本篇為前篇的衍伸
詳細可以先看前篇
if~ else~ 一行式寫法:func = lambda strr: 1 if strr == "Yes" else 0
epochs只設200
未均一化資料:
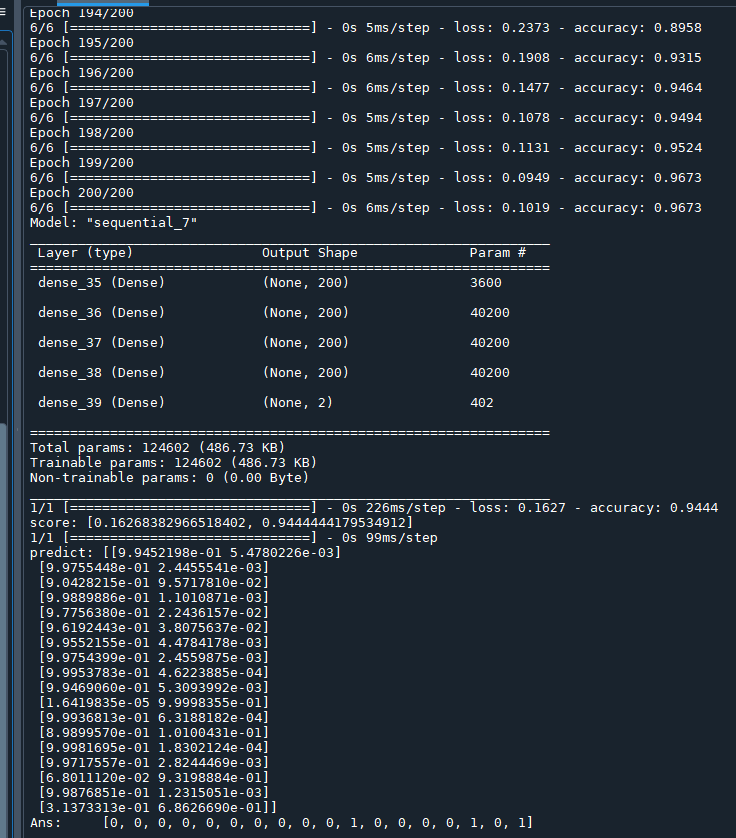
未均一化資料
準確度為0.9444 (score)
均一化資料後
準確度達1.0
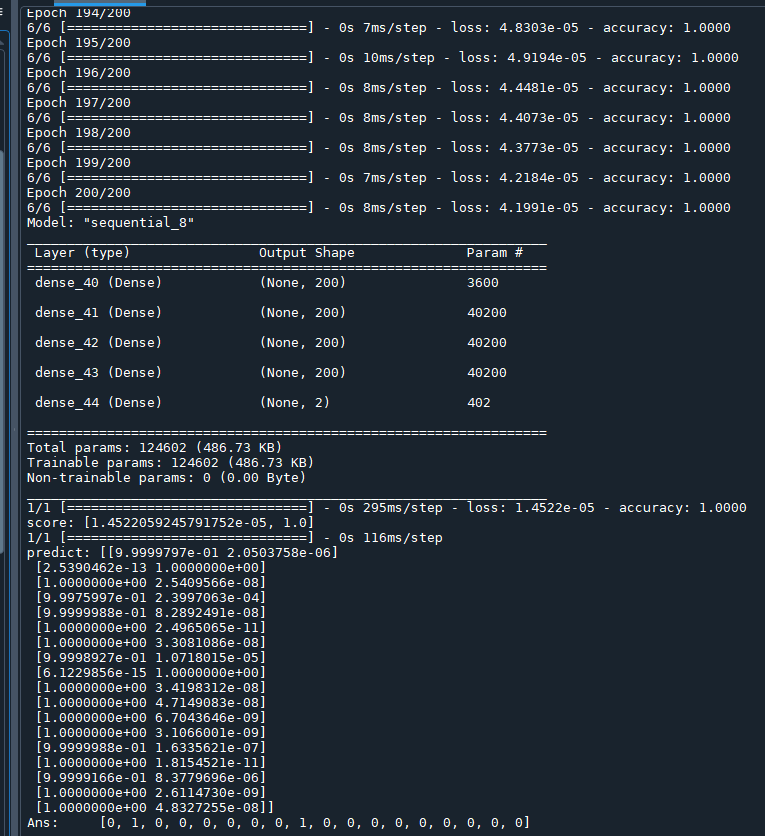
均一化的code:
lis_col = df_dp.columns.to_list()
for col in lis_col:
max_value = df_dp[col].max()
ratio = 1/max_value
df_dp[col] = df_dp[col]*ratio其實歸一化不是這樣做
除非最小值剛好是0
正確做法可以參考這裡:

完整code:
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 12 15:27:56 2023
@author: SavingKing
"""
import os
import pandas as pd
import numpy as np
dirname = r"P:\Python class\powen\AI人工智慧自然語言與語音語意辨識開發應用實務班\powen2_AI人工智慧自然語言與語音語意辨識開發應用實務班\day6\ch07-MLP-flower"
basename = "weather.csv"
fpath = os.path.join(dirname,basename)
#'C:\\Users\\SavingKing\\Downloads\\day6\\ch07-MLP-flower\\weather.csv'
df = pd.read_csv(fpath)
func = lambda strr: 1 if strr == "Yes" else 0
df["RainTomorrow_01"] = df["RainTomorrow"].apply( func )
lis_drop_col = ["WindGustDir", "WindDir9am","WindDir3pm","RainToday","RainTomorrow"]
#非數值資料的欄位先drop,只留下數值資料的欄位
#WindSpeed9am 資料含有NA
df_dp = df.drop(columns = lis_drop_col)
#[366 rows x 18 columns]
#資料中含有NA,需要先dropna做資料清洗,不然loss, predict會出現nan
df_dp.dropna(axis=0, how='any', subset=None, inplace=True)
#[354 rows x 18 columns]
lis_col = df_dp.columns.to_list()
for col in lis_col:
max_value = df_dp[col].max()
ratio = 1/max_value
df_dp[col] = df_dp[col]*ratio
X = df_dp.drop(columns="RainTomorrow_01").values
#[366 rows x 17 columns]
Y = df_dp.iloc[:,-1].values
#pandas.core.series.Series
"""
X.shape
Out[61]: (366, 17)
Y.shape
Out[62]: (366,)
"""
from sklearn.model_selection import train_test_split
import tensorflow as tf
category=2 #下雨/不下雨 分別用1 0 代表, 兩種結果
dim=X.shape[1] #有幾個特徵值?
x_train , x_test , y_train , y_test = train_test_split(X,Y,test_size=0.05)
y_train2=tf.keras.utils.to_categorical(y_train, num_classes=(category))
y_test2=tf.keras.utils.to_categorical(y_test, num_classes=(category))
#One-hot Encoding 單熱編碼
#y_train y_test 都是一維的資料
print("x_train[:4]",x_train[:4])
print("y_train[:4]",y_train[:4])
print("y_train2[:4]",y_train2[:4])
# 建立模型
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu,
input_dim=dim)) #input_dim 有幾個特徵值不能錯
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu ))
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu ))
