這篇教程將帶您深入 Word 文檔的 OpenXML 底層,
探討如何在使用 python-docx 進行高難度操作(如文檔分割、重組)時,
確保文檔的「紙張設定(Section Properties)」永遠不會崩壞。
核心問題
當我們將一個 Word 文檔切成碎片或清空內容時,
往往不小心就把最重要的「頁面設定」(w:sectPr)給刪了。這會導致:
- 跑版:A3 橫向變回 A4 直向。
- 損毀:Word 開啟時報錯。
解決方案:三層防護網
我們將實作一個強健的邏輯:
- 第一層(最優):沿用原始文檔的設定。
- 第二層(次優):使用
python-docx內建的標準設定。 - 第三層(底限):強制生成一個合法的空標籤
w:sectPr,
觸發 Word 使用讀者電腦的預設值。
0. 環境設定與工具函式
首先,我們需要引入 python-docx 並設定一些 XML 操作需要的工具。
import os
from docx import Document
from docx.oxml import OxmlElement
from docx.oxml.ns import qn
from docx.shared import Inches
from copy import deepcopy
# 定義 XML 命名空間常數
W_SECTPR = qn('w:sectPr')
# '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}sectPr'
def get_xml_structure(doc, limit=500):
"""輔助函數:查看 document body 的最後幾個 XML tag"""
xml = doc.element.body.xml
# docx.oxml.xmlchemy.XmlString 類似 str
# 簡單截取尾部方便觀察
return "..." + xml[-limit:] if len(xml) > limit else xml1. 建立示範檔案:這是一個「有特殊版面」的文件
為了測試,我們先生成一個具有
寬 10 英吋 x 高 5 英吋(很扁的紙張)的文件,
當作我們的「原始文件 (Global Source)」。
# 1. 產生一個有「特殊版面設定」的原始檔
source_path = "demo_source_layout.docx"
doc = Document()
doc.add_paragraph("這是原始文件,設定為特殊尺寸。")
# 修改最後一個 section 的版面設定
section = doc.sections[-1]
section.page_width = Inches(10) # 寬度 10 吋
section.page_height = Inches(5) # 高度 5 吋 (很扁)
doc.save(source_path)
print(f"已生成示範檔: {source_path}")
# 檢查它的 XML 尾巴,應該可以看到 <w:sectPr> 裡面有 <w:pgSz w:w="..." w:h="..."/>
doc_check = Document(source_path)
print("\n[原始檔 XML 尾部檢視]:")
print(get_xml_structure(doc_check, 300))
# 【關鍵步驟】把這個珍貴的原始設定存到全域變數,模擬程式運行時的狀態
global_CT_SectPr = doc_check.element.body.findall(W_SECTPR)[-1]
print(f"\n[已捕獲 Global SectPr]: {global_CT_SectPr}")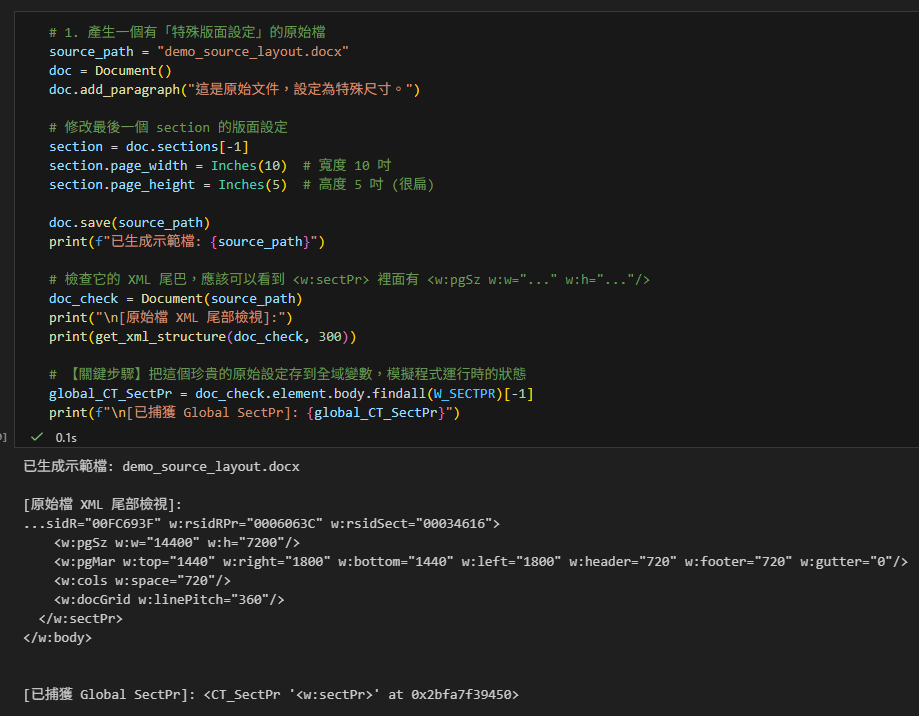
demo_source_layout.docx
2. 模擬危機:為什麼要「先刪再補」?
