在 Python 中,關鍵字參數的區分大小寫是預設行為,無法直接更改。然而,您可以在函數中處理關鍵字參數時,將其轉換為統一的大小寫形式,以達到不區分大小寫的效果。
以下是一個示例,展示了如何在函數中處理不區分大小寫的關鍵字參數:
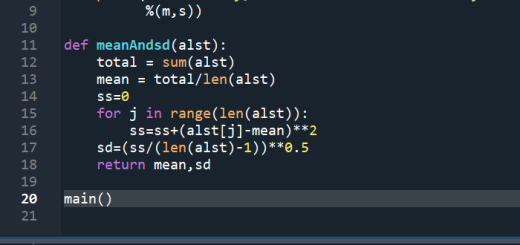
def my_function(**kwargs):
processed_kwargs = {key.lower(): value for key, value in kwargs.items()}
# 在這裡使用 processed_kwargs 來處理參數
# 示例: 打印所有參數的值
for key, value in processed_kwargs.items():
print(f"{key}: {value}")
# 測試函數
my_function(Foo=10, BAR="Hello", baz=True)輸出結果:

#Foo , BAR統一變成小寫
推薦hahow線上學習python: https://igrape.net/30afN
 as plt; from pylab import *")




,計算香港保單富衛人壽(FWD)盈聚優裕(UFE1)IRR,免費下載IRR計算機")
![Word短篇文件編輯,TQC考題110:重點摘要與評量, \[(*)\] 萬用字元,格式>醒目提示*2次=非醒目提示](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/03/20220322172253_75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Word短篇文件編輯,TQC考題110:重點摘要與評量, \[(*)\] 萬用字元,格式>醒目提示*2次=非醒目提示")
")
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f”.//{ qn(‘a:blip’) }” ) ; .get( qn(“r:embed”) ) #獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’) ; lxml.etree._Element.xpath( “//a:blip/@r:embed”, namespaces = NS) #/@r:embed = 獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用”//a:blip/@r:embed” ,可直接獲取屬性值(List[str]如: [‘rId4’, ‘rId5’]) ; 如何對docx真實移除圖片瘦身?](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2025/11/20251119130848_0_3fbf6b.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f”.//{ qn(‘a:blip’) }” ) ; .get( qn(“r:embed”) ) #獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’) ; lxml.etree._Element.xpath( “//a:blip/@r:embed”, namespaces = NS) #/@r:embed = 獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用”//a:blip/@r:embed” ,可直接獲取屬性值(List[str]如: [‘rId4’, ‘rId5’]) ; 如何對docx真實移除圖片瘦身?")


近期留言