test_flow中有
wait 30 sec
wait 60 sec…
可能還有更多
只要含有wait這個關鍵字
就要過濾掉
blacklist = [“wait”]
沒有寫得很詳細
[“wait 30 sec”,”wait 60 sec”]
如何過濾掉含有wait關鍵字的step?
code:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 16 07:22:55 2024
@author: SavingKing
"""
# 定義測試流程的列表
test_flow = ["step 1", "wait 30 sec", "step 2", "wait 60 sec", "step 3"]
# 定義黑名單詞匯
blacklist = ["wait"]
# 創建一個空列表用於存放過濾後的步驟
filtered_flow = []
# 創建一個空列表用於收集被黑名單過濾掉的步驟
blacklisted_steps = []
# 遍歷原始的測試流程列表
for step in test_flow:
# 檢查當前步驟是否包含黑名單中的詞匯
contains_blacklisted_word = False
for black_word in blacklist:
if black_word in step:
contains_blacklisted_word = True
break # 如果發現黑名單詞匯,中斷內層循環
# 如果當前步驟不包含任何黑名單詞匯,則添加到過濾後的列表中
if not contains_blacklisted_word:
filtered_flow.append(step)
else:
# 如果包含黑名單詞匯,將該步驟添加到黑名單過濾列表中
blacklisted_steps.append(step)
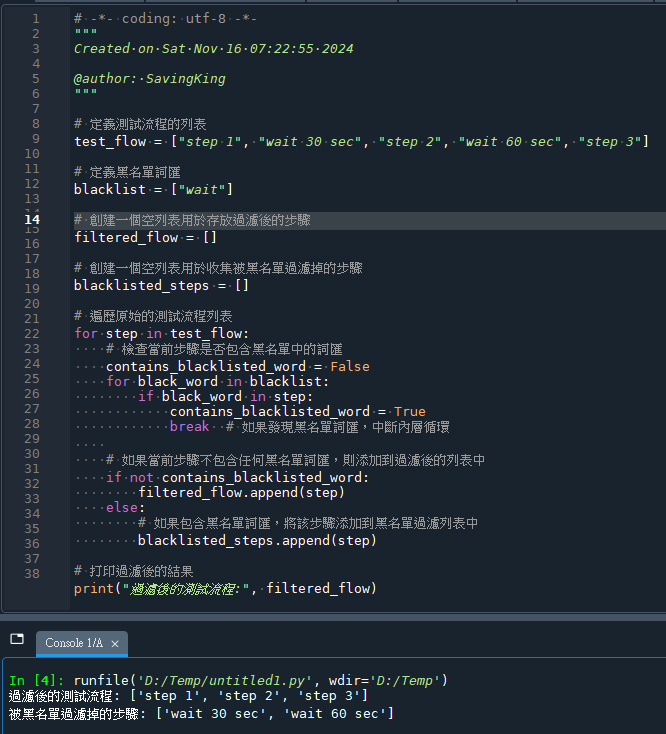
# 打印過濾後的結果
print("過濾後的測試流程:", filtered_flow)
# 打印被黑名單過濾掉的步驟
print("被黑名單過濾掉的步驟:", blacklisted_steps)代碼解釋:
初始化列表:除了原本的 filtered_flow 用於存放過濾後的步驟之外,新增一個 blacklisted_steps 列表用來收集被黑名單詞匯過濾掉的步驟。
循環處理:遍歷每一個步驟,並檢查是否包含黑名單中的詞匯。
黑名單檢查:通過內層循環和布爾變量 contains_blacklisted_word 進行黑名單詞匯的檢查。
分類收集:根據步驟是否包含黑名單詞匯,將步驟分別添加到 filtered_flow 或 blacklisted_steps 列表中。
輸出結果:最後分別打印過濾後的步驟和被黑名單過濾掉的步驟,以供用戶確認。
這種方法可以清晰地將需要的信息展示給用戶,方便用戶了解哪些步驟被保留,哪些被過濾掉,從而做出相應的決策或調整。
輸出結果:
推薦hahow線上學習python: https://igrape.net/30afN
用def function修改得更結構化:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 16 07:22:55 2024
@author: SavingKing
"""
# 定義測試流程的列表
test_flow = ["step 1", "wait 30 sec", "step 2", "wait 60 sec", "step 3"]
# 定義黑名單詞匯
blacklist = ["wait"]
def judge_black_word(step,blacklist = ["wait"]):
judge=False
for black_word in blacklist:
if black_word in step:
judge=True
break
