這個寫法常出現在 `sorted()` 或 `.sort()` 的 `key=` 參數中:
sorted(items, key=lambda x: (-len(x), x))它的目的很簡單:
1. 先讓較長的字串排在前面。
2. 如果字串長度相同,再用字母順序做穩定排序。
這是一種「複合排序鍵」(composite sort key)。
—
## 1. 為什麼不是直接用 `len(x)`?
因為 `sorted()` 預設是由小到大排序。
如果你寫:
sorted(items, key=len)結果會是:
– 短的先排
– 長的後排
但很多情境下,我們想要:
– 完整 Class Name 先出現
– 再來才是 bigram
– 最後才是短 token
所以會把長度取負號:
-len(x)例如:
– `len(“check”) = 5` -> `-5`
– `len(“pcie_check”) = 10` -> `-10`
– `len(“gsyspciecheckprocessstep”) = 24` -> `-24`
排序時因為 `-24 < -10 < -5`,所以就會變成:
– 最長的先排
– 最短的後排
—
## 2. 後面的 `x` 是做什麼?
這一段:
(-len(x), x)不是一個值,而是一個 tuple。
Python 比 tuple 的規則是:
1. 先比第一個元素
2. 如果第一個元素相同,再比第二個元素
所以:
key=lambda x: (-len(x), x)等於:
1. 先按長度由長到短排序
2. 長度相同時,再按字串本身的字母順序排序
這樣的好處是:
– 可讀性好
– 順序穩定
– 每次輸出 deterministic
—
## 3. 直接看範例
items = [
"check",
"pcie",
"gsys",
"pcie_check",
"gsys_pcie",
"GsysPcieCheckProcessStep",
]
result = sorted(items, key=lambda x: (-len(x), x))
print(result)輸出:
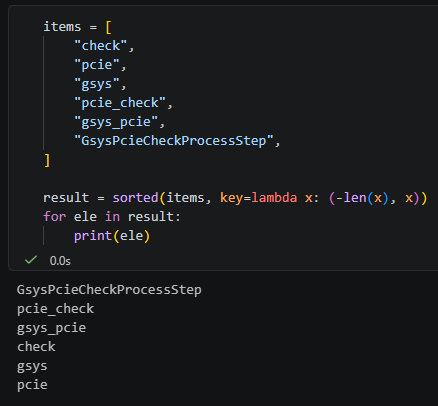
解釋:
– `GsysPcieCheckProcessStep` 最長,所以排第一
– `gsys_pcie` 和 `pcie_check` 會先排在較短字串前面,因為它們都比 `check`、`gsys`、`pcie` 長
– `gsys` 和 `pcie` 長度相同,這時才再按字母順序排,所以會是 `gsys` -> `pcie`
– `check` 會排在 `gsys`、`pcie` 前面,是因為它長度比較長,不是因為字母順序
—
## 4. 這和 `reverse=True` 有什麼不同?
很多人會寫:
sorted(items, key=len, reverse=True)這只能做到:
– 長的排前面
但做不到:
– 長度相同時再穩定按字母排序
例如同樣長度的元素,順序可能只是沿用原本輸入順序,不一定是你想要的人類可讀順序。
所以:
sorted(items, key=lambda x: (-len(x), x))通常比:
sorted(items, key=len, reverse=True)更適合做「穩定輸出」。
—
## 5. 什麼情況適合用?
很適合這種資料:
– 完整 class name
– bigram
– token
– 需要 deterministic 輸出的檢查 JSON
例如:
– `class_name_tokenized_lower`
– `class_name_bigram`
– `intersection_tokens`
– `intersection_bigrams`
這些欄位如果希望:
