William Bernstein的智慧型資產配置 P49:
那些忽視投資史的人註定會重蹈歷史覆轍,
應該要研究各類資產的歷史投資報酬與風險,
一項資產的長期投資報酬結果(20年以上)
是該資產未來報酬與風險的適當指引
1972年初到2022年底
總共有51個完整年度
47個移動5年
抓下來的原始資料跟IRR計算機
(exe檔,無需python環境也可執行)
SavingKingIRR_csv.exe
需要自己寫好逗點分隔檔
支援首續期不同保費
以及一次計算多年期IRR
不用寫逗點分隔檔
但首續期保費需相同
一次只能算一個年期
畫面會停在
您將輸入n年度末解約金?n=?
待使用者輸入下一筆資料或-9999離開
您將輸入n年度末解約金?n=?
待使用者輸入下一筆資料或-9999離開
前傳為2016年撰寫:
當時手動抓了325次資料 ><“
本篇加入~2022年底的資料
並改用python計算
推薦hahow線上學習python: https://igrape.net/30afN
片段原始資料如下:
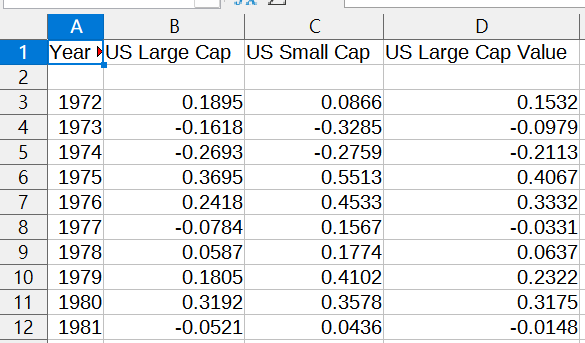
資料從1972年初開始
改抓新興市場報酬率時
只能從1995年初開始
先放輸出結果
python code放後面
小型股溢酬:
US Small Cap – US Large Cap
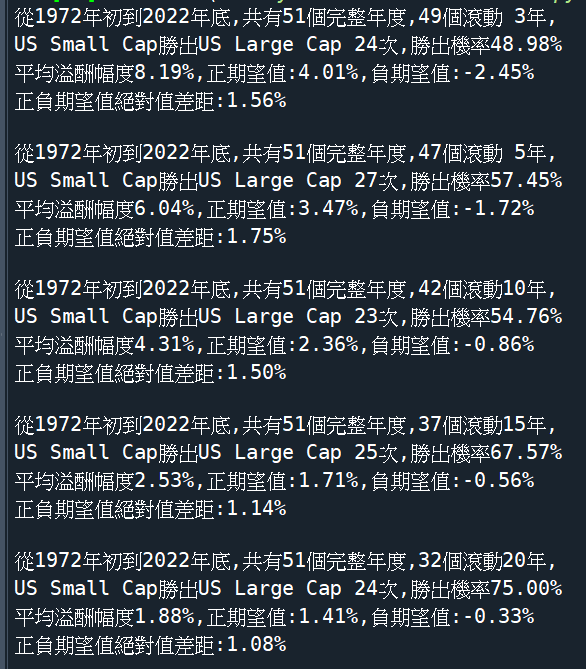
滾動五年,小型股勝出27次
平均溢酬幅度6.04%
有手工用excel驗算過無誤
但不保證無其他錯誤
若有人發現python code錯誤
致贈50元7咖啡*2杯
正期望值 = 溢酬(勝出)機率* 平均勝出幅度
負期望值 = (1-溢酬機率)* 平均輸的幅度
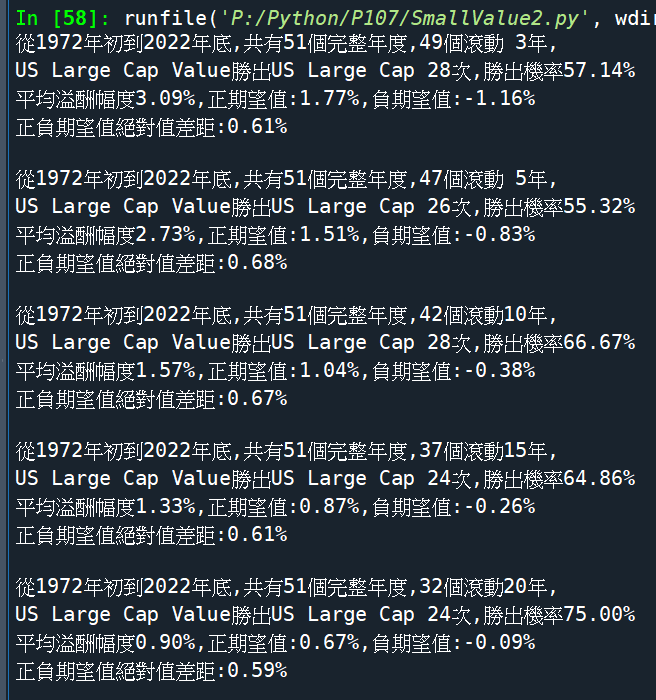
價值股溢酬:
US Large Cap Value – US Large Cap
相關連結:
Python: pandas.DataFrame與numpy.ndarray
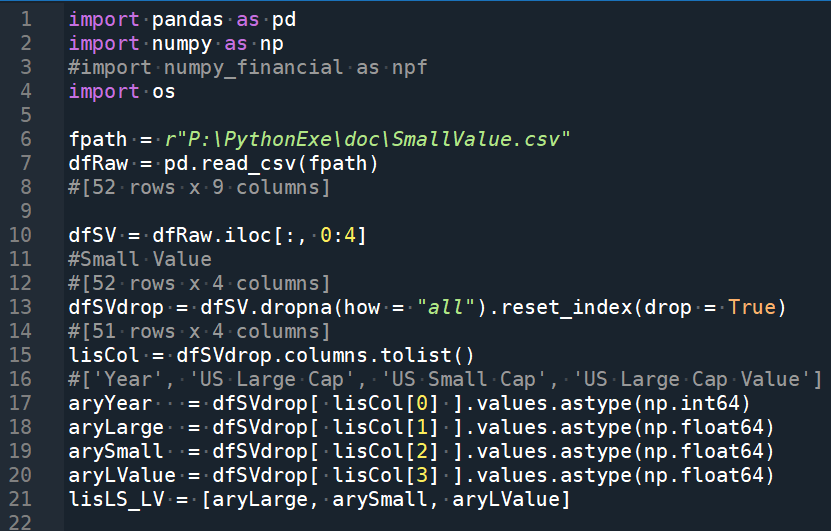
python code:
import pandas as pd
import numpy as np
#import numpy_financial as npf
import os
fpath = r”P:\PythonExe\doc\SmallValue.csv”
dfRaw = pd.read_csv(fpath)
#[52 rows x 9 columns]
dfSV = dfRaw.iloc[:, 0:4]
#Small Value
#[52 rows x 4 columns]
dfSVdrop = dfSV.dropna(how = “all”).reset_index(drop = True)
#[51 rows x 4 columns]
lisCol = dfSVdrop.columns.tolist()
