我們的目標是將極端不規則的 class_name
(例如 IPMIBMC_Check_PCIeNVMe),
乾淨且精準地拆解成 [‘IPMI’, ‘BMC’, ‘Check’, ‘PCIe’, ‘NVMe’]。
由於傳統的 \w+ 會把整串黏在一起,
而標準的駝峰拆分會把 PCIe 切壞變成 PC, Ie。
為了解決這個問題,我們設計了一套由左至右、
特例優先 (Exceptions First) 的雙層 Regex 引擎。
示範 Python Code
你可以直接執行這段程式碼來體驗切割效果:
import re
# 1. 專有名詞例外清單 (Exceptions)
# 這些詞必須被「完整保護」,不能被後面的駝峰規則切碎
exceptions = [
r'NVMe', r'PCIe', r'I2c', r'VGA', r'IPMI', r'BMC', r'Sensor', r'list'
]
# 2. 定義不分大小寫的群組外衣: 變成 (?i:NVMe|PCIe|I2c|VGA|IPMI|BMC|Sensor|list)
exceptions_joined_str = '|'.join(exceptions)
regex_wrapper_start = r'(?i:' # (?i: 代表這個小括號內的所有東西都不分大小寫
regex_wrapper_end = r')'
exceptions_pattern = regex_wrapper_start + exceptions_joined_str + regex_wrapper_end
# 3. 基礎主引擎 (負責處理常規的駝峰、連寫大寫、數字)
# 這裡用到 Lookahead 前瞻判斷 (?=...)
base_pattern = r'[A-Z]?[a-z]+|[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$)|\d+'
# 4. 組合最終兵器: 先配對例外 (| 前面),若沒中再進入主引擎 (| 後面)
camel_case_pattern = re.compile(exceptions_pattern + r'|' + base_pattern)
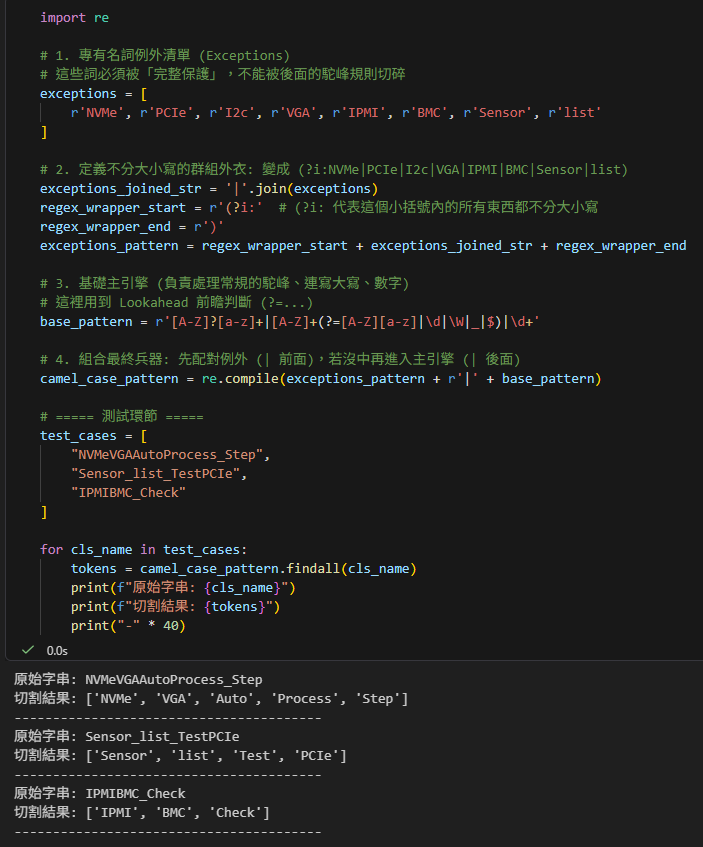
# ===== 測試環節 =====
test_cases = [
"NVMeVGAAutoProcess_Step",
"Sensor_list_TestPCIe",
"IPMIBMC_Check"
]
for cls_name in test_cases:
tokens = camel_case_pattern.findall(cls_name)
print(f"原始字串: {cls_name}")
print(f"切割結果: {tokens}")
print("-" * 40)輸出結果:
語法細節拆解:為什麼這樣寫可以切開?
