什麼是 hashlib?
hashlib 是 Python 內建的雜湊(hash)函式庫,
用來為任意資料產生固定長度的唯一識別碼(指紋)。
常見用途
✅ 檢查檔案完整性(下載後驗證是否損壞)
✅ 密碼儲存(不直接存明文密碼)
✅ 資料去重(快速比對內容是否相同)
✅ 建立唯一識別碼(如 Git commit ID)
- 基本使用:產生雜湊值
import hashlib
# 要雜湊的資料(必須是 bytes)
data = "Hello World".encode('utf-8')
# 使用 SHA-256 演算法
hash_obj = hashlib.sha256(data)
# 取得 16 進位字串
result = hash_obj.hexdigest()
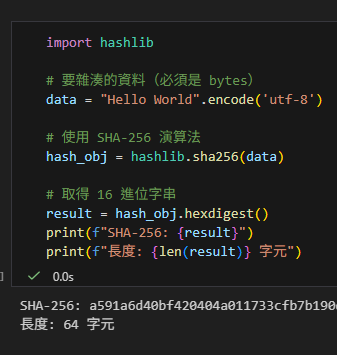
print(f"SHA-256: {result}")
print(f"長度: {len(result)} 字元")輸出:
2. 常用雜湊演算法比較
import hashlib
text = "Python hashlib 教學"
data = text.encode('utf-8')
algorithms = {
'MD5': hashlib.md5,
'SHA-1': hashlib.sha1,
'SHA-256': hashlib.sha256,
'SHA-512': hashlib.sha512,
}
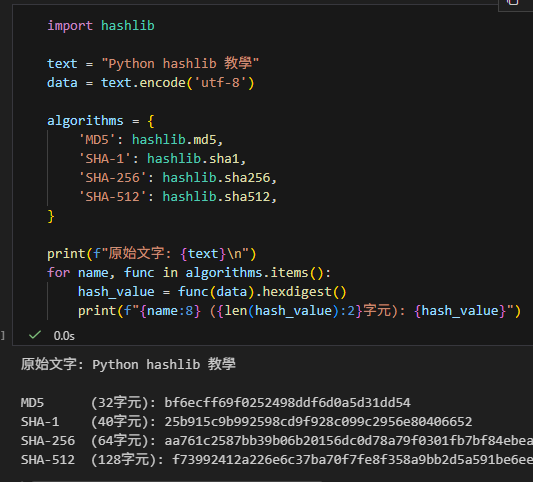
print(f"原始文字: {text}\n")
for name, func in algorithms.items():
hash_value = func(data).hexdigest()
print(f"{name:8} ({len(hash_value):2}字元): {hash_value}")輸出:
演算法選擇建議
3. 實用範例:檔案完整性驗證
import hashlib
def calculate_file_hash(filepath, algorithm='sha256'):
"""計算檔案的雜湊值"""
hash_func = getattr(hashlib, algorithm)()
# 分塊讀取(避免大檔案佔用過多記憶體)
with open(filepath, 'rb') as f:
while chunk := f.read(8192): # 每次讀 8KB
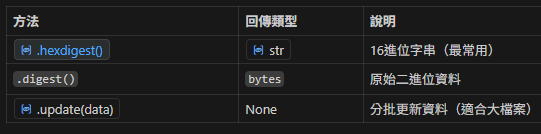