– 完整名稱先看見
– 較長片段優先
– 產出順序固定
那麼 `(-len(x), x)` 很適合。
—
## 6. 什麼情況不適合?
不適合拿去排「自然語料順序本身有意義」的欄位。
例如:
– `docx_body_tokens_lower`
– `docx_body_tokens_lower_clean`
– `body`
因為這些欄位保留的是原始語料的先後順序。
如果你硬排序,雖然 diff 可能更穩定,但語料原貌就被破壞了。
所以一個實務原則是:
1. 結構化 token / bigram 欄位:可以排序
2. 自然語料欄位:不要排序
—
## 7. 小結
`(-len(x), x)` 的意思是:
1. 先按字串長度由長到短排
2. 長度相同時再按字母順序排
它特別適合需要「人類可讀 + 穩定輸出」的結構化字串清單。
最常見寫法:
sorted(items, key=lambda x: (-len(x), x))如果要原地排序:
items.sort(key=lambda x: (-len(x), x))## 8. 一行記法
可以把它記成:
> 長的先,若一樣長,再照字母排。
推薦hahow線上學習python: https://igrape.net/30afN
最好改成「候選修補流程 + 迴圈嘗試」,不要一直巢狀 try/except。
你現在的問題不是功能不對,而是:
- 修補方法一多就一直往右縮排
- 很難加新策略
- 很難紀錄「到底是哪一步成功的」
- 很難對每個 strategy 做前處理
比較好的結構:strategy pipeline
核心想法:
- 先定義很多「候選 parser / repair 方法」
- 用
for迴圈依序嘗試 - 第一個成功就回傳
- 全部失敗才 fallback
這樣可讀性會好很多。
最簡潔的版本
import json
import json_repair
def parse_json_best_effort(bad_json_text: str):
strategies = [
("json.loads", lambda s: json.loads(s)),
("json_repair", lambda s: json_repair.loads(s)),
]
for stage, parser in strategies:
try:
obj = parser(bad_json_text)
return obj, stage
except Exception:
pass
return bad_json_text, "raw_string_fallback"
ocr_json_best_effort, ocr_json_parse_stage = parse_json_best_effort(bad_json_text)
print("parse_stage =", ocr_json_parse_stage)
print(type(ocr_json_best_effort).__name__)
print(ocr_json_best_effort)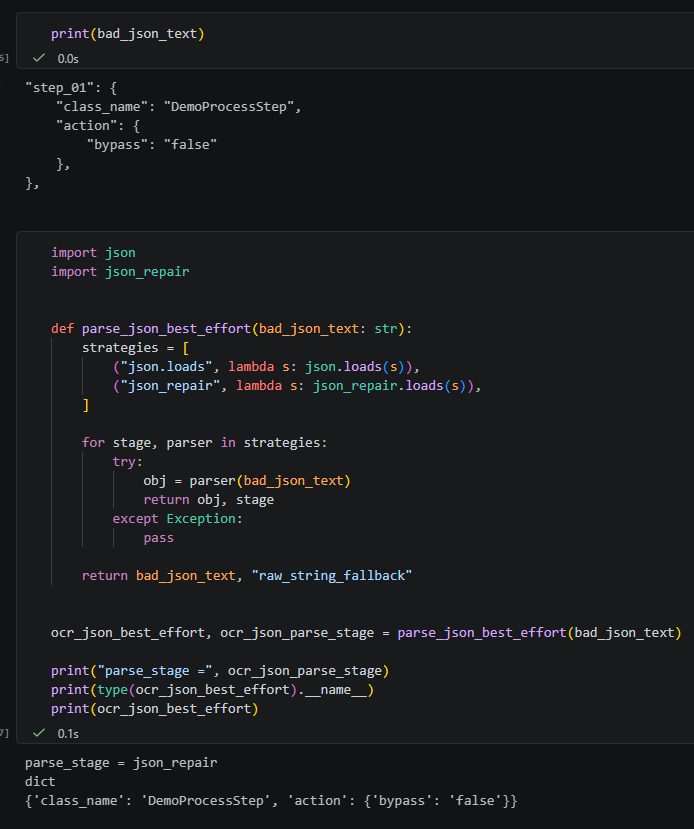
這樣的好處
1. 幾乎沒有巢狀縮排
主流程就是:
- 定義 strategies
- 迴圈嘗試
- 失敗 fallback
2. 很容易加新方法
例如你之後要加:
strip(",")- 包
{}後再json.loads - 包
[]後再json.loads
直接往 list 加就好。
推薦hahow線上學習python: https://igrape.net/30afN
 #pd.DataFrame.from_dict")
 ; axis參數如何用? numpy.max() ; numpy.min() ; numpy.argmax() #沿軸max的index; numpy.argmin() #沿軸min的index")
![Python: matplotlib如何設定座標軸刻度? plt.xticks(seq, labels) ;如何生成fig, ax物件? fig = plt.figure(figsize= (10.24, 7.68)) ; ax = fig.add_subplot() ; fig, ax = plt.subplots(figsize=(10.24, 7.68)) ; 如何使用中文? plt.rcParams[“font.family”] = [“Microsoft JhengHei”]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230209083006_41.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib如何設定座標軸刻度? plt.xticks(seq, labels) ;如何生成fig, ax物件? fig = plt.figure(figsize= (10.24, 7.68)) ; ax = fig.add_subplot() ; fig, ax = plt.subplots(figsize=(10.24, 7.68)) ; 如何使用中文? plt.rcParams[“font.family”] = [“Microsoft JhengHei”]")
![Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2024/11/20241123194900_0_5218de.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]")
 ; dot.attr(rankdir=’TB’, size=’10,15′) #”TB”: Top to Bottom, 從上而下的佈局")
, isdigit()")
 ; “”.join(ch for ch in normalized if not unicodedata.combining(ch))")


![Python TQC考題810 最大值與最小值之差,L=[eval(i) for i in s.split()] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/05/20220507094526_36-520x245.png)

近期留言