當我們建立一個新的空白 Document() 時,
它天生自帶一個預設的 sectPr(通常是 A4 或 Letter)位於 body 的結尾。
如果我們直接將切出來的內容(Paragraphs)附加(append)到文件內容之後:
- 操作前:
[預設_sectPr] - Append 後:
[預設_sectPr, 內容_P1, 內容_P2...]❌ 大錯特錯!
依據 OpenXML 規範,定義整份文件版面的 sectPr
必須永遠位於 body 的最後一個子節點。
一旦它被擠到前面,它就失效了。
因此,我們必須執行標準流程:
- 先移除:把那個擋路的預設
sectPr拔掉(並備份起來)。 - 再填充:把內容 P1, P2… 一一放進去。
- 後蓋章:最後再把正確的
sectPr貼在最尾端。
下面的程式展示這個「三層防護」函數如何運作。
def save_with_protection(filename, use_global=True, use_backup=True):
"""
這是一個模擬「存檔前最後檢查」的函數
參數:
use_global: 是否允許使用原始文件的設定 (Layer 1)
use_backup: 是否允許使用 python-docx 預設的設定 (Layer 2)
"""
# 1. 建立一個全新的小文件 (這是容器)
new_doc = Document()
new_doc.add_paragraph(f"這是測試檔案: {filename}")
new_doc.add_paragraph("請檢查我的版面大小。")
body = new_doc.element.body
# --- [模擬操作] ---
# 在這裡,我們模擬為了清理文件,不小心殺紅了眼,把原本 body 裡的 sectPr 也找出來了
# [Layer 2 預備動作]:在殺掉它之前,先看看有沒有備份可以留
backup_sectPr = None
for el in list(body):
if el.tag == W_SECTPR:
backup_sectPr = el # 抓到了!這是 library 給我們的預設值
body.remove(el) # 把它從 body 移除
print(f"\n--- 處理 {filename} ---")
print(f"清理後 body 是否還有 sectPr? {'w:sectPr' in body.xml}")
# --- [三層防護邏輯開始] ---
final_sectPr = None
# 層級 1: Global Source (最優先)
# 我們看看全域變數有沒有壞掉,或者使用者是否允許使用
if use_global and global_CT_SectPr is not None:
print("✅ 使用 Layer 1: 原始文件設定 (Global)")
final_sectPr = global_CT_SectPr
# 層級 2: Library Backup (次優先)
# 如果全域的沒了,那剛剛殺掉的那個預設值,還能用嗎?
elif use_backup and backup_sectPr is not None:
print("⚠️ 使用 Layer 2: 程式庫預設備份 (Backup)")
final_sectPr = backup_sectPr
# 層級 3: The Safety Net (最終手段)
# 如果連備份都沒有 (例如 body 是早就被清空的),我們必須無中生有
else:
print("🛡️ 使用 Layer 3: 最終空標籤 (Safety Net)")
# 這就是我們的主角:憑空創造一個合法的印章
final_sectPr = OxmlElement('w:sectPr')
