本教學將帶領您使用 Python 的 `openai` 套件,建立一個能夠兼容 Azure OpenAI、標準 OpenAI 以及 Poe (GPT-5/Claude 等) 的通用視覺客戶端。
由於這些平台都遵循 (或相容) OpenAI 的 API 格式,透過簡單的配置切換,我們可以用同一套程式碼邏輯來處理 OCR (光學字元辨識) 或圖片描述任務。
> **注意**:Google Gemini 原生 API (GenAI SDK) 語法差異較大,本篇教學將專注於 **OpenAI 相容介面** 的實作。
—
## 1. 環境準備
首先,由於 `AzureOpenAI` 與 `OpenAI` 客戶端都包含在官方套件中,請確保已安裝:
pip install openai## 2. 建立 Client 端 (Client Initialization)
雖然核心方法都是 `chat.completions.create`,但初始化的參數略有不同。我們可以透過一個統一的介面來管理這些差異。
### A. 標準 OpenAI (自費/官方)
這是最標準的用法,只需要 API Key。
from openai import OpenAI
# 初始化
client = OpenAI(api_key="sk-proj-...")
# 選一個「支援視覺」的模型名稱
model_name = "gpt-4.1-mini"### B. Azure OpenAI (企業/公司用)
Azure 需要額外的 `endpoint` 與 `api_version`。
from openai import AzureOpenAI
client = AzureOpenAI(
api_key="你的_azure_api_key",
api_version="2024-12-01-preview", # 請確認該版本的 Vision 支援狀況
azure_endpoint="https://你的組織.openai.azure.com/"
)
# 重要:Azure 的 model 參數通常要填「Deployment Name」,不是 OpenAI 的模型代號
deployment_name = "你的_deployment_name"### C. Poe (透過 OpenAI 相容介面)
Poe 提供了相容 OpenAI 的 API 接入點,關鍵在於修改 `base_url`。
from openai import OpenAI
client = OpenAI(
api_key="你的_poe_api_key",
base_url="https://api.poe.com/v1" # 關鍵:指向 Poe 的伺服器
)
# Poe 的 model 名稱通常是「Bot 名稱」(依 Poe 後台/文件為準)
# 一般來說,4o/4o-mini 或 gemini/claude 系列才支援多模態(視覺)
model_name = "GPT-4o" # 使用支援視覺的模型## 3. 圖片前處理:Base64 編碼
為了透過 API 傳送圖片,最穩定的方式是將圖片轉為 **Base64 Data URI** 字串。這樣可以避免依賴外部圖片網址 (URL)。
import base64
import mimetypes
from pathlib import Path
def encode_image_to_data_uri(image_path: str | Path) -> str:
image_path = Path(image_path)
# 1. 判斷圖片格式 (MIME type)
mime_type, _ = mimetypes.guess_type(str(image_path))
if not mime_type:
mime_type = "image/jpeg" # 預設值
# 2. 讀取圖片並轉為 Base64
with image_path.open("rb") as image_file:
base64_encoded_str = base64.b64encode(image_file.read()).decode('utf-8')
# 3. 組合完整的 Data URI
# 格式依循 RFC 2397 標準:data:[<mediatype>][;base64],<data>
# 1. 冒號 (:) 之後接 MIME type (如 image/jpeg)
# 2. 分號 (;) 之後接 "base64" 關鍵字,宣告編碼方式
# 3. 逗號 (,) 之後才是真正的編碼資料
return f"data:{mime_type};base64,{base64_encoded_str}"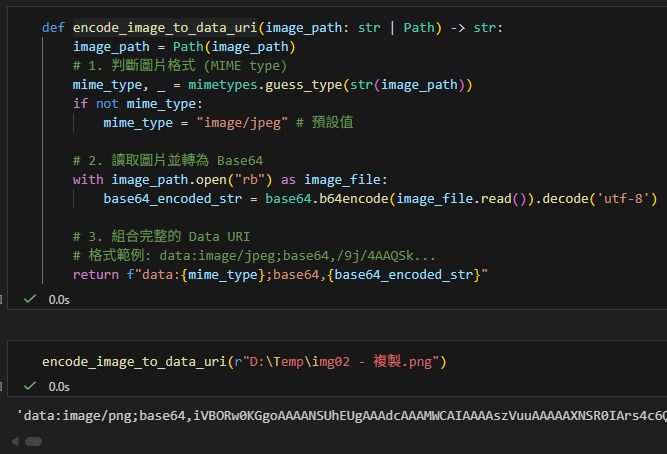
## 4. 發送請求 (The Request Payload)
這是最核心的部分。我們使用 `image_url` 類型來傳遞圖片資料。
### 關鍵參數解析
* **`messages`**: 是一個列表,包含對話歷史。
* **`content`**: 若要傳圖,`content` 必須改為**列表 (List)** 形式,其中包含:
* `type: “text”`: 你的提示詞 (Prompt)。
* `type: “image_url”`: 圖片物件。
* **`detail: “high”`**: **(重要)** 強制模型以高解析度模式分析圖片。
* `low`: 僅消耗 85 tokens,適合看大略構圖。
* `high`: 會將圖片切成 512×512 的方格進行細部分析,雖然 Token 消耗較高,但對於**OCR (文字辨識)** 至關重要。