hash_func.update(chunk)
return hash_func.hexdigest()
# 範例:建立測試檔案並計算雜湊值
test_file = 'test_file.txt'
with open(test_file, 'w', encoding='utf-8') as f:
f.write('這是測試內容\n' * 100)
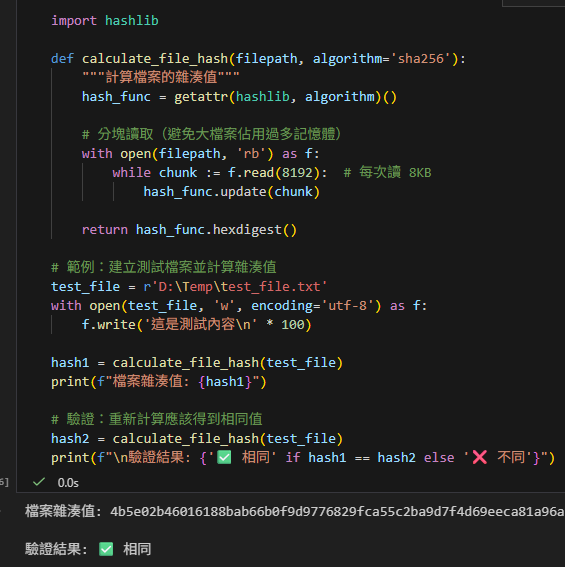
hash1 = calculate_file_hash(test_file)
print(f"檔案雜湊值: {hash1}")
# 驗證:重新計算應該得到相同值
hash2 = calculate_file_hash(test_file)
print(f"\n驗證結果: {'✅ 相同' if hash1 == hash2 else '❌ 不同'}")輸出:
4. 實用範例:建立短指紋
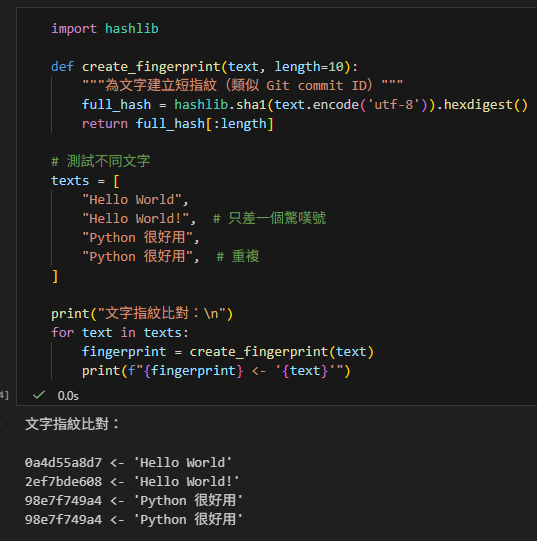
import hashlib
def create_fingerprint(text, length=10):
"""為文字建立短指紋(類似 Git commit ID)"""
full_hash = hashlib.sha1(text.encode('utf-8')).hexdigest()
return full_hash[:length]
# 測試不同文字
texts = [
"Hello World",
"Hello World!", # 只差一個驚嘆號
"Python 很好用",
"Python 很好用", # 重複
]
print("文字指紋比對:\n")
for text in texts:
fingerprint = create_fingerprint(text)
print(f"{fingerprint} <- '{text}'")輸出:
兩種輸出格式比較
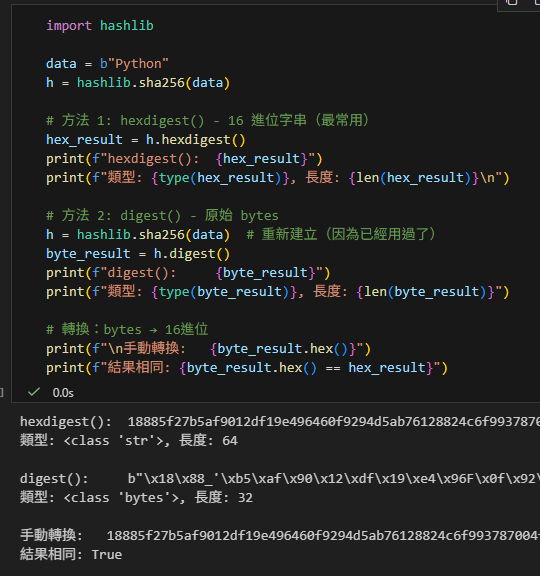
import hashlib
data = b"Python"
h = hashlib.sha256(data)
# 方法 1: hexdigest() - 16 進位字串(最常用)
hex_result = h.hexdigest()
print(f"hexdigest(): {hex_result}")
print(f"類型: {type(hex_result)}, 長度: {len(hex_result)}\n")
