Vlookup是Excel常用到的函數
該如何使用呢?
先看看微軟的說明:

前面三個參數應該都看得懂
但第四個參數可能看得很模糊
先來示範一下Vlookup如何使用:
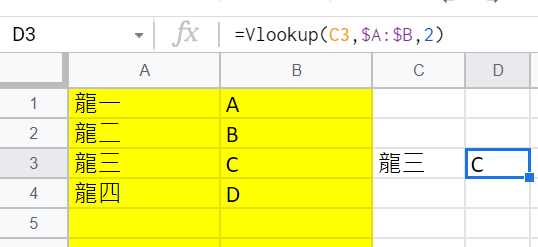
D3儲存格中輸入Vlookup公式如下:
=Vlookup(C3,$A:$B,2)
搜尋C3儲存格(龍三)
若出現在參考表格中,
回傳參考表格的第2欄資料(C)
第四個參數省略,
表示預設值TURE(1)
這時候沒看出什麼異樣
搜尋結果為C
但把參考表格資料的順序調換一下
再看一次
一模一樣的函數會出現什麼狀況
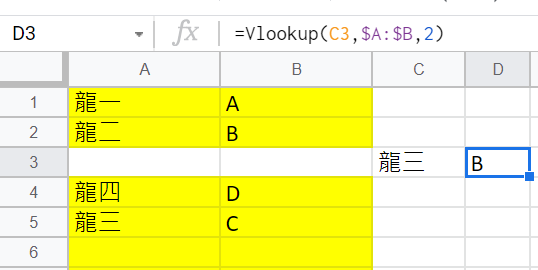
=Vlookup(C3,$A:$B,2)
這個公式都沒變過
但搜尋結果卻變成B
驚不驚喜?意不意外?
為了避免這麼意外的搜尋結果
Vlookup函數第四個參數
都會補上FALSE或0:
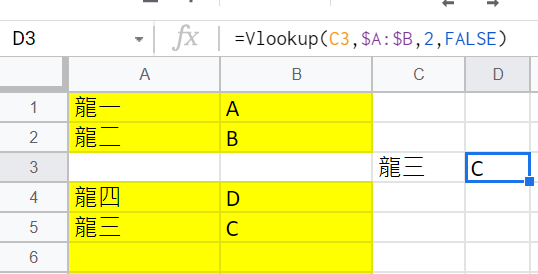
第四個參數補上FALSE後(完全符合),
終於顯示期待的搜尋結果C
一般狀況也都是這樣用
所以結尾幾乎是一定要補上FALSE (0)
其實微軟應該設計FALSE(0)為預設值
一般人比較不會出錯
新出的xlookup函數
預設就是0
而且改稱: match mode
什麼情況才會用到TRUE?

微軟的說明只能說完全是誤導
什麼叫做大約符合?
無怪乎一般人都不懂TRUE的用法
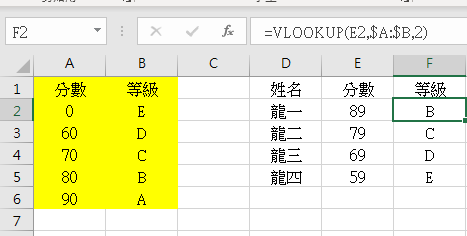
以下舉例TRUE參數正確的用法
4名學生各得不同的4個分數
90分以上,評級A
80~90分,評級B
70~80分,評級C
60~70分,評級D
0~60分,評級E
這時候TRUE參數(省略)
就可以完美應用了:
此時若用FALSE參數
表格中沒有任何一個精準符合的項目
會出現 #N/A
使用TRUE(1或省略)參數
首先,參考表格中的第一欄
必須以遞增順序排序
再看一次微軟誤導的說明:
大約符合已經完全誤導了
89分這麼接近90分,
大約符合的話,為何不是顯示A?
後面小小字的暗示
你一定沒注意到:
table array首欄的值
必須以遞增順序排序
Excel會依序比對第一欄的數字
比參考值高的話就跳過
直到比參考值低,
便顯示前一列的資料
上圖龍一89分為例
89>0,跳過
89>60,跳過
89>70,跳過
89>80,跳過
直到89<90
便顯示前一列80分的資料(B)
上圖為何搜尋錯誤呢?
即使是文字
還是有大小的
表格第一欄沒有從小排到大
龍三>龍一,跳過
龍三>龍二,跳過
直到龍三<龍四
顯示前一列龍二的資料(B)
打完收工
即使精準的龍三就在下幾列而已
Excel也不再理會
你知道為何老是搜尋錯誤嗎?
請記得最後一個參數
FALSE(完全符合)
不要漏了

與逆向檔案頻率(Inverse Document Frequency,簡稱 IDF)?")
")
")
 ; extend() 的差別為何? extend()配合zip()超好用")


![Python 進階實戰:深入 Word 核心,挖出那一坨 BLOB (含自省 Debug 技巧, BLOB= Binary Large Object) ; part = doc.part.rels[rid].target_part ; return part.blob if “ImagePart” in type(part).__name__ else None](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260126111046_0_cd8751.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 進階實戰:深入 Word 核心,挖出那一坨 BLOB (含自省 Debug 技巧, BLOB= Binary Large Object) ; part = doc.part.rels[rid].target_part ; return part.blob if “ImagePart” in type(part).__name__ else None")
![Python Pathlib 實戰:優雅地篩選多種圖片檔案; images = [f for f in p.glob("*") if f.suffix.lower() in img_extensions] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/01/20260128111659_0_736612-520x245.png)
![Python: matplotlib如何設定座標軸刻度? plt.xticks(seq, labels) ;如何生成fig, ax物件? fig = plt.figure(figsize= (10.24, 7.68)) ; ax = fig.add_subplot() ; fig, ax = plt.subplots(figsize=(10.24, 7.68)) ; 如何使用中文? plt.rcParams["font.family"] = ["Microsoft JhengHei"] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/02/20230209083006_41-520x245.png)

近期留言