fpath=r”C:\Python\WR75\Y Cut\Xpol.txt”
“””
#csv是逗點分隔檔
內容如下:
100.000,10000,11000,12000
-30.000,-70.765,-77.594,-76.722
-29.500,-71.492,-78.381,-76.414
“””
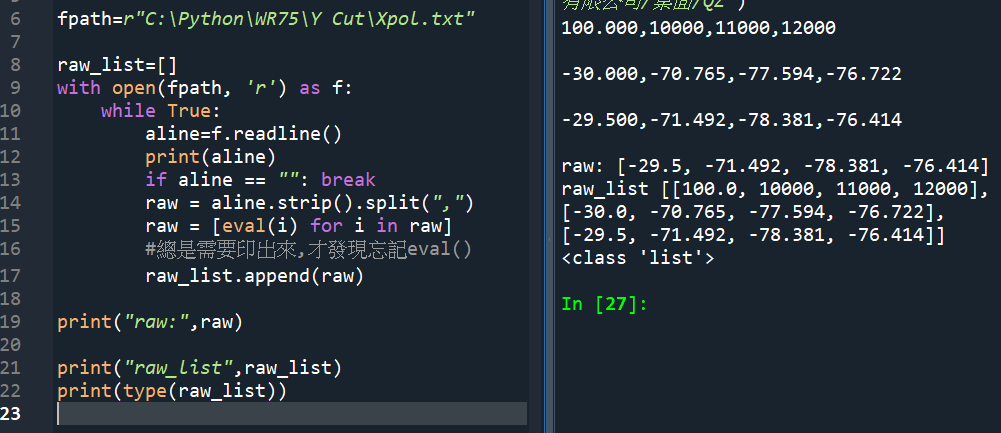
raw_list=[]
with open(fpath, ‘r’) as f:
while True:
aline=f.readline()
print(aline)
if aline == “”: break
raw = aline.strip().split(“,”)
#raw是1D list
raw = [eval(i) for i in raw]
#總是需要印出來,才發現忘記eval()
raw_list.append(raw)
#raw_list是一個2D list
print(“raw:”,raw)
print(“raw_list”,raw_list)
print(type(raw_list))
fpath=r”C:\Python\WR75\Y Cut\Xpol.txt”
raw_list=[]
with open(fpath, ‘r’) as f:
while True:
aline=f.readline()
print(aline)
if aline == “”: break
raw = aline.strip().split(“,”)
raw = [eval(i) for i in raw]
#總是需要印出來,才發現忘記eval()
raw_list.append(raw)
print(“raw:”,raw)
print(“raw_list”,raw_list)
print(type(raw_list))
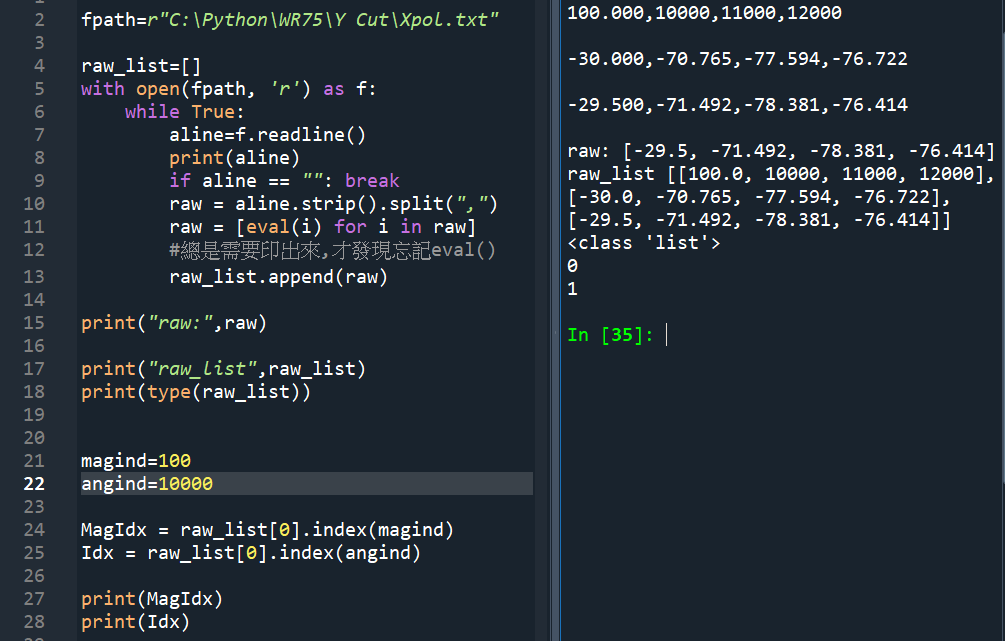
magind=100
angind=10000
MagIdx = raw_list[0].index(magind)
Idx = raw_list[0].index(angind)
print(MagIdx)
print(Idx)
raw_list[0]
[100.0, 10000, 11000, 12000]
因為檔案是縮小版
沒有0
原始檔案:
100~10000~15000~0~10000~15000
100, 0底下的資料都是角度,非強度
magind=100
angind=10000
MagIdx = raw_list[0].index(magind)
#100這個元素,index=0
Idx = raw_list[0].index(angind)
#10000這個元素,index=1
raw_list[0]
[100.0, 10000, 11000, 12000]
; BM25 (Best Matching 25) ; pip install rank-bm25 ; from rank_bm25 import BM25Okapi")

 -> list ,回傳該路徑中有那些檔案,目錄; fpath = os.path.join(folder, “*.csv” ) ; glob.glob(fpath) #通配符匹配(globbing),抓取目錄下的指定檔案名稱")

![Python-docx 圖片提取完全指南:從 rId 到二進位資料的探險rid ; part = doc.part.rels[rid].target_part #return part.blob if “ImagePart” in type(part).__name__ else None](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260113135812_0_8fa645.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python-docx 圖片提取完全指南:從 rId 到二進位資料的探險rid ; part = doc.part.rels[rid].target_part #return part.blob if “ImagePart” in type(part).__name__ else None")
的CRUD(Create, Read, Update, Delete)")
![Python `typing.NamedTuple` (`collections.namedtuple`) 與 `typing.Literal` 教學 — 用型別「防止錯配」; StripRule = NamedTuple(“StripRule”, [(“regex”, re.Pattern), (“flag”, str)]) vs StripRule = namedtuple(“StripRule”, [“regex”, “flag”])](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2026/07/20260702150603_0_86abc2.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python `typing.NamedTuple` (`collections.namedtuple`) 與 `typing.Literal` 教學 — 用型別「防止錯配」; StripRule = NamedTuple(“StripRule”, [(“regex”, re.Pattern), (“flag”, str)]) vs StripRule = namedtuple(“StripRule”, [“regex”, “flag”])")

 ; 如何重置欄index? DataFrame的屬性與方法 .values ; .to_numpy()")


近期留言