#Python TQC考題708 詞典合併
“””
#視訊解題其實只用一個辭典
#題目最終結果只要合併辭典,
#解題真的只需要一個辭典
#其他應用若需用到原辭典
#可以參考第二個解法
#使用dict1.update(dict2)合併兩辭典
#非dict3 = dict1.update(dict2)
# dict3會是空值,跟.remove() .pop()類似
708 詞典合併
這兩題都是兩個合併為一個
所以只為解題的話
都可以只用一個做
“””
d={}
for i in range(2):
print(“Create dict%d:”%(i+1))
#dict之後沒有空格,要用%d,不能用逗點
#i從0開始 %(i+1)
while(True):
k=input(“Key: “)
#:後面有空格
if k==”end”:break
v=input(“Value: “)
#:後面有空格
d[k]=v
#用[],非{}
d1=sorted(d)
#只有收集d的key,為一list
for k in d1:
print(“%s: %s” %(k,d[k]))
“””
題目沒有重複key
若有重複key,
dictionary後面輸入的value
會蓋掉前面的value
“””
#第二種作法:
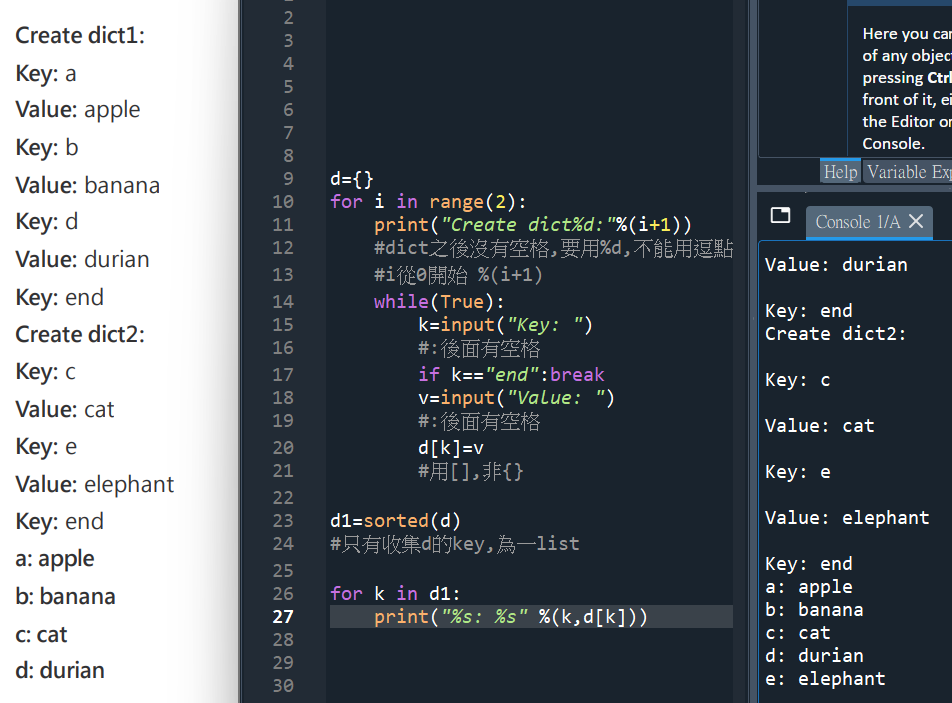
def compute():
dic={}
while True:
