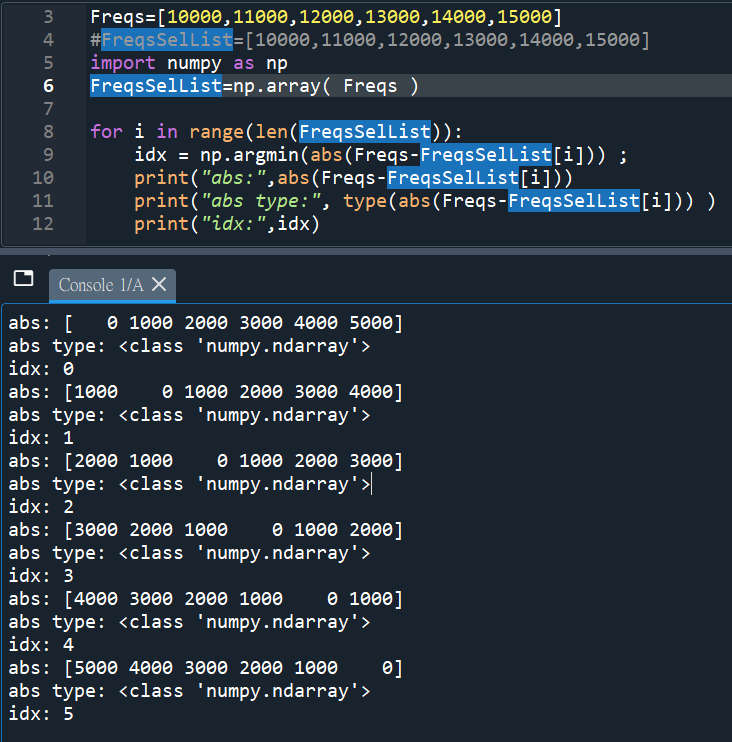
Freqs=[10000,11000,12000,13000,14000,15000] #list
import numpy as np
FreqsSelList=np.array( Freqs ) #array
for i in range(len(FreqsSelList)):
idx = np.argmin(abs(Freqs-FreqsSelList[i])) ;
print(“abs”,abs(Freqs-FreqsSelList[i]))
print(“idx”,idx)
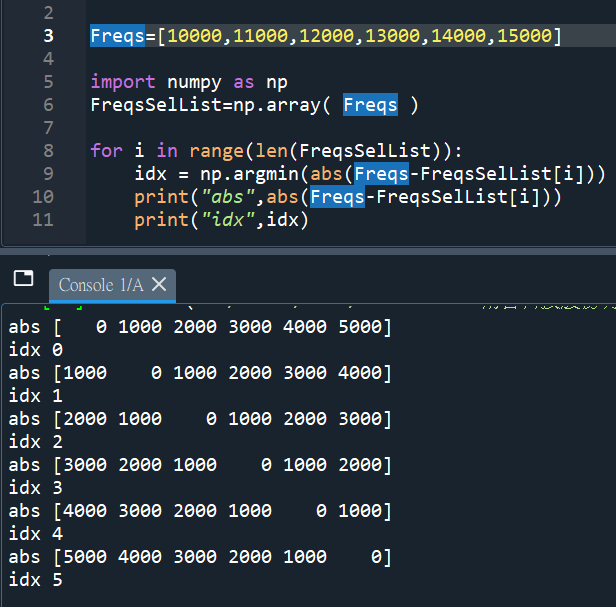
需要注意abs()
該物件為array,非list
若依註解處寫法:
FreqsSelList=[10000,11000,12000,13000,14000,15000]
會出現 TypeError:
unsupported operand type(s) for -: ‘list’ and ‘int’
 # 更改整個檔名(basename,含副檔名); Path.with_stem(“新檔名”) # 更改檔名主體(stem),保留原副檔名 ; Path.with_suffix(“.新副檔名”) # 更改副檔名(只影響最後一個 suffix)")
 與 re.split() 的用法與比較")

 #封裝 CT_P (Complex Type Paragraph)為 Paragraph 物件")
)")
 非捕獲與忽略大小寫")
 ; os.makedirs() ; 有何差別?")
,函數自己呼叫自己,遞迴(Recursive) , dict的value是dict ,巢狀dict,可使用tuple當key,但不可使用list當key")
")
![Python: 如何使用 pydub (dub:配音)將m4a 轉換為wav? 用 os.environ [ "PATH" ] 設定環境變量; from pydub import AudioSegment - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/09/20240905141103_0_95957e-520x245.png)
![Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄? df['sum_AB'] = df.apply(sum_ab, axis=1) ; lambda函式 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230314200417_4-520x245.png)

近期留言