為什麼需要copy?

b=a ,將a賦值給b
一般人會以為已經copy了一份
實際上a, b兩變數共享同一個內存地址
b一旦變更
會影響到a也一起變更
上例 a = [1, 2, 3]
b = a.copy() #對a進行淺拷貝:
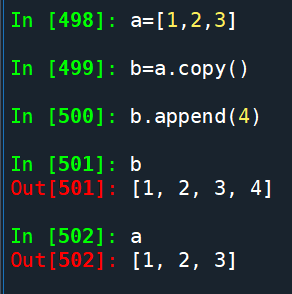
b.append(4)
對b進行了變更
a仍是原本的[1, 2, 3]
沒有影響到
a = [[1, 2, 3], {‘a’: 1, ‘b’: 2}]
a為一個list
list中的元素有list, dict
而非 整數,浮點數,字串 (不可變類型)
一樣做淺拷貝的動作:

對b[0]做了變更
一併影響到a
這時候就需要使用深拷貝(deep copy)
b = copy.deepcopy(a)

推薦hahow線上學習python: https://igrape.net/30afN
 as f: for line in f: lst = line.split()")
 只能判斷float的np.nan; pandas.isna()不只可以判斷np.nan 還可以判斷pd.NA ,pd.NaT, None")
")
 ; .localtime() ; .tm_year ; .tm_mon ; .tm_mday ; .ctime() #current time ; .sleep() ;time.asctime() #as string ; time.strftime() #string format time")
 ; spyder無法用滑鼠改變3D圖的視角該如何處理? %matplotlib qt")
 vs jieba.lcut() 使用指南")
, candidates, n=1, cutoff=0.6)")

![Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/06/20250609143758_0_53821c.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )")

近期留言