# 方法 2: digest() - 原始 bytes
h = hashlib.sha256(data) # 重新建立(因為已經用過了)
byte_result = h.digest()
print(f"digest(): {byte_result}")
print(f"類型: {type(byte_result)}, 長度: {len(byte_result)}")
# 轉換:bytes → 16進位
print(f"\n手動轉換: {byte_result.hex()}")
print(f"結果相同: {byte_result.hex() == hex_result}")hexdigest():
6. 進階:轉換成不同進位
import hashlib
import base64
data = b"Hello"
h = hashlib.sha1(data)
# 16 進位(預設)
hex_hash = h.hexdigest()
print(f"16進位: {hex_hash}")
# 10 進位(整數)
dec_hash = int(hex_hash, 16)
print(f"10進位: {dec_hash}")
# Base64 編碼(更簡潔)
h = hashlib.sha1(data) # 重新建立
b64_hash = base64.b64encode(h.digest()).decode()
print(f"Base64: {b64_hash}")
# 截斷雜湊值(建立短指紋)
short_hash = hex_hash[:10]
print(f"\n短指紋 (前10字元): {short_hash}")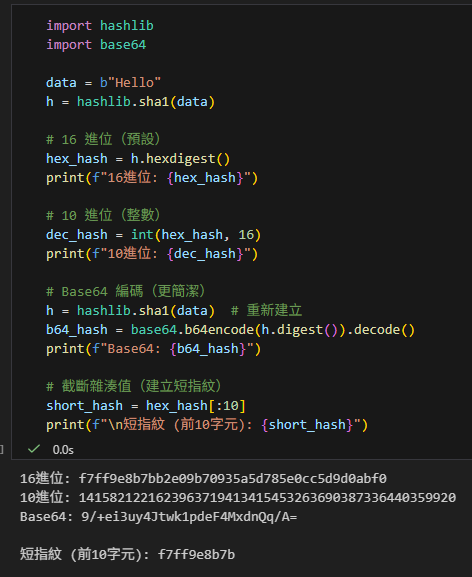
7. 實用範例:內容去重
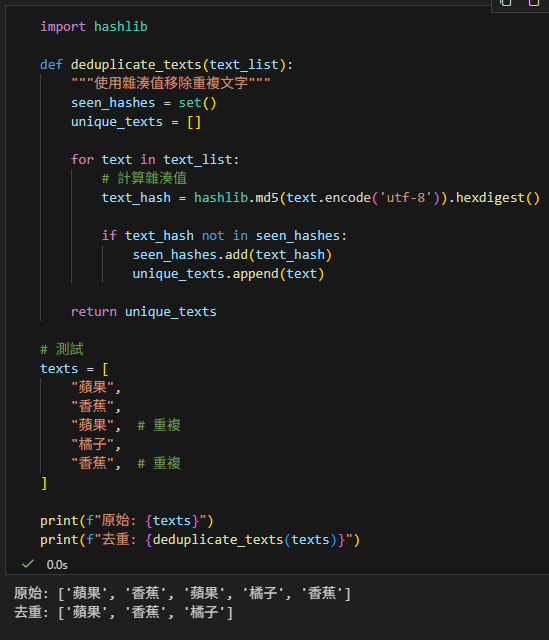
import hashlib
def deduplicate_texts(text_list):
"""使用雜湊值移除重複文字"""
seen_hashes = set()
unique_texts = []
for text in text_list:
# 計算雜湊值
text_hash = hashlib.md5(text.encode('utf-8')).hexdigest()
if text_hash not in seen_hashes:
seen_hashes.add(text_hash)
unique_texts.append(text)
return unique_texts
# 測試
texts = [
"蘋果",
"香蕉",