key=input(“Key: “)
if key==”end”:
return dic
value=input(“Value: “)
dic[key]=value
#增加字典的元素
print(“Create dict1”)
dict1=compute()
print(“Create dict2”)
dict2=compute()
dict1.update(dict2)
#dict2被dict1合併
dict3=sorted(dict1)
# 跟.sort()不一樣,
# .sort()對原字典排序
# sorted()不影響原字典
#字典無法用.sort()
# 只有key沒有value
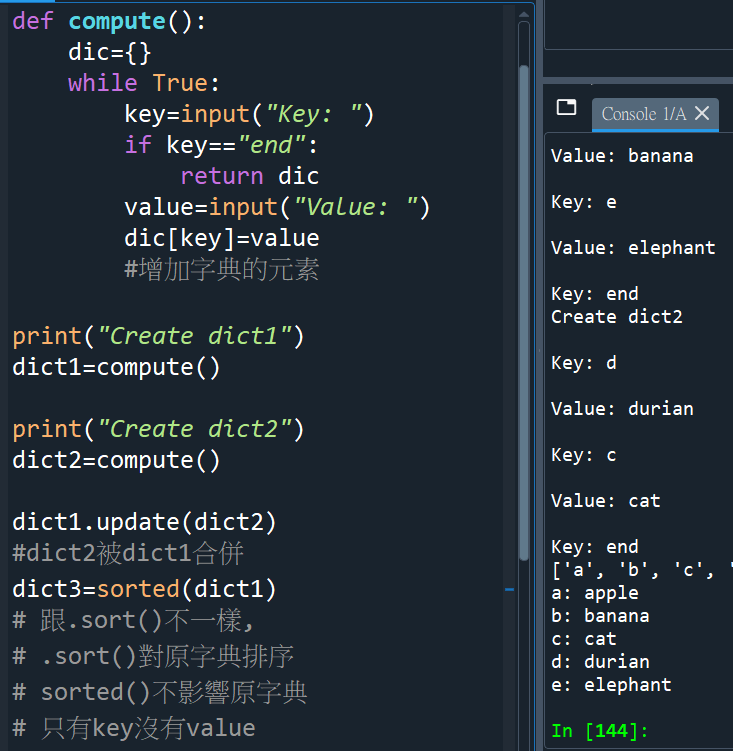
print(dict3)
#只是看看,題目不需要
for i in dict3: #i=a,b,c,d,e
print(“%s: %s” %(i,dict1[i]))
#再練習一次:
#再練習一次:
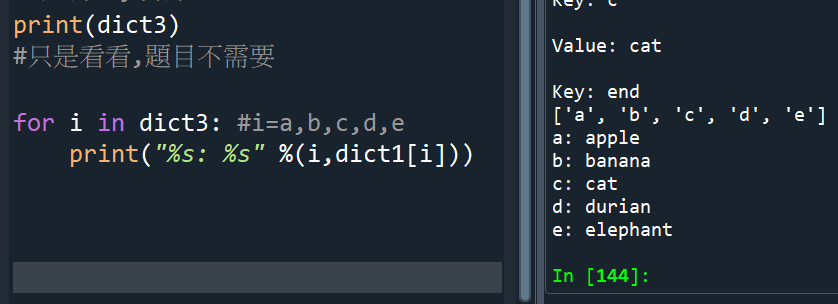
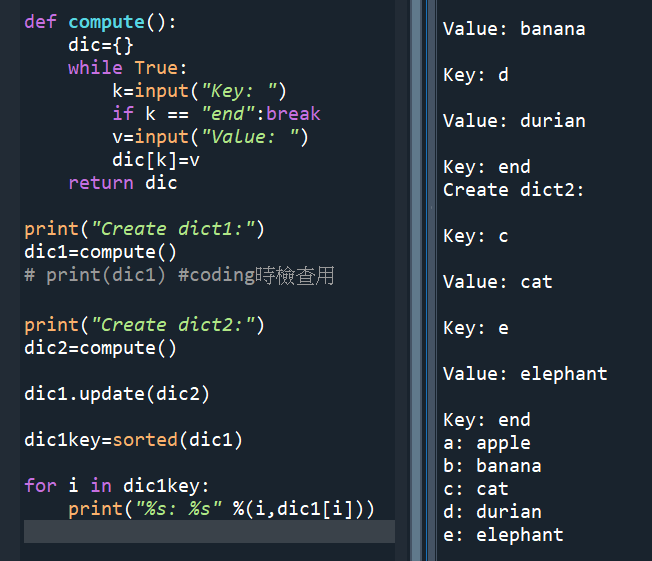
def dic():
dic={}
while True:
k=input(“Key: “)
if k == “end” : break
v=input(“Value: “)
dic[k] = v
