在做 Class Name 的 OCR 模糊匹配時,很多人一開始都會用一個很直覺的方法:
- 先看整個字串誰最像
- 從幾個最像的候選中挑最佳答案
這種方法很自然,也很常見。
但當你實際處理一批有固定命名規則的類別名稱後,通常會慢慢發現一個問題:
整體字串相似度,常常會被共同長尾綴欺騙。
例如這類名稱:
PSmbiosCheckProcessStepXgmiCheckProcessStepMemoryCheckProcessStep
它們都有很長、很像的尾巴:
ProcessStep
所以如果你用完整字串去做初篩,演算法很可能先被尾巴吸引,而不是先看真正有辨識度的主體名稱。
這篇文章要講的核心觀念就是:
一旦知道 Class Name 存在長尾欺騙效應,就不該再用整體字串做初篩;應該直接改用字根(root)作為第一個核心判斷依據。
一、問題的本質:Class Name 並不是一般字串
如果字串是隨機的,直接比整串相似度通常沒什麼大問題。
但 Class Name 常常不是這樣。它通常長得像:
主體名稱 + 固定尾綴例如:
PSmbiosCheck + ProcessStep
XgmiCheck + ProcessStep
MemoryCheck + ProcessStep這時候真正有資訊量的部分,其實是前面的主體:
PSmbiosCheckXgmiCheckMemoryCheck
而後面的尾綴:
ProcessStep
往往只是型別、流程、步驟之類的命名慣例。
也就是說:
尾綴常常很像,但不代表它們是同一個 Class。
二、為什麼整體初篩是直覺,但也是粗淺做法?
一開始最直覺的流程通常是這樣:
長度粗篩
-> 從候選裡找整體最像的幾個
-> 再做更細的比對這個想法的出發點很合理:
先用便宜的方法縮小範圍,再精查。
問題在於,這個「便宜的方法」如果用的是完整字串相似度,那它看到的是:
- 主體名稱
- 共同尾綴
- OCR 錯字
- 所有字符混在一起的總效果
而在 Class Name 命名高度規律的情況下,尾綴往往佔了太大比例。
所以整體初篩很容易出現這種情況:
- 主體錯了
- 但尾巴很像
- 於是還是拿到高分
這就是所謂的:
被長尾巴欺騙
三、發現長尾欺騙後,正確方向不是補強第二步,而是移除第二步
這是一個很關鍵的設計轉折。
很多人發現整體比對不夠準之後,會這樣補:
長度粗篩
-> 整體初篩
-> 再加一層 root_score
-> 再比 overall_score這樣看起來好像比較完整,但其實有一個根本問題:
如果第二步本身就可能把正確答案刷掉,那後面再強也沒用。
也就是說,root_score 不應該只是用來「補強」整體初篩,
而應該是:
直接取代整體初篩,成為第一個真正有判斷力的關卡。
所以更合理的流程應該改成:
長度粗篩
-> root_score
-> overall_score這樣才不會在演算法一開始,就被共同尾綴帶偏。
四、什麼是 root?為什麼它才是核心?
這裡的 root,就是把常見尾綴剝掉後,剩下來真正有辨識度的主體名稱。
例如:
PSmbiosCheckProcessStep -> PSmbiosCheck
XgmiCheckProcessStep -> XgmiCheck
MemoryCheckStep -> MemoryCheck這些 root 才是你真正想拿來判斷「是不是同一類東西」的部分。
所以我們的策略變成:
- 先把候選名稱尾綴拿掉
- OCR 字串也嘗試拿掉尾綴
- 先比較 root 像不像
- root 不像,直接淘汰
- root 像,才進一步比完整字串
這樣的邏輯非常符合資料本身的結構。
五、反覆剝除尾綴:核心工具函式
這段程式是整個方法的基礎:
def strip_tail(name):
curr = name
while tail_pattern.search(curr):
curr = tail_pattern.sub('', curr)
return curr它的設計很簡單:
- 只要字串尾端符合某些尾綴規則,就剝掉
- 剝掉之後再檢查一次
- 一直做到尾端不再符合規則為止
六、先定義可剝除的尾綴規則
下面是一個簡單示例,假設我們把這些當成可剝除尾綴:
ProcessStepProcessStepStep_數字ProcessStep_數字
可以這樣寫:
import re
import difflib
tail_pattern = re.compile(r'(ProcessStep(?:_\d+)?|Process|Step(?:_\d+)?)$')
"""希望 strip_tail() 對大小寫更寬容:
tail_pattern = re.compile(
r'(ProcessStep(?:_\d+)?|Process|Step(?:_\d+)?)$',
re.I
)
"""搭配剛剛的函式:
def strip_tail(name):
curr = name
while tail_pattern.search(curr):
curr = tail_pattern.sub('', curr)
return curr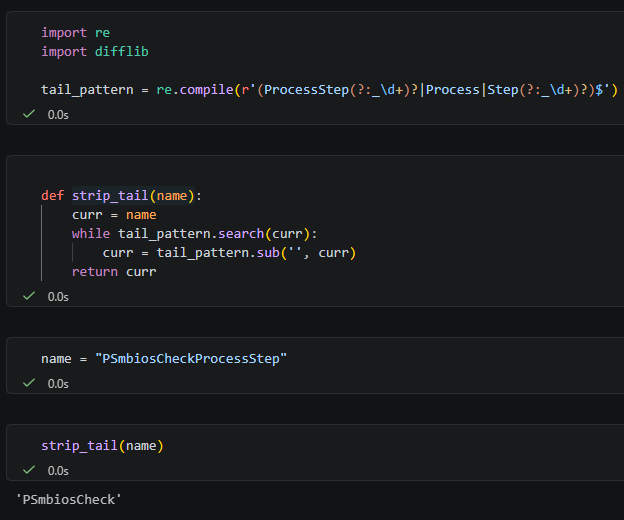
七、為什麼 OCR 錯字時,還需要 fallback?