"蘋果", # 重複
"橘子",
"香蕉", # 重複
]
print(f"原始: {texts}")
print(f"去重: {deduplicate_texts(texts)}")輸出:
重點整理
基本用法
import hashlib
# 1. 準備資料(必須是 bytes)
data = "文字".encode('utf-8')
# 2. 選擇演算法並計算
hash_obj = hashlib.sha256(data)
# 3. 取得結果
result = hash_obj.hexdigest() # 16進位字串關鍵概念
- 📌 相同輸入 → 相同雜湊值(確定性)
- 📌 微小改變 → 完全不同的雜湊值(雪崩效應)
- 📌 無法反推(單向函數)
- 📌 固定長度輸出(無論輸入多長)
常用方法
安全提醒
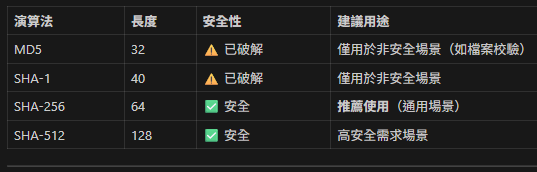
⚠️ 不要用於密碼儲存(應使用 bcrypt 或 argon2)
⚠️ MD5 和 SHA-1 已不安全(僅用於非安全場景)
✅ 推薦使用 SHA-256 或更高版本
推薦hahow線上學習python: https://igrape.net/30afN
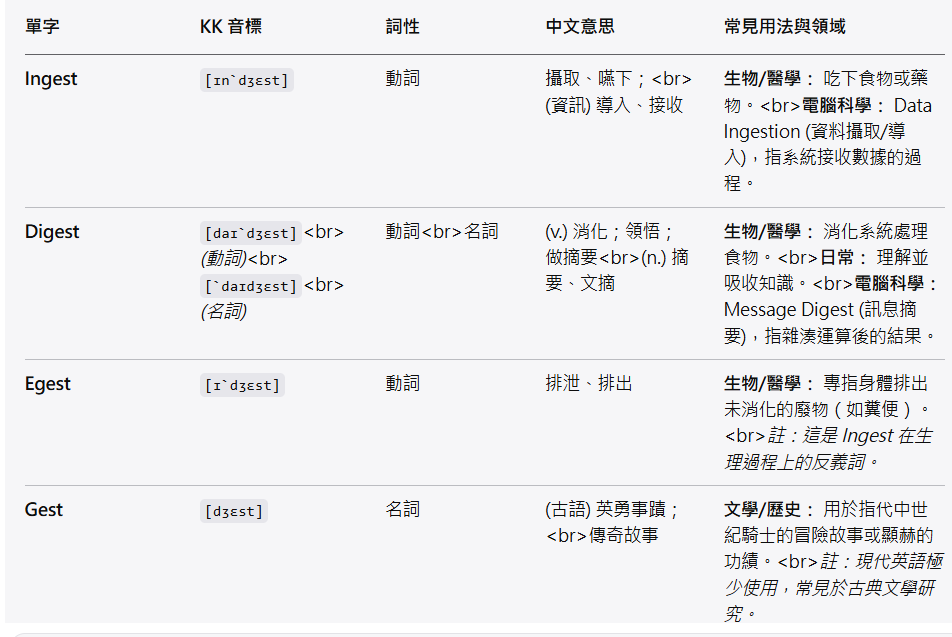
單字比較表 (Ingest, Digest, Egest, Gest)
詞根記憶小撇步
這四個字都源自拉丁語詞根 -gest (來自 gerere),意思是「攜帶」(carry)、「運送」(bear) 或「執行」(perform):
- In- (進入) + gest (運送) = 送進去 → 攝取
- Di- (分開) + gest (運送) = 分開運送/處理 → 消化 (把食物分解)
- E- (向外) + gest (運送) = 送出去 → 排泄
- Gest (行為) = 被執行出來的事情 → 事蹟/故事 (古語)

 ; OrderedDict.fromkeys()")

 順序order,關鍵字keyword,索引index .2% 換算為百分比,精準到小數點下兩位")


, 如何繪製3D散佈圖? spyder無法用滑鼠改變3D圖的視角該如何處理? %matplotlib qt")
")
 , 如何計算IRR? numpy_financial.irr() 免費下載IRR計算機,如何寫入csv檔? csv.writer(f).writerows(2D List) ; if not os.path.exists(folder): os.makedirs(folder)")

近期留言