# [Action] 蓋章!
if final_sectPr is not None:
body.append(deepcopy(final_sectPr))
new_doc.save(filename)
return filename3. 實戰演練:三種情境的結果
現在我們來產生三個檔案,分別對應三種防護層級被觸發的時候。
請在執行後打開這三個 Word 檔,觀察它們的「版面配置 -> 大小」。
- Result_L1_Global.docx: 應該是 10×5 英吋 (繼承原始檔)。
- Result_L2_Backup.docx: 應該是 Letter/A4 (繼承 python-docx 預設)。
- Result_L3_Safety.docx: 應該是 預設值 (完全空白標籤,由 Word 決定)。
# 情境 1: 快樂路徑 - 原始資料都在
save_with_protection("Result_L1_Global.docx", use_global=True, use_backup=True)
# 情境 2: 原始資料遺失 - 退回第二線
# (模擬 global 變數變成 None 或找不到)
save_with_protection("Result_L2_Backup.docx", use_global=False, use_backup=True)
# 情境 3: 絕境 - 連備份都沒了 (極端狀況 / 軟體工程防禦)
# 您可能會想:「Document() 產生時不是一定會有 sectPr 嗎?」
# 沒錯,但在軟體工程中,我們不能假設依賴的函式庫 (python-docx) 永遠不變,
# 或者這段程式碼被移動到「body 已經被外部程式清空」的流程中執行。
# 這層「不可由之」的防護,是為了確保程式在 0.01% 的異常狀態下也不會 Crash。
save_with_protection("Result_L3_Safety.docx", use_global=False, use_backup=False)4. 最終驗證:三種檔案的基因檢測
我們將一一剖析這三個生成的檔案,觀察它們 body 結構的最尾端。這裡的差異將證實我們的「三層防護網」是否如預期般運作:
- 情境 1 (Global):預期看到 明確的頁面尺寸 (w:w, w:h),數值對應我們設定的 10×5 英吋。
- 情境 2 (Backup):預期看到 明確的頁面尺寸,但數值是 Library 預設的 (通常是 A4/Letter)。
- 情境 3 (Safety):預期看到 空的
<w:sectPr/>標籤。這雖然沒有尺寸資訊,但它的存在至關重要——它是合法的 OpenXML 結構,讓 Word 能順利打開並套用預設值,而不是報錯損毀。
def inspect_sectpr(filename, label):
"""輔助函數:讀取並印出 docx 的最後一段 xml 與 sectPr 狀態"""
if not os.path.exists(filename):
print(f"[{label}] 檔案未生成: {filename}")
return
doc_inspect = Document(filename)
xml_content = doc_inspect.element.body.xml
sectpr_tags = doc_inspect.element.body.findall(W_SECTPR)
print(f"\n=== 檢查 {label} ({filename}) ===")
# 檢查 sectPr 標籤是否存在
if sectpr_tags:
last_sectpr = sectpr_tags[-1]
print(f"✅ 成功找到 sectPr 標籤: {last_sectpr.tag}")
# 進一步檢查是否有頁面大小設定 (w:pgSz)
pgSz = last_sectpr.find(qn('w:pgSz'))
if pgSz is not None:
w = pgSz.get(qn('w:w'))
h = pgSz.get(qn('w:h'))
print(f" 📏 版面尺寸: 寬={w} (Twips), 高={h} (Twips)")
