int8 |
8 位元有號整數 |
int16 |
16 位元有號整數 |
int32 |
32 位元有號整數 |
int64 |
64 位元有號整數 |
uint8 |
8 位元無號整數 |
uint16 |
16 位元無號整數 |
uint32 |
32 位元無號整數 |
uint64 |
64 位元無號整數 |
float16 |
16 位元浮點數 |
float32 |
32 位元浮點數 |
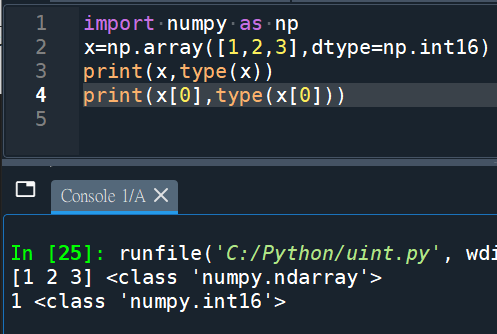
import numpy as np
x=np.array([1,2,3],dtype=np.int16)
print(x,type(x))
print(x[0],type(x[0]))
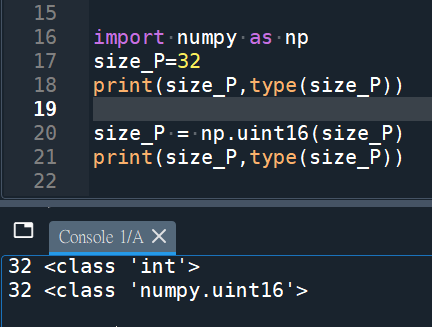
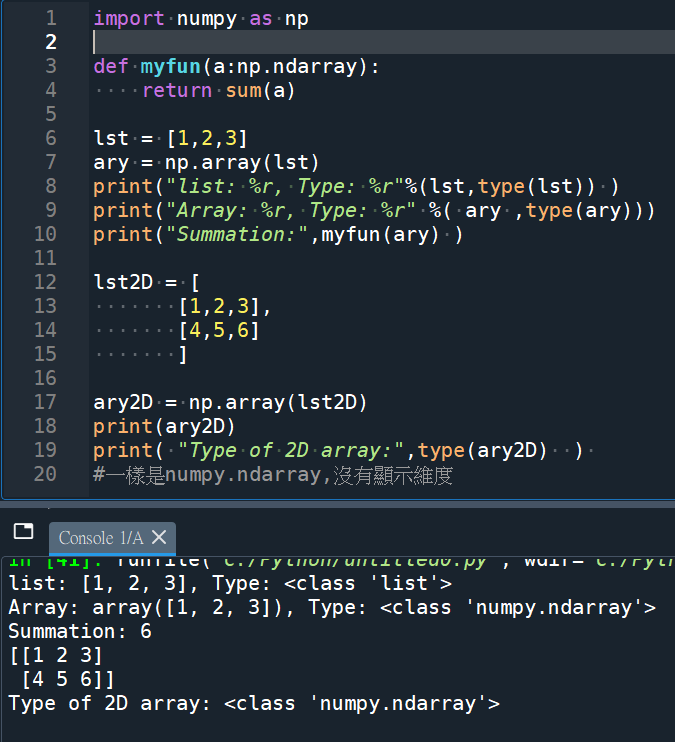
import numpy as np
def myfun(a:np.ndarray):
return sum(a)
lst = [1,2,3]
ary = np.array(lst)
print(“list: %r, Type: %r”%(lst,type(lst)) )
print(“Array: %r, Type: %r” %( ary ,type(ary)))
print(“Summation:”,myfun(ary) )
lst2D = [
[1,2,3],
[4,5,6]
]
ary2D = np.array(lst2D)
print(ary2D)
print( “Type of 2D array:”,type(ary2D) )
#一樣是numpy.ndarray,沒有顯示維度

")


 as s: s.attr(rank=’same’) 如何使用U形排列,營造出node下方有label的效果?取代xlabel功能")

 讀取csv檔案?若該檔案奇異列長度太短,如何用try:~except:~避免取直欄時出現IndexError: list index out of range?")
![Python: 如何將pandas.DataFrame從寬資料轉為長資料? df_melt = pd.melt(df, id_vars=[‘name’, ‘gender’], var_name=’time’, value_name=’score’) ; seaborn繪圖](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230302152215_95.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何將pandas.DataFrame從寬資料轉為長資料? df_melt = pd.melt(df, id_vars=[‘name’, ‘gender’], var_name=’time’, value_name=’score’) ; seaborn繪圖")
![Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2025/06/20250609143758_0_53821c.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )")


近期留言