return judge
# 創建一個空列表用於存放過濾後的步驟
filtered_flow = []
# 創建一個空列表用於收集被黑名單過濾掉的步驟
blacklisted_steps = []
# 遍歷原始的測試流程列表
for step in test_flow:
# 檢查當前步驟是否包含黑名單中的詞匯
# contains_blacklisted_word = False
# for black_word in blacklist:
# if black_word in step:
# contains_blacklisted_word = True
# break # 如果發現黑名單詞匯,中斷內層循環
# 如果當前步驟不包含任何黑名單詞匯,則添加到過濾後的列表中
if not judge_black_word(step,blacklist = ["wait"]):
filtered_flow.append(step)
else:
# 如果包含黑名單詞匯,將該步驟添加到黑名單過濾列表中
blacklisted_steps.append(step)
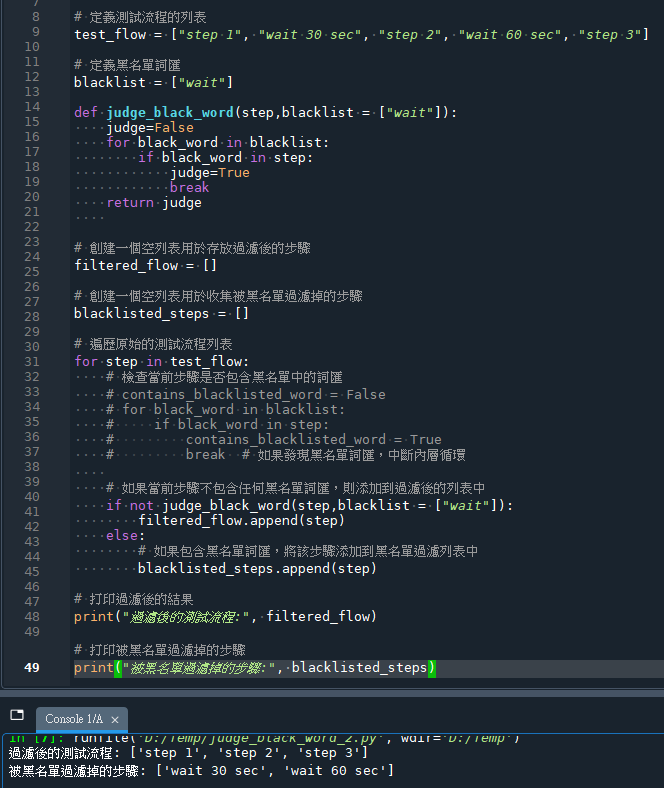
# 打印過濾後的結果
print("過濾後的測試流程:", filtered_flow)
# 打印被黑名單過濾掉的步驟
print("被黑名單過濾掉的步驟:", blacklisted_steps)輸出結果:
定義測試流程的列表 (test_flow):包含了一系列的步驟,部分步驟中包含黑名單中的詞匯。
定義黑名單詞匯 (blacklist): 這是一個列表,包含了需要過濾掉的關鍵詞。
judge_black_word 函數:此函數接收一個步驟和一個黑名單列表,返回布爾值,指示步驟是否包含黑名單中的任何詞匯。
過濾列表的創建 (filtered_flow 和 blacklisted_steps):分別用於存放過濾後的步驟和被黑名單過濾掉的步驟。
遍歷和過濾:通過遍歷 test_flow 中的每個步驟,並使用 judge_black_word 函數判斷是否包含黑名單詞匯,根據判斷結果將步驟添加到相應的列表中。
輸出結果:打印過濾後的步驟和被過濾掉的步驟。
進行了一些簡化和注釋的優化:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 16 07:22:55 2024
@author: SavingKing
"""
# 定義測試流程的列表
test_flow = ["step 1", "wait 30 sec", "step 2", "wait 60 sec", "step 3"]
# 定義黑名單詞匯
blacklist = ["wait"]
def judge_black_word(step, blacklist):
"""檢查步驟中是否包含黑名單中的詞匯"""
return any(black_word in step for black_word in blacklist)
# 創建用於存放過濾後步驟和黑名單步驟的列表
filtered_flow = []
blacklisted_steps = []
# 遍歷原始的測試流程列表
for step in test_flow:
if not judge_black_word(step, blacklist):
filtered_flow.append(step)
else:
blacklisted_steps.append(step)
# 打印過濾後的結果
print("過濾後的測試流程:", filtered_flow)
print("被黑名單過濾掉的步驟:", blacklisted_steps)原本使用for loop ,
只要有一個True 就break跳離loop,
現在使用any,
會不會完整地生成List[bool] 後,
any才做判斷?
效率上會不會有差別?
