算所"
# 1. 精確模式
print(jieba.lcut(text))
# 結果: ['小明', '硕士', '毕业', '于', '中国科学院', '计算所']
# ❌ [缺陷] "中国科学院" 是一整塊,搜 "学院" 會找不到。
# 2. 搜尋引擎模式
print(jieba.lcut_for_search(text))
# 結果: ['小明', '硕士', '毕业', '于', '中国', '科学', '学院', '科学院', '中国科学院', '计算', '计算所']
# ✅ [優勢] 炸開了!搜 "科学"、"学院" 都能找到。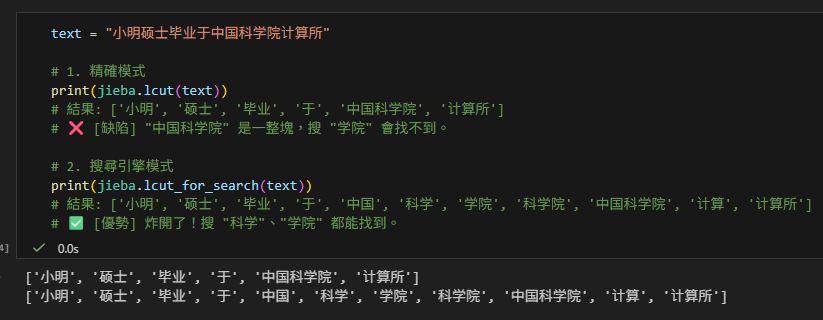
### 測試案例 B:繁體中文 (Jieba 的弱點)
text = "小明碩士畢業於中國科學院計算所"
# 搜尋引擎模式
print(jieba.lcut_for_search(text))
# 結果: ['小明', '碩士', '畢業', '於', '中國', '科學院', '計算', '所']
# ⚠️ [問題] "科學院" 沒有被拆成 "科學" + "學院"。
# 因為 Jieba 詞庫裡可能沒有 "科學院" 這個複合詞的細部定義。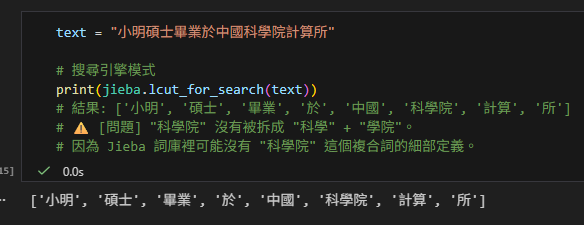
## 3. 工程上的解決方案
因為上述特性,為了追求最高的**搜尋召回率 (Recall)**,
我們在處理搜尋引擎時,常會採用 **「內部簡體化」** 策略:
1. **索引階段**:利用 OpenCC (`t2s`) 將所有繁體檔名轉為**簡體**,
再丟給 Jieba 切分。這樣能獲得最細緻的 Token。
2. **查詢階段**:將使用者的搜尋詞也轉為**簡體**,再進去比對。
3. **顯示階段**:回傳原始檔案路徑 (保留繁體)。
這樣既能利用 Jieba 強大的簡體分詞能力,
又能讓使用者用繁體關鍵字搜尋。
## 4. 為什麼搜尋引擎需要它?
### 解決「長詞遮蔽」問題
在精確模式下(BM25搜尋引擎是比對
Token 是否完全相等,而非部分字串包含),
長詞(如 `IEC-Diagnostic-Tools`)會被視為一個獨立的 Token。
如果使用者只搜尋 `Diagnostic`,BM25的比對方法會失敗
(因為 `Diagnostic` 不等於 `IEC-Diagnostic-Tools`)。
`lcut_for_search` 會將長詞「暴力拆解」成多種組合,
確保**無論搜長搜短,都能命中**。
## 4. 權衡:召回率 (Recall) vs 分數稀釋 (Dilution)
使用 `lcut_for_search` 雖然能提高召回率(讓更多檔案被找到),
但也伴隨著一個副作用:**分數稀釋**。
* **分母變大**:因為切出來的詞變多了(文件長度變長),
在 BM25 等演算法中,會判定這篇文章內容較「雜」。
* **權重分散**:單一關鍵字的得分貢獻會稍微降低。
**結論**:
在搜尋系統中,**「找不到」(Recall=0)** 是最嚴重的UX問題。
因此,我們寧願接受分數稍微被稀釋,
也要確保使用者能找到目標檔案。
這就是為什麼我們在 `bm25_search_optimized.py` 中
選擇使用 `lcut_for_search` 的原因。
推薦hahow線上學習python: https://igrape.net/30afN
![Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220901154435_19.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()")
 和 add_paragraph() 都創建段落,有何差別?")

 ; 那些參數可以設為None?")
 ; X_poly = poly.fit_transform(X)")
![Python 如何做excel的樞紐分析? pandas.DataFrame.groupby() ; .agg( {column name: function name} ) ; 如何讀取多層index的xlsx檔案? df = pandas.read_excel (fpath, index_col =[0,1]) ; 如何顯示所有欄? pd.set_option ( “display.max_columns”, None)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230321113121_64.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何做excel的樞紐分析? pandas.DataFrame.groupby() ; .agg( {column name: function name} ) ; 如何讀取多層index的xlsx檔案? df = pandas.read_excel (fpath, index_col =[0,1]) ; 如何顯示所有欄? pd.set_option ( “display.max_columns”, None)")




![使用 Python 檢驗字符串格式:掌握正則表達式(Regular Expression)的起始^與終止$符號, pattern = r'^GATR[0-9]{4}$' - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/07/20240712093637_0-520x245.png)

近期留言