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu ))
model.add(tf.keras.layers.Dense(units=category,
activation=tf.nn.softmax )) #最後一層units=category也不能錯
model.compile(optimizer='adam',
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(x_train, y_train2,
epochs=200,
batch_size=64)
#測試
model.summary()
score = model.evaluate(x_test, y_test2)
print("score:",score)
predict = model.predict(x_test)
print("predict:",predict)
lis_ans = [np.argmax(predict[i]) for i in range(predict.shape[0]) ]
print("Ans:\t",lis_ans)
# print("Ans:",np.argmax(predict[0]),np.argmax(predict[1]),np.argmax(predict[2]),np.argmax(predict[3]))
# =============================================================================
# predict2 = model.predict_classes(x_test)
# print("predict_classes:",predict2)
# print("y_test",y_test[:])
# =============================================================================資料清洗(dropna)
以及均一化
都滿有幫助
推薦hahow線上學習python: https://igrape.net/30afN
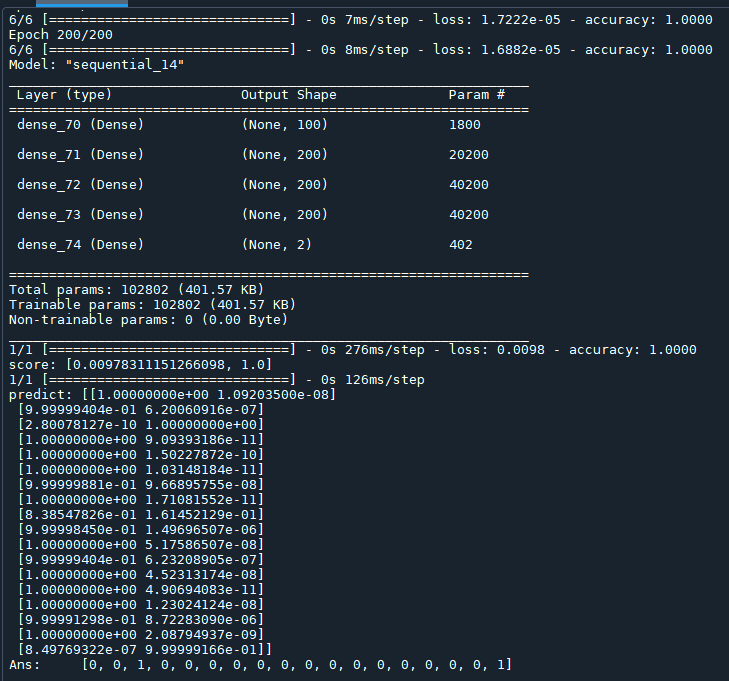
正確的均一化:
lis_col = df_dp.columns.to_list()
for col in lis_col:
max_value = df_dp[col].max()
min_value = df_dp[col].min()
rng = max_value-min_value
df_dp[col] = (df_dp[col]-min_value)/rng
df_dp.to_excel("./df_dp.xlsx")df_dp.xlsx 部分內容(數值都在0~1):
| MinTemp | MaxTemp | Rainfall | Evaporation | Sunshine | WindGustSpeed | WindSpeed9am | WindSpeed3pm | Humidity9am | Humidity3pm | Pressure9am | Pressure3pm | Cloud9am | Cloud3pm | Temp9am | Temp3pm | RISK_MM | RainTomorrow_01 | |
| 0 | 0.50763358778626 | 0.592198581560284 | 0 | 0.235294117647059 | 0.463235294117647 | 0.2 | 0.146341463414634 | 0.384615384615385 | 0.507936507936508 | 0.192771084337349 | 0.591836734693878 | 0.5 | 0.875 | 0.875 | 0.58130081300813 | 0.629251700680272 | 0.0904522613065327 | 1 |
| 1 | 0.736641221374046 | 0.684397163120567 | 0.0904522613065327 | 0.308823529411765 | 0.713235294117647 | 0.305882352941177 | 0.0975609756097561 | 0.326923076923077 | 0.698412698412698 | 0.27710843373494 | 0.405612244897958 | 0.318681318681319 | 0.625 | 0.375 | 0.707317073170732 | 0.700680272108844 | 0.0904522613065327 | 1 |
| 2 | 0.725190839694657 | 0.560283687943262 | 0.0904522613065327 | 0.411764705882353 | 0.242647058823529 | 0.847058823529412 | 0.146341463414634 | 0.115384615384615 | 0.73015873015873 | 0.674698795180723 | 0.331632653061224 | 0.285714285714288 | 1 | 0.875 | 0.621951219512195 | 0.513605442176871 | 1 | 1 |
