numpy.matmul (ary1, ary2):

import numpy as np
list1 = [1,2,3]
list2 = [
[3],
[2],
[1]]
a1 = np.array(list1)
a2 = np.array(list2)
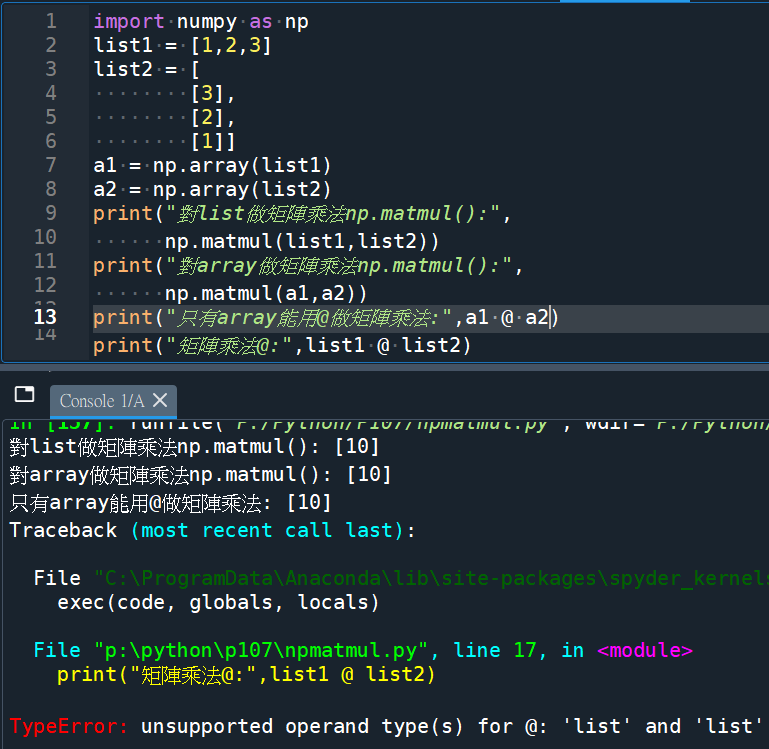
print(“對list做矩陣乘法np.matmul():”,
np.matmul(list1,list2))
print(“對array做矩陣乘法np.matmul():”,
np.matmul(a1,a2))
print(“只有array能用@做矩陣乘法:”,a1 @ a2)
print(“矩陣乘法@:”,list1 @ list2)
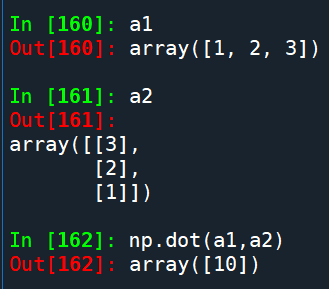
numpy.dot()
推薦hahow線上學習python: https://igrape.net/30afN



和深拷貝(Deep Copy); list切片有淺拷貝的效果 ; pandas.Series.copy(deep=True) 可對Series對向執行深拷貝")
![Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2024/02/20240208093926_0.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?")
")


:台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免")

近期留言