#Python random與tuple, set, issubset(), issuperset()
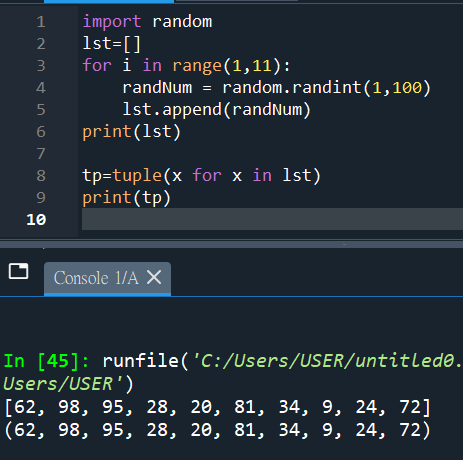
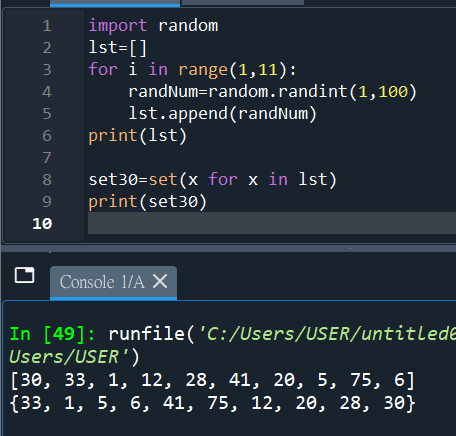
import random
lst=[]
for i in range(1,11):
randNum = random.randint(1,100)
lst.append(randNum)
print(lst)
tp=tuple(x for x in lst)
print(tp)
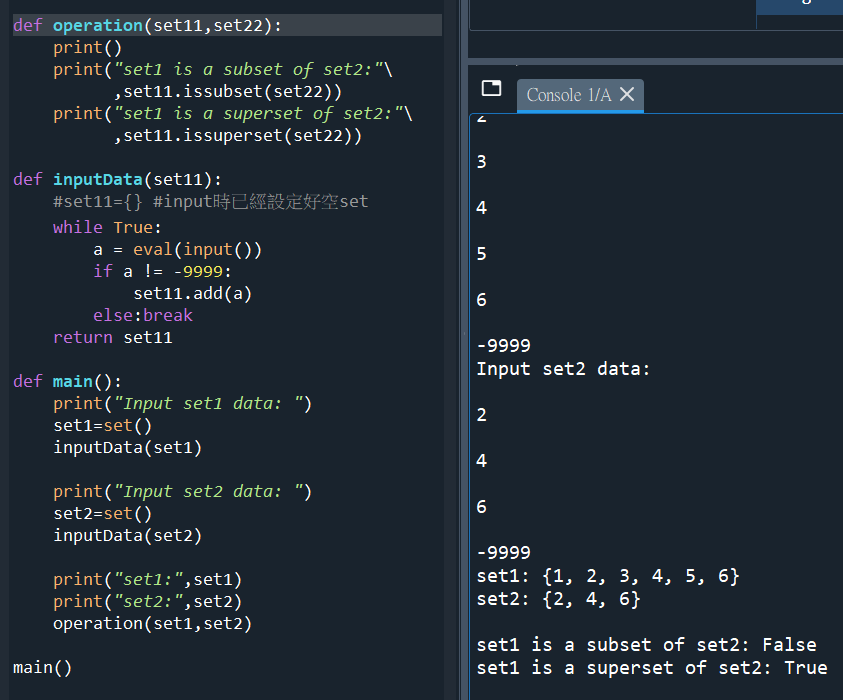
def operation(set11,set22):
print()
print(“set1 is a subset of set2:”\
,set11.issubset(set22))
print(“set1 is a superset of set2:”\
,set11.issuperset(set22))
def inputData(set11):
#set11={} #input時已經設定好空set
while True:
a = eval(input())
if a != -9999:
set11.add(a)
else:break
return set11
def main():
print(“Input set1 data: “)
set1=set()
inputData(set1)
print(“Input set2 data: “)
set2=set()
inputData(set2)
print(“set1:”,set1)
print(“set2:”,set2)
operation(set1,set2)
main()

 合併兩個DataFrame? 具關聯性欄位合併")
 ; ax.xaxis.tick_top() ; ax.set_xticks( ticks=list1, label=list2, rotation=45) #幫刻度值取別名; 如何用loc參數設定title/label位置?存檔的圖片若被裁切如何設定? bbox_inches = ‘tight’")

計算, 文件中出現最多次的是那一個字?出現幾次?")

 ? 如何搭配portable Chrome? from selenium.webdriver.common.by import By ; from selenium.webdriver.chrome.options import Options ; option = Options() ; option.binary_location = chrome_portable_path")
,類別(Class), 物件(Object), 屬性(Attribute)=變數, 方法(Method)=函式, 建構式(Constructor) def __init__(self,x,y): 計算計程車車資, assert 斷言, 全域變數與區域變數")



近期留言