BM25 (Best Matching 25) 是現代搜尋引擎的核心演算法。
比起單純的關鍵字匹配 (True/False),
它能計算出一個「相關性分數」,
告訴你哪份文件最符合使用者的需求。
本教學將帶你從安裝套件開始,
用 30 行程式碼寫出一個高品質的搜尋引擎。
## 1. 環境準備
首先,我們需要安裝計算 BM25 分數的套件 `rank-bm25`,
以及中文斷詞神器 `jieba`。
pip install rank-bm25 jieba## 2. 準備假資料 (The Corpus)
假設我們有一堆技術文件或產品清單,
這就是我們的**語料庫 (Corpus)**。
import jieba
from rank_bm25 import BM25Okapi
# 這是我們的 "資料庫"
corpus = [
"DeepSeek OCR 開源文字辨識模型效能超越 Gemini",
"Python 爬蟲教學:如何使用 requests 抓取網頁",
"OpenCC 繁簡轉換工具使用指南",
"Jieba 斷詞引擎:精確模式與搜尋模式的差異",
"如何使用 BM25 演算法打造高效搜尋系統"
]
print(f"📚 資料庫共有 {len(corpus)} 篇文章")## 3. 預處理:斷詞 (Tokenization)
搜尋引擎看不懂整句中文,
我們必須把句子切成「詞 (Tokens)」。
# 把每一句話切成 list of words
tokenized_corpus = []
for doc in corpus:
# 使用 lcut_for_search 引擎模式,增加召回率
tokens = jieba.lcut_for_search(doc)
tokenized_corpus.append(tokens)
# 看看切得如何 (顯示第一篇)
print(f"🔍 範例 Token: {tokenized_corpus[0]}")
# 預期輸出: ['DeepSeek', ' ', 'OCR', ' ', '開源', '文字', '辨識', '模型', '效能', '超越', 'Gemini']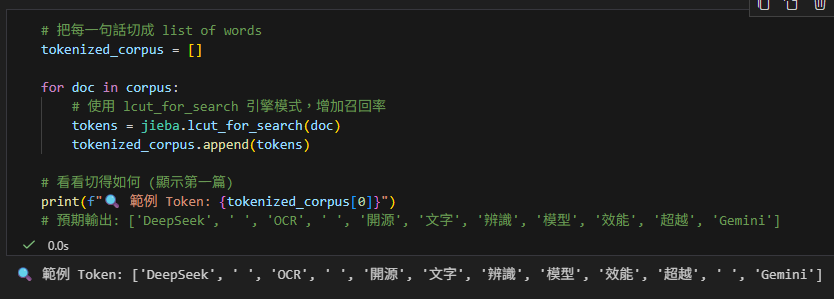
## 4. 建立索引 (Indexing)
這是最神奇的一步。我們將切好的詞餵給 `BM25Okapi`。
**注意:** BM25Okapi 要求的輸入格式必須是
**List of List of Strings** (`List[List[str]]`)。
# %%
# 結構示意:
# [
# ['DeepSeek', 'OCR', ...], # 第一篇文章的詞
# ['Python', '爬蟲', ...] # 第二篇文章的詞
# ]
bm25 = BM25Okapi(tokenized_corpus)
print("✅ BM25 索引建立完成!")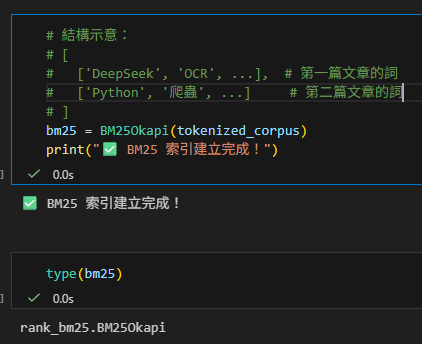
## 5. 開始搜尋!
現在我們來模擬使用者搜尋。
關鍵步驟是對使用者的查詢 (Query) 做
**一模一樣的斷詞處理**。
query = "搜尋引擎教學"
# 1. 對查詢斷詞
tokenized_query = jieba.lcut_for_search(query)
print(f"👉 使用者搜尋: {tokenized_query}")
# 2. 讓 BM25 幫每篇文章打分數
# doc_scores 是一個長度為 5 的 array (對應 corpus 的文章數量),記著每篇文章的得分
doc_scores = bm25.get_scores(tokenized_query)
# array([0. , 1.05543539, 0. , 2.11087077, 0. ])
# 3. 雖然可以直接看分數,但我們通常想看「排名最好的前 N 名」
# get_top_n 可以直接幫我們找出來
top_n = bm25.get_top_n(tokenized_query, corpus, n=3)
print("\n🏆 搜尋結果前 3 名:")
for i, doc in enumerate(top_n, 1):
print(f"第 {i} 名: {doc}")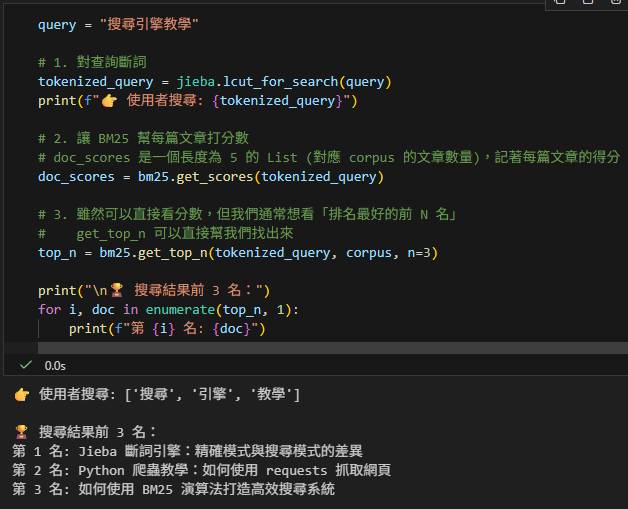
## 完整程式碼範例
import jieba
from rank_bm25 import BM25Okapi
# 1. 資料
documents = [
"DeepSeek OCR 開源文字辨識模型效能超越 Gemini",