假設 OCR 結果是:
PSmbiosCheckProcesStep正確應該是:
PSmbiosCheckProcessStep少了一個 s,導致尾綴 ProcesStep 不符合 regex 規則。
這時:
strip_tail("PSmbiosCheckProcesStep")不會成功剝尾,結果還是原字串。
如果演算法只會「正常剝尾後再比 root」,那這種 OCR 錯字就會卡住。
所以我們需要一個 fallback 邏輯:
- 如果 OCR 尾巴能正常剝掉,就直接拿 OCR 的 root 去比
- 如果剝不掉,表示尾巴可能辨識壞了
- 這時改拿 OCR 字串前面等長的前綴,去對比 candidate 的 root
因為在很多情況下,OCR 雖然把尾巴辨識錯,但前面的主體名稱仍然是對的。
八、最終流程:長度粗篩 → root_score → overall_score
這是我認為最適合這類問題的版本:
先做長度粗篩
對每個候選:
先剝除尾綴,取得 c_root
再取得 OCR 的 root 或 fallback prefix
計算 root_score
如果 root_score 不夠高:
直接淘汰
如果 root_score 過關:
再計算完整字串的 overall_score
最後從過關者中選 overall_score 最高者這裡的重點不是「完全不看完整字串」,而是:
完整字串只能作為第二層排序依據,不能再當第一層初篩依據。
九、完整 Python 範例
下面是一版結構清楚、適合教學與實作的程式碼:
import re
import difflib
# 定義可剝除的尾綴
tail_pattern = re.compile(r'(ProcessStep(?:_\d+)?|Process|Step(?:_\d+)?)$')
def strip_tail(name):
"""
反覆剝除尾綴,直到尾端不再符合規則。
例如:
PSmbiosCheckProcessStep -> PSmbiosCheck
MemoryCheckStep_2 -> MemoryCheck
"""
curr = name
while tail_pattern.search(curr):
curr = tail_pattern.sub('', curr)
return curr
def similarity(a, b):
"""
回傳兩字串的相似度,範圍 0 ~ 1。
"""
return difflib.SequenceMatcher(None, a.lower(), b.lower()).ratio()
def find_best_class_name(ocr_name, candidates, max_len_diff=4):
"""
從 candidates 中找出最可能對應 ocr_name 的 Class Name。
設計重點:
1. 不再做整體字串初篩
2. 直接以 root_score 作為第一道核心判斷
3. 只有 root 過關者,才進一步比較完整字串
"""
# Step 1: 長度粗篩
valid_candidates = [
c for c in candidates
if abs(len(c) - len(ocr_name)) <= max_len_diff
]
if not valid_candidates:
return None
best_match = None
best_overall_score = 0
# OCR 先做一次尾綴處理,避免重複計算
ocr_root_clean = strip_tail(ocr_name)
for candidate in valid_candidates:
# Step 2: 取得 candidate 的 root
c_root = strip_tail(candidate)
# Step 3: 決定 root 比對目標
if ocr_root_clean != ocr_name:
# OCR 尾巴正常可剝除,直接拿 root 比
compare_target = ocr_root_clean
else:
# OCR 尾巴可能辨識錯,改拿前綴做 fallback
compare_target = ocr_name[:len(c_root)]
# Step 4: 第一關,先比 root
root_score = similarity(c_root, compare_target)
# root 短時門檻稍微放寬
root_threshold = 0.8 if len(c_root) <= 5 else 0.85
if root_score < root_threshold:
continue
# Step 5: 第二關,root 過關才比完整字串
overall_score = similarity(ocr_name, candidate)
if overall_score > best_overall_score:
best_overall_score = overall_score
best_match = candidate
return best_match十、實際例子
假設 OCR 輸入:
ocr_name = "PSmbiosCheckProcesStep"候選清單:
candidates = [
"PSmbiosCheckProcessStep",
"XgmiCheckProcessStep",