| 3 | 0.709923664122138 | 0.280141843971631 | 1 | 0.514705882352941 | 0.669117647058824 | 0.482352941176471 | 0.731707317073171 | 0.461538461538462 | 0.412698412698413 | 0.518072289156627 | 0.229591836734694 | 0.280219780219781 | 0.25 | 0.875 | 0.544715447154472 | 0.306122448979592 | 0.0703517587939699 | 1 |
| 4 | 0.49236641221374 | 0.301418439716312 | 0.0703517587939699 | 0.397058823529412 | 0.779411764705882 | 0.435294117647059 | 0.487804878048781 | 0.538461538461538 | 0.507936507936508 | 0.433734939759036 | 0.55612244897959 | 0.596153846153846 | 0.875 | 0.875 | 0.447154471544716 | 0.350340136054422 | 0 | 0 |
| 5 | 0.438931297709924 | 0.329787234042553 | 0 | 0.411764705882353 | 0.602941176470588 | 0.364705882352941 | 0.487804878048781 | 0.461538461538462 | 0.53968253968254 | 0.530120481927711 | 0.69642857142857 | 0.684065934065935 | 0.875 | 0.625 | 0.439024390243903 | 0.329931972789116 | 0.0050251256281407 | 0 |
| 6 | 0.435114503816794 | 0.375886524822695 | 0.0050251256281407 | 0.294117647058824 | 0.617647058823529 | 0.352941176470588 | 0.463414634146342 | 0.5 | 0.428571428571429 | 0.409638554216868 | 0.716836734693874 | 0.697802197802199 | 0.5 | 0.75 | 0.5 | 0.414965986394558 | 0 | 0 |
| 7 | 0.519083969465649 | 0.333333333333333 | 0 | 0.397058823529412 | 0.338235294117647 | 0.329411764705882 | 0.268292682926829 | 0.461538461538462 | 0.46031746031746 | 0.530120481927711 | 0.75765306122449 | 0.752747252747253 | 0.75 | 0.875 | 0.487804878048781 | 0.35374149659864 | 0 | 0 |
| 8 | 0.538167938931298 | 0.421985815602837 | 0 | 0.279411764705882 | 0.301470588235294 | 0.411764705882353 | 0.463414634146342 | 0.326923076923077 | 0.53968253968254 | 0.421686746987952 | 0.755102040816323 | 0.711538461538462 | 0.875 | 0.875 | 0.569105691056911 | 0.469387755102041 | 0.407035175879397 | 1 |
| 9 | 0.522900763358779 | 0.539007092198582 | 0.407035175879397 | 0.382352941176471 | 0.566176470588235 | 0.211764705882353 | 0.170731707317073 | 0.115384615384615 | 0.73015873015873 | 0.228915662650602 | 0.704081632653058 | 0.656593406593408 | 0.875 | 0.125 | 0.536585365853659 | 0.564625850340136 | 0 | 0 |
| 10 | 0.549618320610687 | 0.624113475177305 | 0 | 0.294117647058824 | 0.875 | 0.2 | 0.146341463414634 | 0.173076923076923 | 0.603174603174603 | 0.253012048192771 | 0.711734693877553 | 0.667582417582418 | 0.125 | 0.25 | 0.589430894308943 | 0.642857142857143 | 0.0050251256281407 | 0 |