### 完整呼叫範例
# 準備資料
image_path = "document.jpg" # 你的圖片路徑
data_uri = encode_image_to_data_uri(image_path)
prompt_text = "請辨識圖片中的所有文字,並以 Markdown 格式輸出。"
# 發送 API 請求
response = client.chat.completions.create(
# 注意:
# 1. 若使用 Azure,model 參數請填「Deployment Name」(部署名稱)
# 2. 若使用 OpenAI / Poe,model 參數請填「Model Name」(模型名稱)
# 這裡使用條件判斷來自動選擇變數,實務上請擇一填入對應字串即可
model=deployment_name if "deployment_name" in globals() else model_name,
messages=[
{
"role": "user",
"content": [
# 1. 文字提示
{
"type": "text",
"text": prompt_text
},
# 2. 圖片內容
{
"type": "image_url",
"image_url": {
"url": data_uri,
# detail 選項:
# "low" -> 固定 85 tokens (僅適合描述大略構圖, 不適合 OCR)
# "high" -> 強制切圖分析 (消耗較多 token 但 OCR 最清晰)
# "auto" -> 預設值 (依圖片大小自動決定)
"detail": "high" # 確保 OCR 清晰度的關鍵設定
}
}
]
}
],
temperature=0.2, # 降低隨機性,適合精準任務
presence_penalty=0.0
)
# 取得結果
result = response.choices[0].message.content
print(result)detail 參數主要有三個選項:
low:- 低解析度模式。模型只會收到一張 512×512 的縮圖。
- 優點:非常省錢 (固定 85 tokens)。
- 缺點:細節完全看不清,極度不適合 OCR (除非字體超級大)。
high:(強烈建議 OCR 使用此模式)- 高解析度模式。模型會先把圖片切成多個 512×512 的方格 (Tiles),再外加一張縮圖,最後全部都要計費。
- 優點:能看清小字與細節,是 OCR 的唯一選擇。
- 缺點:Token 消耗較高 (視圖片大小而定,通常數百到一千多 tokens)。
auto:(預設值)- 模型會根據圖片尺寸自動決定要用
low還是high。 - 如果圖片本身很小 (小於 512×512),它就會選
low。
- 模型會根據圖片尺寸自動決定要用
## 5. Token / 成本估算(務必以回傳 usage 為準)
`detail: “high”` 通常會讓模型用更細的方式分析圖片(例如切成多個 tiles),因此 token 可能明顯上升;但不同供應商/模型的「圖片 token 計算規則」會變動。
最保險的做法:直接讀取 API 回傳的 `usage` 欄位,才是實際計費依據。例如 OpenAI/Azure 相容介面通常可用:
print("prompt_tokens=", getattr(response.usage, "prompt_tokens", None))
print("completion_tokens=", getattr(response.usage, "completion_tokens", None))推薦hahow線上學習python: https://igrape.net/30afN
 ) ;雙層column name的DF與Series或單層column name的DF做橫向(axis=1)合併會如何? 雙層column name被壓縮成單層的tuple")
 ; df.set_index() 將df中的某column設為index")
位置? ax.legend( bbox_to_anchor = (1, 1), borderaxespad=0)")
![Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230216183536_29.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)")
 vs 深拷貝(deep copy),什麼時候需要用深拷貝? import copy ; b = copy.deepcopy(a)")
生成pandas.DataFrame?")
) ; ax.annotate(text,xy,…) #註釋 ; 通用屬性 ; linestyle ;圖例 legend ; set_title()、set_xlabel()、set_ylabel() ; 網格 ax.grid(visible=None, axis=’both’, …) ; ax.set_xticks() ; ax.set_yticks()")
 ; str.isspace() ; str.isalpha()")
垂直位置教學: rank=’sink’ ; rank=’source’ ; rank=’same’ ; 為子圖的屬性,在node中設定無效 ; 不可與g.attr(newrank=’true’) #子圖同高度 一起使用; with g.subgraph() as s: s.attr(rank=’sink’) # 設置子圖為sink ; s.node(‘Logo’, ‘Company Logo’)")

近期留言