#[‘Year’, ‘US Large Cap’, ‘US Small Cap’, ‘US Large Cap Value’]
aryYear = dfSVdrop[ lisCol[0] ].values.astype(np.int64) #np.uint64更好
aryLarge = dfSVdrop[ lisCol[1] ].values.astype(np.float64)
arySmall = dfSVdrop[ lisCol[2] ].values.astype(np.float64)
aryLValue = dfSVdrop[ lisCol[3] ].values.astype(np.float64)
lisLS_LV = [aryLarge, arySmall, aryLValue]
#Large, Small, LargeValue
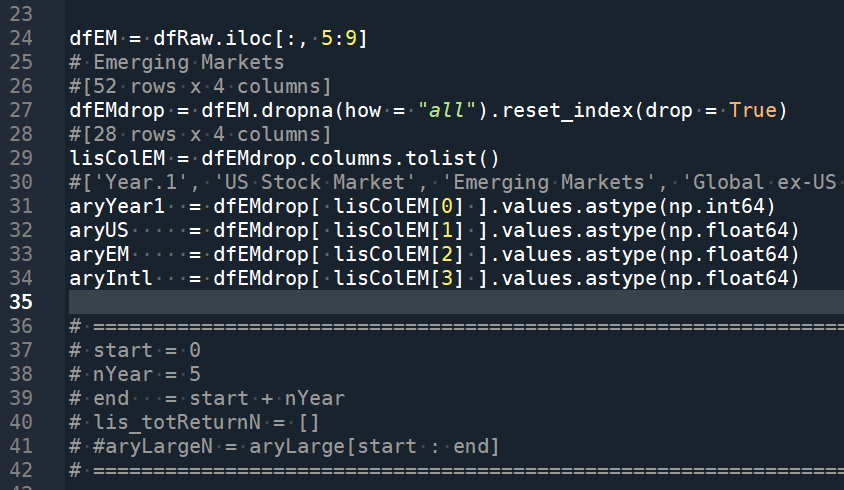
dfEM = dfRaw.iloc[:, 5:9]
# Emerging Markets
#[52 rows x 4 columns]
dfEMdrop = dfEM.dropna(how = “all”).reset_index(drop = True)
#[28 rows x 4 columns]
lisColEM = dfEMdrop.columns.tolist()
#[‘Year.1’, ‘US Stock Market’, ‘Emerging Markets’, ‘Global ex-US Stock Market’]
aryYear1 = dfEMdrop[ lisColEM[0] ].values.astype(np.int64)
aryUS = dfEMdrop[ lisColEM[1] ].values.astype(np.float64)
aryEM = dfEMdrop[ lisColEM[2] ].values.astype(np.float64)
aryIntl = dfEMdrop[ lisColEM[3] ].values.astype(np.float64)
# =================================
# start = 0
# nYear = 5
# end = start + nYear
# lis_totReturnN = []
# #aryLargeN = aryLarge[start : end]
# =================================
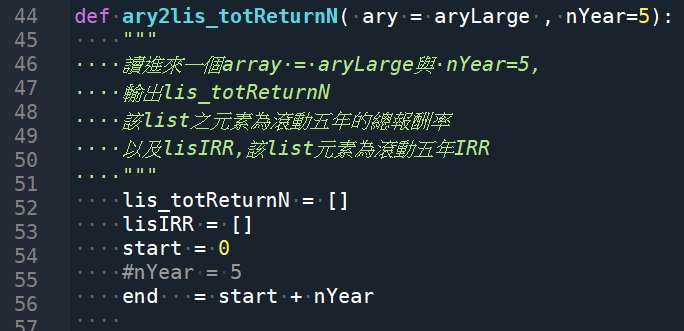
def ary2lis_totReturnN( ary = aryLarge , nYear=5):
“””
讀進來一個array = aryLarge與 nYear=5,
輸出lis_totReturnN
該list之元素為滾動五年的總報酬率
以及lisIRR,該list元素為滾動五年IRR
“””
lis_totReturnN = []
lisIRR = []