# 註: Twips 是 'Twentieth of an Inch Point',
# 1 twip = 1/20 pt = 1/1440 英吋"
# 註: 14400 Twips = 10 inches, 7200 Twips = 5 inches
else:
print(" ⚠️ 標籤內無尺寸設定 (這就是 Layer 3 的特徵: 空殼標籤 -> 交給 Word 預設值)")
else:
print("❌ 錯誤:找不到 sectPr 標籤!檔案可能損毀。")
# 印出 XML 尾部供確認
# print(f" [XML Tail]: ...{xml_content[-150:]}")
# 一次檢查這三個檔案,見證三層防護的差異
inspect_sectpr("Result_L1_Global.docx", "情境 1 (Global)")
inspect_sectpr("Result_L2_Backup.docx", "情境 2 (Backup)")
inspect_sectpr("Result_L3_Safety.docx", "情境 3 (Safety Net)")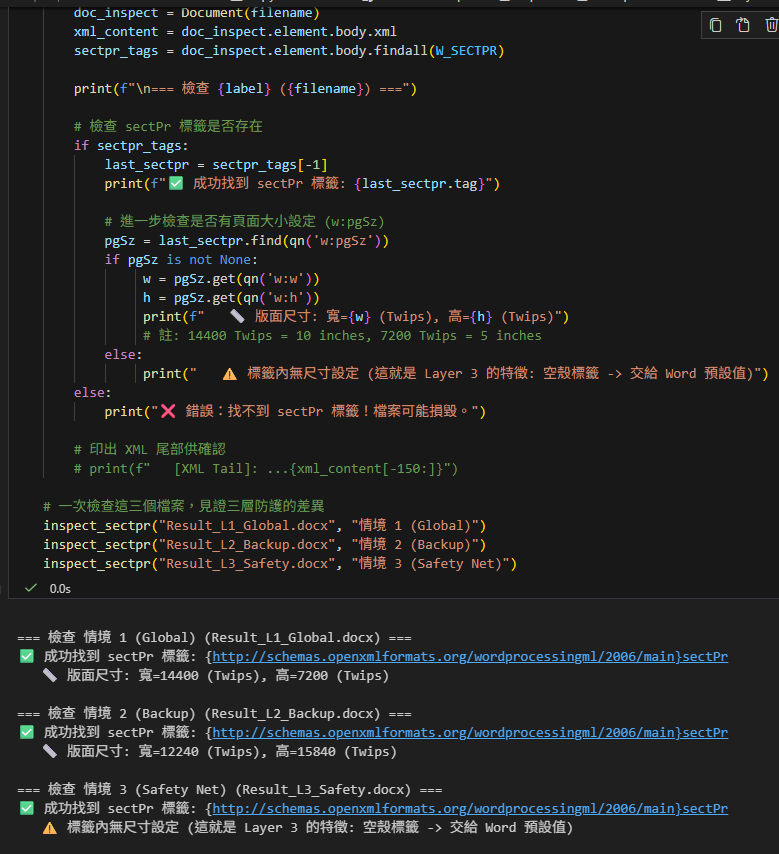
5. 觀察與總結:為什麼 L2 和 L3 看起來一樣?
您執行後可能會發現,
情境 2 (Backup) 和 情境 3 (Safety Net) 打開來看,
版面大小似乎一模一樣(例如都是 Letter 或 A4)。
這是一個有趣的觀察,但它們在本質上有巨大的差異:
- L2 (備份) 是 「明確的預設值 (Explicit Default)」:
- XML 裡面寫死了
<w:pgSz w:w="12240" .../>(Letter 尺寸)。 - 無論是誰打開這份檔案,它永遠都是 8.5×11 英吋。
- XML 裡面寫死了
- L3 (空殼) 是 「環境的預設值 (Implicit Default)」:
- XML 裡面是空的
<w:sectPr/>。 - 它的長相取決於打開它的人。
- 如果在台灣/歐洲電腦打開,Word 可能會把它顯示為 A4。
- 如果在美國電腦打開,Word 可能會把它顯示為 Letter。
- XML 裡面是空的
結論:
這三層防護網不僅是程式碼的備案,更是對「文件格式控制權」的逐步讓渡:
- Layer 1:我們完全控制 (100% 還原)。
- Layer 2:我們接受函式庫的標準控制 (固定為 Letter/A4)。
- Layer 3:我們放棄控制,只求檔案合法 (交給使用者的 Word 決定)。
推薦hahow線上學習python: https://igrape.net/30afN
 vs csv.reader(io.TextIOWrapper) 有何差別? 為何出現ParserError? #Parser:解析器,如何讀取Excel檔(xlsx)?pandas.read_excel()")
 ; Visual Studio Code(VScode)為什麼會出現錯誤 module ‘csv’ has no attribute ‘reader’ ?")
 計算每月應投資金額?送GUI介面程式")
 ; qn(‘w:tbl’) ; qn(‘w:sectPr’)")
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2025/03/20250330190318_0_925655.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)")

![Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/05/20260527141829_0_5a8a75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?")
 as z: print(z.namelist()) ; z.infolist()")
 完全指南; status = “成年” if age >= 18 else “未成年” ; 值_如果為真 if 條件判斷 else 值_如果為假 #取這個值 (如果條件成立),否則 (取那個值)")

近期留言