df1 = pd.DataFrame( [[“frame_number:”,frame_number,”迴圈:”,cnt,””,””]] )
#用了[[ ]]
df2 = pd.DataFrame( [“frame_number:”,frame_number,”迴圈:”,cnt,””,””] )
#用[ ]
#frame_number , cnt皆為宣告過的變數
![Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230313160116_63.png)
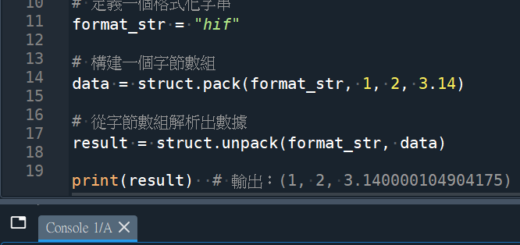
這兩者之間的差異在於傳遞給pd.DataFrame()的參數是不同的。
第一個例子中,傳遞了一個包含一個列表的列表。
即 [[“frame_number:” , frame_number , “迴圈:” , cnt , “” , “” ]],
這個列表裡面只有一個元素(一個元素就一列),
元素也是一個列表,
包含了要插入DataFrame中的值。
而第二個例子中,傳遞了一個包含6個值的列表。
即 [“frame_number:”, frame_number , “迴圈:” , cnt , “” , “” ],
這個列表中的每個值都會被當作一個單獨的元素
(6個元素就6列)
插入到DataFrame的一個row中。
因此,第一個例子中的df1會是一個只有一個row,
但這個row包含一個列表,
這個列表包含了所有的要插入DataFrame中的值。
而第二個例子中的df2會有6個row
若想要用concat() 將DataFrame 增加首列
記得要用[[ ]]
推薦hahow線上學習python: https://igrape.net/30afN
 #Bytes → Element Object 與 lxml.etree.tostring(Element, encoding= “utf-8”) #Element Object → Bytes ; lxml.etree._Element; 處理 XML 時,盡量全程保持 Bytes (二進位) 狀態。")

 ; 如何將Series依據分隔子(tab與不定數空白混用) 拆分為多欄的DataFrame?")

")






近期留言