start = 0
#nYear = 5
end = start + nYear
while True:
aryN = ary [start : end]
# aryN_IRR = npf.irr(aryN)
# lisIRR.append(aryN_IRR)
# 很多nan,因為aryN並不是正負現金流,
# 而是各年度報酬率
# std = np.std(aryN) #若要收集波動度資料
if len(aryN) < nYear : break
totReturnN = 1
for i in range(nYear):
totReturnN *= (1 + aryN[i])
totReturnN = totReturnN-1
irr = (1+totReturnN)**(1/nYear) – 1
lisIRR.append(irr) #len(lisIRR) =47
lis_totReturnN.append( totReturnN )
#len(lis_totReturnN) = 47
#47次滾動五年
start += 1
end = start + nYear
return lis_totReturnN, lisIRR
# ========================================
# lis_totReturnN, lisIRR = \
# ary2lis_totReturnN( ary = aryLarge , nYear=5)
# ========================================
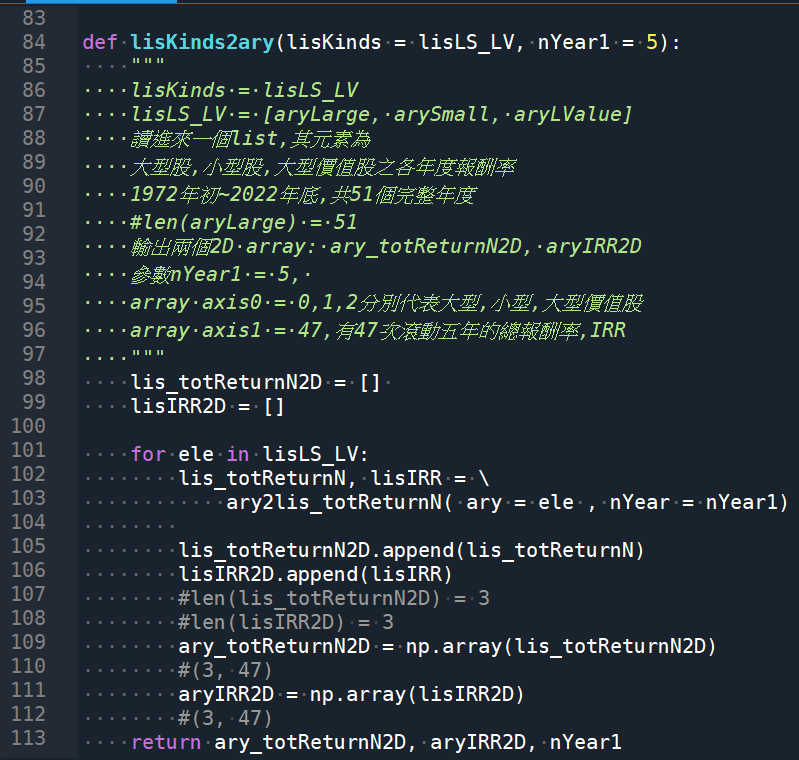
def lisKinds2ary(lisKinds = lisLS_LV, nYear1 = 5):
“””
lisKinds = lisLS_LV
lisLS_LV = [aryLarge, arySmall, aryLValue]
讀進來一個list,其元素為
大型股,小型股,大型價值股之各年度報酬率
1972年初~2022年底,共51個完整年度
#len(aryLarge) = 51
輸出兩個2D array: ary_totReturnN2D, aryIRR2D
參數nYear1 = 5,
array axis0 = 0,1,2分別代表大型,小型,大型價值股
array axis1 = 47,有47次滾動五年的總報酬率,IRR
“””
lis_totReturnN2D = []
lisIRR2D = []
for ele in lisLS_LV: #for ele in lisKinds: #訂正,結果剛好一樣
lis_totReturnN, lisIRR = \
ary2lis_totReturnN( ary = ele , nYear = nYear1)
lis_totReturnN2D.append(lis_totReturnN)
lisIRR2D.append(lisIRR)
#len(lis_totReturnN2D) = 3