- (?i: … ):不分大小寫的非捕獲群組
(?: … ) 是一種把條件綁在一起,但是不輸出多餘結果的括號。
加上 i 變成 (?i: … ),代表裡面放的 NVMe|PCIe,不管來源寫成 nvme, NVME, Nvme 都能被完美命中。 - Regex 引擎的「由左至右法則」
我們最後將條件合併為 特例規則 | 主引擎規則。
當遇到字串 “TestPCIe” 時,引擎的掃描順序是:
掃到 Test。它不符合例外清單,所以進入主引擎,被切出來。
剩下 PCIe。引擎掃描時發現它命中了左邊的例外清單! 於是直接整塊抽走,成功避開了進入右邊主引擎被切碎的命運。這就是「特例保護網」的機制。
3.主引擎 base_pattern 詳細分析
r'[A-Z]?[a-z]+ | [A-Z]+(?=[A-Z][a-z]|\d|\W|_|$) | \d+'這段被 | 切成三個主要的攻擊火力:
攻擊 A:[A-Z]?[a-z]+
這負責最常見的命名。
[A-Z]?:有沒有大寫開頭都可以 (例如 P 或沒有)。
[a-z]+:後面一定要接至少一個小寫的單字。
效果:它會把 Process, Step, auto, list 等詞全部抓出來。
攻擊 B:[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$) (連續大寫對策)
這負責處理 VGAAuto 這種連續大寫縮寫接上一般單字的狀況,要怎麼知道在哪裡能切斷?
[A-Z]+:貪婪地抓取連在一起的大寫字母 (抓到 VGAA)。
(?= … ):這叫正向先行斷言 (Lookahead)。它的意思是:「我想切斷,但我得先『偷看』下一個字元符合不符合規矩,符合我才切。」而且偷看的部分不會被消耗掉,留給下一輪使用。
偷看的條件有很多:
[A-Z][a-z]:如果下一個出現的是「大寫接小寫」(這就是為什麼 VGAAuto 抓到 VGA 時,看到偷看的字是 Au,就在 A 前面果斷切斷的原因)。
\d:如果下一個是數字也切斷。
\W:非單字字元也切斷(例如空格)。注意:\w 是包含 [a-zA-Z0-9_] 的,所以 \W (大寫) 是排除它們,也就是說 \W 漏掉了底線。
因為 \W 沒有涵蓋底線,如果字串是 SENSOR_LIMIT,它會不知道該停下來。所以我們必須手動在看前方的條件補上 ,告訴引擎「看到下一個字元是底線,也要停下來切斷」。
$:或者是已經到了字尾。
攻擊 C:\d+
針對不管在哪裡出現的純數字串 (諸如版本號 2 或 101),把它獨立拔出來。
小結:任何不屬於我們規則裡面 (不是英文字母也不是數字) 的符號,例如底線 _ 或是空格,都會被正規表達式默默地「跳過」,我們便得到了一份非常乾淨且符合測試領域語意的 Token 陣列!