"MemoryCheckProcessStep",
"PSmbiosCheckStep",
]第一步:長度粗篩
先排除長度差太多的候選,避免浪費計算。
第二步:對每個候選比 root
候選 1
PSmbiosCheckProcessStep剝尾後:
c_root = "PSmbiosCheck"OCR 因為 ProcesStep 拼錯,尾巴剝不掉,所以 fallback:
compare_target = ocr_name[:len("PSmbiosCheck")]
= "PSmbiosCheck"比對結果幾乎完全一致,root_score 很高,過關。
候選 2
XgmiCheckProcessStep剝尾後:
c_root = "XgmiCheck"fallback 前綴會接近:
PSmbiosC...和 XgmiCheck 完全不是同個主體,因此 root_score 很低,直接淘汰。
第三步:只在 root 過關者中比 overall
這時完整字串比對才有意義,因為你已經先確認它們的主體是同一類了。
十一、這個版本比「整體初篩版」好在哪裡?
1. 不會被共同尾綴誤導
它不再讓完整字串相似度站在流程最前面。
2. 不會提早誤殺正解
正確候選不會因為整體初篩失準,在 root 比對前就被刷掉。
3. 更符合資料結構
因為你的 Class Name 本來就是:
root + suffix那演算法就應該順著這個結構設計。
4. 對 OCR 尾巴錯字更有韌性
尾巴剝不掉時,還能用前綴 fallback 補救。
十二、這篇文章真正想傳達的設計觀念
這不只是「改一個函式」而已,背後其實是一個很重要的演算法思維:
不要讓低資訊量、且已知會誤導的特徵,站在核心判斷之前。
在這個問題裡:
- 長度差:只是粗篩條件
- 完整字串相似度:容易被共同尾綴干擾
- root 相似度:才是真正高資訊量特徵
所以最合理的順序就是:
長度粗篩 -> root_score -> overall_score而不是:
長度粗篩 -> 整體初篩 -> root_score -> overall_score十三、結語
一開始用整體字串做初篩,是很自然的第一版做法。
但當你已經觀察到 Class Name 的命名規則具有共同長尾綴,而且這些尾綴會系統性影響相似度判斷時,就不應該再把整體初篩保留在流程前面。
更穩健、也更符合問題本質的方式是:
直接剔除整體初篩,改由字根比對作為第一個核心關卡。
而這個方法的關鍵,就是這段反覆剝除尾綴的函式:
def strip_tail(name):
curr = name
while tail_pattern.search(curr):
curr = tail_pattern.sub('', curr)
return curr它讓你可以先抽出真正有辨識度的主體名稱,再用更合理的方式做模糊匹配。
推薦hahow線上學習python: https://igrape.net/30afN
 vs iterrows() ; for row in df.itertuples ( index=False, name=None)")
 as c:")
,函數自己呼叫自己,遞迴(Recursive) , dict的value是dict ,巢狀dict,可使用tuple當key,但不可使用list當key")
,或or | , 且and & , 互斥或xor ^ , 反向~ ;位元左移 x << y => 效果同x*(2**y) ; 位元右移 x>>1 => 效果同x//2;x>>16效果同 x//(2**16)")

![Python: pandas.DataFrame如何移除所有空白列?if df_raw.iloc[r,0] is np.nan: nanLst.append(r) ; df_drop0 = df_raw.drop(nanLst,axis=0) ; pandas.isna() ;df_drop0 = df_raw.drop(nanLst,axis=0).reset_index(drop=True)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206144233_67.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?if df_raw.iloc[r,0] is np.nan: nanLst.append(r) ; df_drop0 = df_raw.drop(nanLst,axis=0) ; pandas.isna() ;df_drop0 = df_raw.drop(nanLst,axis=0).reset_index(drop=True)")
,dtype=int) ; B = np.zeros((2,3,4),dtype=int)")
,計算香港保單富衛人壽(FWD)盈聚優裕(UFE1)IRR,免費下載IRR計算機")

![Python: 如何創建多層column name的pandas.DataFrame? df = pd.read_csv ('data.csv', header=[0, 1], sep=",") ; col = pd .MultiIndex .from_arrays( aryCol ) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230314164119_32-520x245.png)

近期留言