#len(lisIRR2D) = 3
ary_totReturnN2D = np.array(lis_totReturnN2D)
#(3, 47)
aryIRR2D = np.array(lisIRR2D)
#(3, 47)
return ary_totReturnN2D, aryIRR2D, nYear1
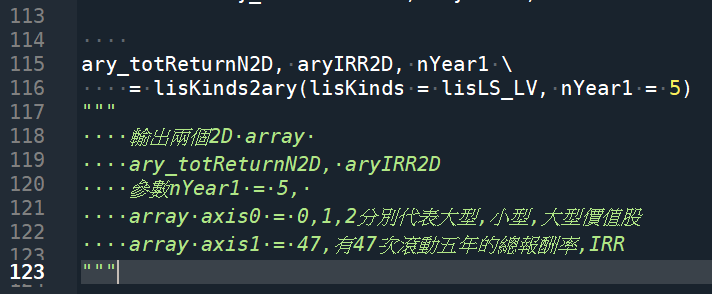
ary_totReturnN2D, aryIRR2D, nYear1 \
= lisKinds2ary(lisKinds = lisLS_LV, nYear1 = 5)
“””
輸出兩個2D array
ary_totReturnN2D, aryIRR2D
參數nYear1 = 5,
array axis0 = 0,1,2分別代表大型,小型,大型價值股
array axis1 = 47,有47次滾動五年的總報酬率,IRR
“””
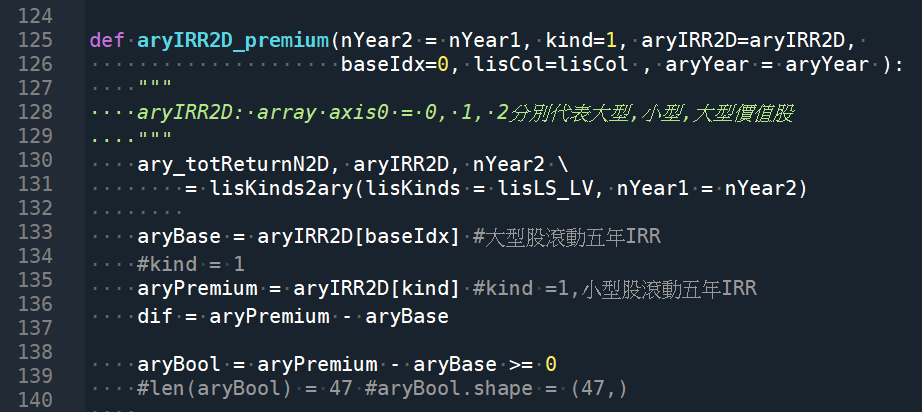
def aryIRR2D_premium(nYear2 = nYear1, kind=1, aryIRR2D=aryIRR2D,
baseIdx=0, lisCol=lisCol , aryYear = aryYear ):
“””
aryIRR2D: array axis0 = 0, 1, 2分別代表大型,小型,大型價值股
“””
ary_totReturnN2D, aryIRR2D, nYear2 \
= lisKinds2ary(lisKinds = lisLS_LV, nYear1 = nYear2)
aryBase = aryIRR2D[baseIdx] #大型股滾動五年IRR
#kind = 1
aryPremium = aryIRR2D[kind] #kind =1,小型股滾動五年IRR
dif = aryPremium – aryBase
aryBool = aryPremium – aryBase >= 0
#len(aryBool) = 47 #aryBool.shape = (47,)
tup = aryBase, aryPremium, dif, aryBool
aryBasePre = np.vstack( tup )
df = pd.DataFrame(aryBasePre).T
df.columns =[ lisCol[baseIdx+1], lisCol[kind+1],”差距”,”是否溢酬” ]
folder = r”P:\PythonExe\doc\premium”
fname = lisCol[kind+1] + “_premium_” + str(nYear2) + “.xlsx”
#別漏副檔名 “.xlsx”
fpath = os.path.join(folder, fname)
df.to_excel(fpath)
aryTrueIdx = aryBool.nonzero()[0]
#aryBool.nonzero() 是長度1的tuple
