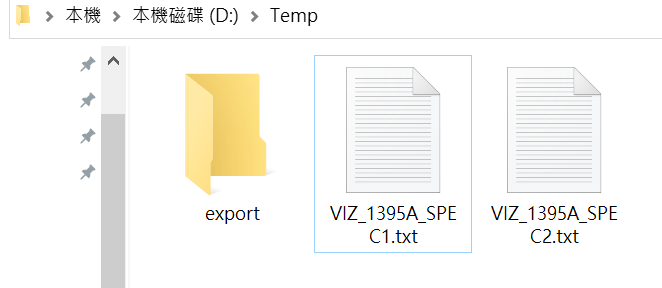
d:\Temp 資料夾
底下的檔案如下:
code:
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 4 18:26:15 2023
@author: SavingKing
"""
import glob
import os
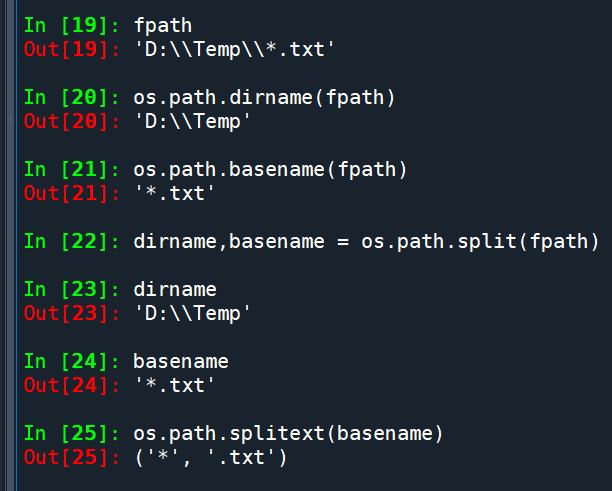
dirname = r"D:\Temp" #使用者自行修改
basename ="*.txt" #使用者自行修改
fpath = os.path.join(dirname , basename)
#'D:\\Temp\\*.txt'
original_str = "ex_pn" #使用者自行修改
new_str = "VIZ_1395A" #使用者自行修改
lis_fpath = glob.glob(fpath)
# ['D:\\Temp\\ex_pn_SPEC1.txt', 'D:\\Temp\\ex_pn_SPEC2.txt']
# lis_new_path = []
for path in lis_fpath:
new_path = path.replace(original_str , new_str)
# lis_new_path.append(new_path)
os.rename(path , new_path)程式執行後:
順便示範以下幾個函式:
推薦hahow線上學習python: https://igrape.net/30afN


 or(|) xor(^) not")
:使用 ignore_index=True 合併 DataFrame 的奧秘 #效果同 reset_index( drop=True )")
; ip addr ; hostname -I查詢ip address")
 搜尋元素位於list中的那一個index")
,Skip Record If")
 讀取csv檔案?若該檔案奇異列長度太短,如何用try:~except:~避免取直欄時出現IndexError: list index out of range?")
![Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221112184006_50.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str]")


近期留言