"Python 爬蟲教學:如何使用 requests 抓取網頁",
"OpenCC 繁簡轉換工具使用指南",
"Jieba 斷詞引擎:精確模式與搜尋模式的差異",
"如何使用 BM25 演算法打造高效搜尋系統"
]
# 2. 斷詞 (建立索引需要的格式: List[List[str]])
tokenized_corpus = [jieba.lcut_for_search(doc) for doc in documents]
# 3. 初始化 BM25
bm25 = BM25Okapi(tokenized_corpus)
# 4. 搜尋
query = "搜尋引擎教學"
tokenized_query = jieba.lcut_for_search(query)
scores = bm25.get_scores(tokenized_query)
# 技巧:把分數跟原始文章 zip 起來排序
results = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
print(f"查詢: {query}")
for doc, score in results:
if score > 0:
print(f"[{score:.4f}] {doc}")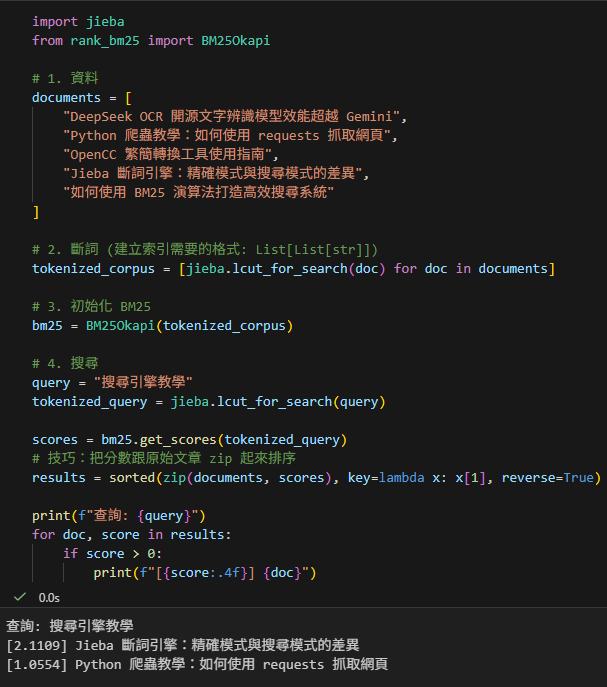
### 原理解析:為什麼 “搜尋引擎” 搜不到 “Python”?
**BM25 (Best Matching 25)** 的名字由來其實很單純:
* **BM** 代表 **Best Matching** (最佳匹配)。
* **25** 代表這是第 25 次演算法嘗試的結果
(該研究團隊在發布前試了很多版本,剛好第 25 版效果最好)。
BM25 依賴的是 **詞的重疊 (Exact Term Overlap)**。
* 當你搜「搜尋引擎」,Jieba 切出 `[‘搜尋’, ‘引擎’]`。
* 文章 5 有 `[‘高效’, ‘搜尋’, ‘系統’, ‘使用’, ‘BM25’, ‘演算法’]` -> 命中「搜尋」,得分!
* 文章 2 只有 `[‘Python’, ‘爬蟲’]` -> 沒命中,0 分。
這就是為什麼在我們的 `bm25_search_optimized.py` 專案中,
我們要大費周章做 **繁->簡轉換** 和 **Jieba 微調**,
因為如果詞切不對,BM25 這種依賴文字重疊的演算法就什麼都找不到。
推薦hahow線上學習python: https://igrape.net/30afN
, set.add(n)")

![Python:如何用pandas.concat() 合併兩個DataFrame並重置index? pd.concat([df1, df2]) .reset_index(drop=True) ; pd.concat([df1, df2], ignore_index=True)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230311123232_5.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python:如何用pandas.concat() 合併兩個DataFrame並重置index? pd.concat([df1, df2]) .reset_index(drop=True) ; pd.concat([df1, df2], ignore_index=True)")
 ; hex() or bin() #轉為16 or 2進位數字,會省略前導0")
![Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220514163621_72.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1")
 函數; from docx.oxml.ns import qn #qualified name ; qn(‘w:p’) ; qn(‘w:tbl’)")


 ; pickle.loads(binary_data)")
![Python網路爬蟲requests 如何下載台灣證交所的opendata? rawData = requests. get (inputs) #<Response [200]> - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/10/20221004135740_43-520x245.png)

近期留言