#aryBool.nonzero()[0]才是array #shape (27,)
#avgPreIRR = np.mean( aryPremium[aryTrueIdx.tolist()] )
cntPremium = len(aryTrueIdx) #cntPremium = 27
cntBase = len(aryBase) #47
prob = cntPremium/cntBase
print(“從%4d年初到%4d年底,共有%2d個完整年度,%2d個滾動%2d年,\n%s勝出%s %2d次,勝出機率%.2f%%\n”
%( aryYear[0], aryYear[-1], len(aryYear), cntBase, nYear2,
lisCol[kind+1],lisCol[baseIdx+1],cntPremium, prob*100) )
#lisCol[kind+1],因為lisCol多一欄year欄位
return None
lis_nYear = [3,5,10,15,20]
for n in lis_nYear:
aryIRR2D_premium(nYear2 = n, kind=1, aryIRR2D=aryIRR2D,
baseIdx=0, lisCol=lisCol , aryYear = aryYear )
推薦hahow線上學習python: https://igrape.net/30afN


推薦hahow線上學習python: https://igrape.net/30afN
 切割資料為訓練資料跟測試資料; 二元分類 ; 邏輯迴歸 (Logistic Regression); from sklearn.model_selection import train_test_split ; lmLogR= linear_model.LogisticRegression(solver=”sag”, max_iter=10000)")
與不可變對象(tuple, str)的更新行為差異")

")


![Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]")
![Python網路爬蟲requests 如何下載台灣證交所的opendata? rawData = requests. get (inputs) #<Response [200]>](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/10/20221004135740_43.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python網路爬蟲requests 如何下載台灣證交所的opendata? rawData = requests. get (inputs) #<Response [200]>")
 as file: for line in file: for w in line.split()")

近期留言