推薦hahow線上學習python: https://igrape.net/30afN
\w 與 \W
\w
表示 word character,也就是「字元類型中的單字字元」。
通常等價於:
[a-zA-Z0-9_]在 Python 3 的 re 裡,如果是 Unicode 模式,\w 範圍會比這更廣,會包含其他語系的字母數字;但你平常可以先簡單記成:
- 英文字母
- 數字
- 底線
_
\W
表示 非 \w 的字元。
也就是「不是單字字元」的任何字元。
大致等價於:
[^a-zA-Z0-9_]例如:
- 空白
-.,!@#- 各種符號
都屬於 \W
套回pattern
這段:
base_pattern = r'[A-Z]?[a-z]+|[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$)|\d+'其中這一段:
(?=[A-Z][a-z]|\d|\W|_|$)是在說:
前面的 [A-Z]+ 這串大寫字母,後面必須接著是以下其中之一:
[A-Z][a-z]
代表後面開始一個 CamelCase 單字,例如XMLParser裡的P\d
後面是數字\W
後面是非單字字元,例如空白、符號、標點_
後面是底線$
字串結尾
不過這裡有個小提醒
因為 \w 本來就包含 _,所以 \W 不包含 _。
也就是:
_是\w- 所以
_不是\W
因此你這裡寫:
\W|_是合理的,因為你想同時涵蓋:
- 非單字字元
- 以及底線
_
這段 regex 的白話註解版
base_pattern = r'''
[A-Z]?[a-z]+ # 一般單字:可選 1 個大寫開頭 + 之後至少 1 個小寫
| # 或
[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$) # 連續大寫字母,但後面必須接:
# - 一個 CamelCase 開頭 ([A-Z][a-z])
# - 或數字 \d
# - 或非單字字元 \W
# - 或底線 _
# - 或字串結尾 $
| # 或
\d+ # 一串數字
'''簡短版註解 \w / \W
你可以直接這樣記:
\w # 單字字元:字母、數字、底線 _
\W # 非單字字元:不是字母、數字、底線 _例子
# %%
import re
text = "A_b-9!"
print(re.findall(r'\w', text))
print(re.findall(r'\W', text))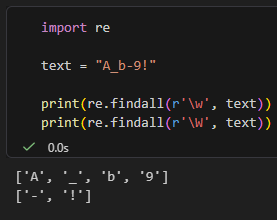
base_pattern = r'[A-Z]?[a-z]+|[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$)|\d+'逐段中文註解版
base_pattern = r'''
[A-Z]?[a-z]+ # 一般英文單字:
# 可選 1 個大寫字母開頭,後面接 1 個以上小寫字母
# 可匹配:
# "Class"
# "name"
# "Parser"
| # 或
[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$) # 連續大寫字母縮寫:
# 先匹配 1 個以上大寫字母
# 但後面必須緊接以下其中之一(前瞻,不吃字元):
#
# [A-Z][a-z]
# 後面是一個駝峰單字的開頭
# 例如 "XMLParser" 裡的 "XML"
#
# \d
# 後面接數字
# 例如 "IPv6" 裡的 "IP"
#
# \W
# 後面接非單字字元
# \W = 不是字母 / 數字 / 底線 _
# 例如空白、-、.、,、!、@
#
# _
# 後面接底線
# 因為 _ 屬於 \w,不屬於 \W
# 所以若要把底線視為分界,要額外寫出來
#
# $
# 字串結尾
# 例如整串最後就是大寫縮寫 "NVMeID" 裡最後的 "ID"
| # 或
\d+ # 1 個以上數字
# 可匹配:
# "123"
# "64"
# "2025"
'''這條 regex 想做的事
它大致是在把字串切成這幾類 token:
- 一般字詞
ClassNameparser
- 全大寫縮寫
XMLHTTPNVMe- 更精確地說,會先抓可成立的全大寫段
- 數字
12364
\w / \W 再濃縮一次
\w # word char:字母、數字、底線 _
\W # non-word char:不是字母、數字、底線 _範例
A是\w7是\w_是\w-是\W.是\W- 空白 是
\W
為什麼這裡要寫 \W|_
因為:
\W不包含__屬於\w
所以如果你想把 _ 也當成邊界條件,就必須另外寫出來:
\W|_推薦hahow線上學習python: https://igrape.net/30afN
; 對於np.bool_ 做乘法等效於and ; 對於np.bool_ 做加法等效於or")
")
如何擴充tabnine (AI人工智能輔助程式碼完成)? 如何將編輯畫面切分為左右兩邊,分別顯示兩個不同檔案?")
 方法說明,計算唯一值的數量,與 len( pandas.Series.unique() ) 同效果")

 re.search() 和 re.match() 的區別")


 套件繪製具有多個子圖的折線圖? sns.relplot(data=tips, x=’total_bill’, y=’tip’, hue=’sex’, col=’day’, row=’time’, facet_kws={‘margin_titles’: True}, height=3, aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)")
![Python陣列介紹:List[ ], Tuple( ), Set{ }, Dictionary{ }, for迴圈 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/01/1643329597-856443d20256b1a850089a56d07657bf-520x245.png)

近期留言