在 Python 中,any() 函數和列表推導(或生成器表達式)的組合會有不同的效能表現,這取決於具體的實現方式。
any() 函數和生成器表達式
當 any() 函數與生成器表達式一起使用時,它實際上是按需評估的(惰性求值)。生成器表達式會逐個生成元素,並且 any() 會在找到第一個 True 值時立即停止進一步的叠代。這種方式不需要先生成整個布爾列表,因此可以節省內存並可能提高效率。
示例
考慮以下使用生成器表達式的代碼:
def judge_black_word(step, blacklist):
"""檢查步驟中是否包含黑名單中的詞匯"""
return any(black_word in step for black_word in blacklist)這里,(black_word in step for black_word in blacklist) 是一個生成器表達式,它會逐個產生布爾值。any() 函數會逐個從生成器接收值,並在接收到第一個 True 時停止,不會繼續處理剩余的項。
效率對比
相對於先構建完整的布爾列表再傳遞給 any(),使用生成器表達式通常會更高效,特別是在黑名單列表較大或步驟字符串較長時。生成完整的布爾列表(例如通過列表推導)會涉及到更多的內存使用和計算,即使找到了滿足條件的元素也需要完成整個列表的構建。
錯誤的實現示例(較低效)
如果使用列表推導,代碼將如下所示:
def judge_black_word(step, blacklist):
"""檢查步驟中是否包含黑名單中的詞匯"""
return any([black_word in step for black_word in blacklist])這種方式首先會構建一個完整的布爾列表,然後 any() 函數會處理這個列表。如果黑名單中的關鍵詞很早就被找到,這種方法仍然會完成整個列表的構建,這是不必要的計算和內存使用。
結論
使用生成器表達式配合 any() 是一個效率較高的方法,它避免了不必要的資源使用,尤其是在可能早期就找到匹配項的場景中。這種惰性求值方式是處理此類問題的推薦方法。
推薦hahow線上學習python: https://igrape.net/30afN
下面是對代碼的一些修改,以簡化 judge_black_word 函數和使用列表推導來創建 filtered_flow 和 blacklisted_steps 列表。這樣做可以使代碼更加簡潔,同時保持高效和易於閱讀:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 16 07:22:55 2024
@author: SavingKing
"""
# 定義測試流程的列表
test_flow = ["step 1", "wait 30 sec", "step 2", "wait 60 sec", "step 3"]
# 定義黑名單詞匯
blacklist = ["wait"]
def judge_black_word(step, blacklist=["wait"]):
return any(black_word in step for black_word in blacklist)
# 使用列表推導過濾步驟
filtered_flow = [step for step in test_flow if not judge_black_word(step)]
blacklisted_steps = [step for step in test_flow if judge_black_word(step)]
# 打印過濾後的測試流程
print("過濾後的測試流程:", filtered_flow)
# 打印被黑名單過濾掉的步驟
print("被黑名單過濾掉的步驟:", blacklisted_steps)函數 judge_black_word:
使用生成器表達式簡化了原先的循環和條件判斷邏輯,使函數在一行內完成了判斷邏輯。
any() 函數在這里檢查是否有任何 black_word 存在於步驟 step 中,一旦發現就返回 True。
列表推導:
filtered_flow 通過列表推導創建,包括那些不含黑名單詞匯的步驟。
blacklisted_steps 也是用列表推導創建,包括含有黑名單詞匯的步驟。
這種方式使得代碼更加緊湊和符合 Pythonic 風格。
通過這種方式,我們可以有效地在較少的代碼行數中實現功能,同時保持代碼的可讀性和效率。
推薦hahow線上學習python: https://igrape.net/30afN
filtered_flow = [step for step in test_flow if all(black_word not in step for black_word in blacklist)]
blacklisted_steps = [step for step in test_flow if not all(black_word not in step for black_word in blacklist)]列表推導:通過 [step for step in test_flow if …] 生成一個新的列表,其中只包含不包含黑名單詞匯的步驟。
條件 all(black_word not in step for black_word in blacklist):對於每個步驟 step,生成器表達式 black_word not in step for black_word in blacklist 為黑名單中的每個詞匯生成一個布爾值,表示該黑名單詞匯是否不在步驟中。all() 函數檢查這些布爾值是否全部為 True(即步驟中不含有任何黑名單詞匯),只有當所有黑名單詞匯都不在步驟中時,該步驟才被包含在最終結果中。
可以使用 any() 函數來改寫 blacklisted_steps 的列表推導,使其更符合邏輯的直覺和可能提高代碼的可讀性。any() 函數在遇到其參數中的任何一個為 True 時立即返回 True,這對於檢查是否至少有一個黑名單詞匯存在於步驟中是非常合適的。
使用 any() 改寫
下面是如何使用 any() 來重寫 blacklisted_steps:
# 過濾出不包含任何黑名單詞匯的步驟
filtered_flow = [step for step in test_flow if all(black_word not in step for black_word in blacklist)]
# 使用 any() 改寫,過濾出包含至少一個黑名單詞匯的步驟
blacklisted_steps = [step for step in test_flow if any(black_word in step for black_word in blacklist)]推薦hahow線上學習python: https://igrape.net/30afN
 ; glob.glob() #讀取資料夾中的所有檔案 ; os.path.split(fpath) = os.path.dirname(fpath) , os.path.basename(fpath) ; os.path.splitext(basename) #分離主/副檔名")
,計算新光人壽增有利IRR,免費下載IRR計算機")
")
![Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler(‘app.log’, mode=’a’, encoding=’utf-8′)] ) ; inspect.currentframe().f_code.co_name #動態取得funcName](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2025/10/20251021155823_0_c16012.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler(‘app.log’, mode=’a’, encoding=’utf-8′)] ) ; inspect.currentframe().f_code.co_name #動態取得funcName")
,插入>快速組件>功能變數>StyleRef")
")
 as s: s.attr(rank=’same’) 如何使用U形排列,營造出node下方有label的效果?取代xlabel功能")
")
")
![Python如何做excel的樞紐分析? DataFrame .pivot_table (values=None, index=None, columns=None, aggfunc='mean') ; df.groupby(['A', 'B', 'C'], sort=False)['D'].sum().unstack('C') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230325141855_86-520x245.png)


近期留言