| 11 | 0.526717557251908 | 0.698581560283688 | 0.0050251256281407 | 0.514705882352941 | 0.919117647058824 | 0.329411764705882 | 0.0487804878048781 | 0.288461538461538 | 0.285714285714286 | 0.265060240963855 | 0.69642857142857 | 0.634615384615384 | 0 | 0.375 | 0.678861788617886 | 0.710884353741497 | 0 | 0 |
| 12 | 0.587786259541985 | 0.719858156028369 | 0 | 0.514705882352941 | 0.955882352941177 | 0.2 | 0.146341463414634 | 0.134615384615385 | 0.412698412698413 | 0.192771084337349 | 0.650510204081632 | 0.557692307692308 | 0 | 0.125 | 0.686991869918699 | 0.748299319727891 | 0 | 0 |
| 13 | 0.66412213740458 | 0.826241134751773 | 0 | 0.441176470588235 | 0.911764705882353 | 0.364705882352941 | 0.170731707317073 | 0.384615384615385 | 0.492063492063492 | 0.0843373493975904 | 0.530612244897957 | 0.447802197802199 | 0.125 | 0.5 | 0.796747967479675 | 0.870748299319728 | 0 | 0 |
| 14 | 0.587786259541985 | 0.836879432624114 | 0 | 0.632352941176471 | 0.963235294117647 | 0.329411764705882 | 0.146341463414634 | 0.384615384615385 | 0.142857142857143 | 0.036144578313253 | 0.553571428571429 | 0.464285714285716 | 0 | 0.125 | 0.75609756097561 | 0.860544217687075 | 0 | 0 |
| 15 | 0.675572519083969 | 0.868794326241135 | 0 | 0.602941176470588 | 0.816176470588235 | 0.388235294117647 | 0.170731707317073 | 0.173076923076923 | 0.53968253968254 | 0.108433734939759 | 0.545918367346938 | 0.439560439560438 | 0 | 0.375 | 0.772357723577236 | 0.870748299319728 | 0 | 0 |
執行結果(準確度1.0):
推薦hahow線上學習python: https://igrape.net/30afN
 & Spyder 如何切換不同版本的Python直譯器( Interpreter ), VS code: 齒輪>命令選擇區(Ctrl + Shift +P) > Python: Select Interpreter #Spyder console: !where python #知道自己安裝的python路徑")
![Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/04/20230418154049_50.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask")
 ; 如何將資料夾中的多個csv檔求平均?")
 駝峰切詞與特例保護教學; (?i: … ):不分大小寫的非捕獲群組")



 方法處理鍵不存在的情況; apple_count = my_dict .get( ‘apple’ , 0) # 如果鍵存在,返回對應的值,否則返回預設值 0")
")
![Python: 如何創建多層column name的pandas.DataFrame? df = pd.read_csv ('data.csv', header=[0, 1], sep=",") ; col = pd .MultiIndex .from_arrays( aryCol ) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230314164119_32-520x245.png)


近期留言