return dic #這一行沒有任何:
def main():
print(“Create dict1: “)
dic1 = dic()
print(“Create dict2: “)
dic2 = dic()
dic1.update(dic2)
#非dic1=dic1.update(dic2)
key = sorted(dic1)
for k in key:
print(“%s: %s” \
%(k,dic1[k]))
main()
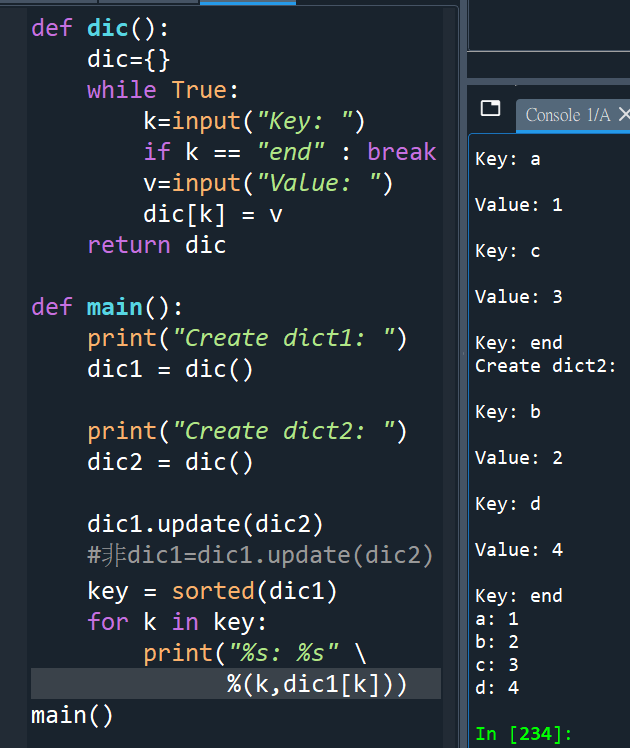
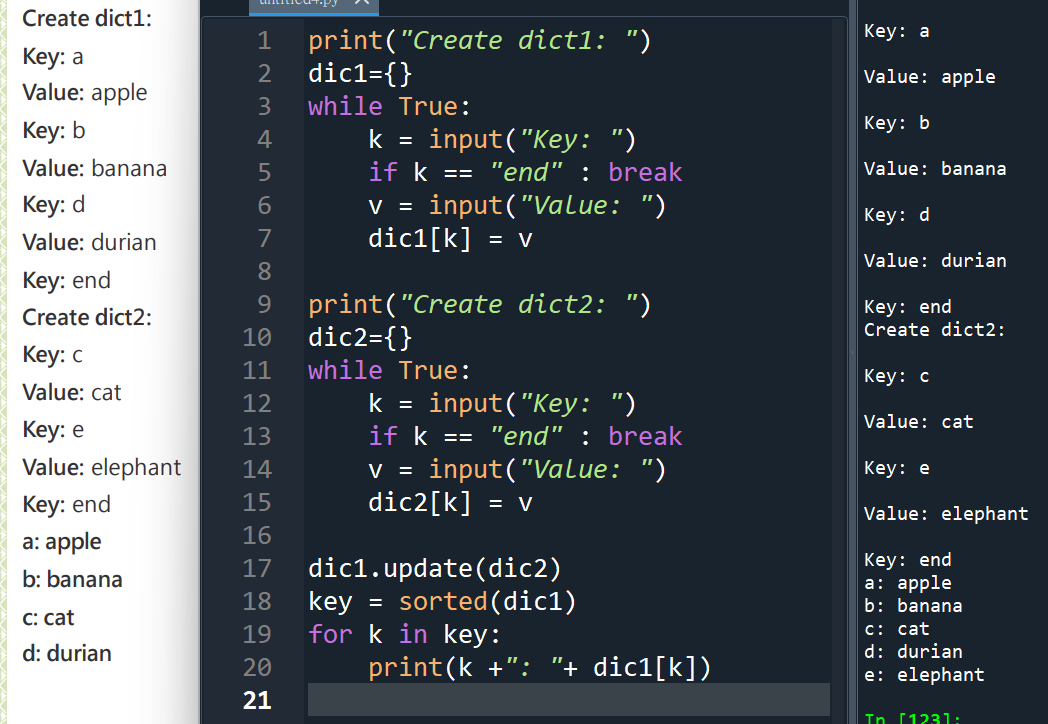
#才兩個dict而已,不一定要用for迴圈
#複製過來,第二個dict改一下很快
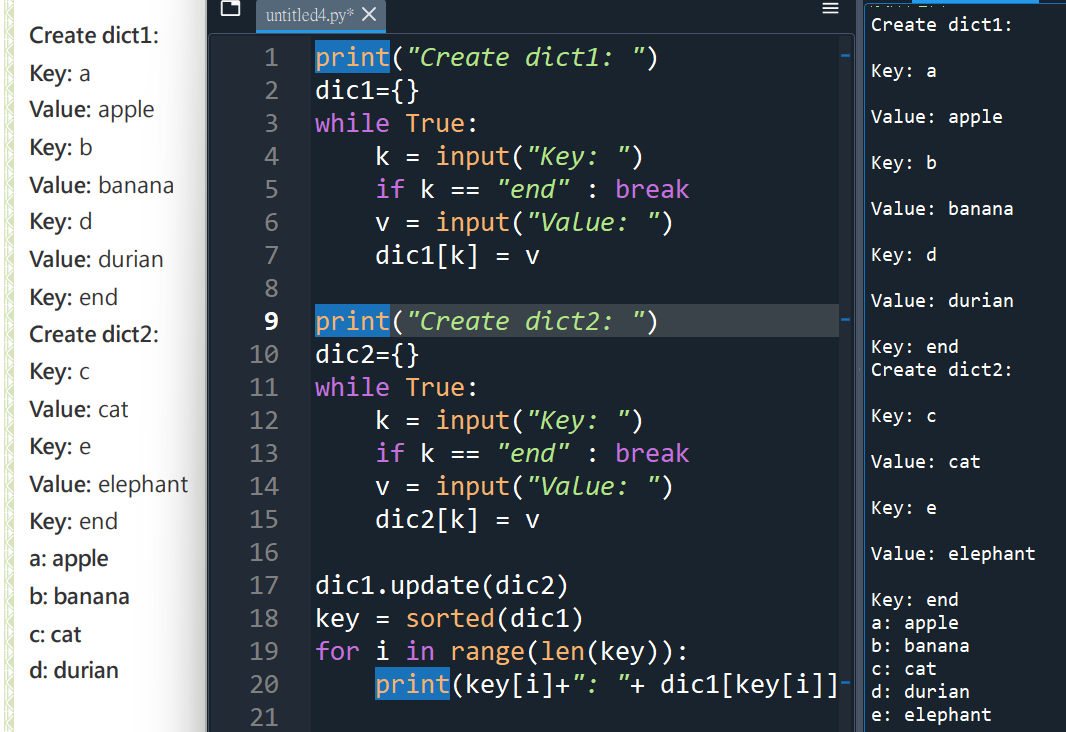
#只要頭腦夠清楚的話
#最後兩行可以改成如下:
 ; 如何將Series依據分隔子(tab與不定數空白混用) 拆分為多欄的DataFrame?")
 處理丟失的數據,如何刪除DataFrame的空列? df3 = df2.reset_index (drop=True) ; df_drop = df3.drop ( nanIdx, axis = 0 ).reset_index( drop = True )")
,dtype=int) ; B = np.zeros((2,3,4),dtype=int)")

: 類別變數 __class__.PI ; 物件變數 self.PI ; 類別方法 @classmethod cls.PI ; 靜態方法 @staticmethod")
) ; reduce( lambda acc, x: acc + x, map(lambda x: x * 2, filter(lambda x: x % 2 == 0, numbers)))")
 的 maxsplit 速懂教學(含常見陷阱與實用對比);如何分割標題號 與 標題文字? “3.1.2 Test Strategy”.split(maxsplit=1) #注意中間無底線: 非max_split")


![Python如何做excel的樞紐分析? groupbyObj = df.groupby(['A', 'B']) ; groupbyObj.apply() 跟 groupbyObj.agg() 差異為何? result = groupbyObj .apply( function(df) -> Series ) ; result_agg = groupbyObj .agg( ['mean', 'std'] ) ; aggfunc(Series) -> float - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230327140158_46-520x245.png)

近期留言