# -*- coding: utf-8 -*-
"""
Created on Sun Jan 21 23:00:08 2024
@author: SavingKing
"""
import requests
from bs4 import BeautifulSoup as bs
url = "https://www.104.com.tw/company/search?jobsource=index_cs"
response = requests.get(url)
#<Response [200]>
soup = bs(response.text)
"""
type(soup )
Out[77]: bs4.BeautifulSoup
type(response.text)
Out[78]: str
"""code:
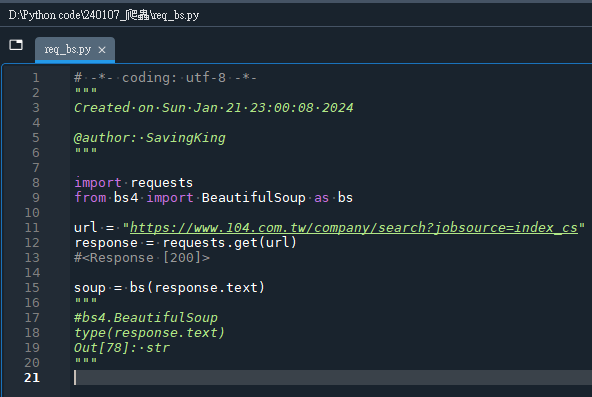
soup:
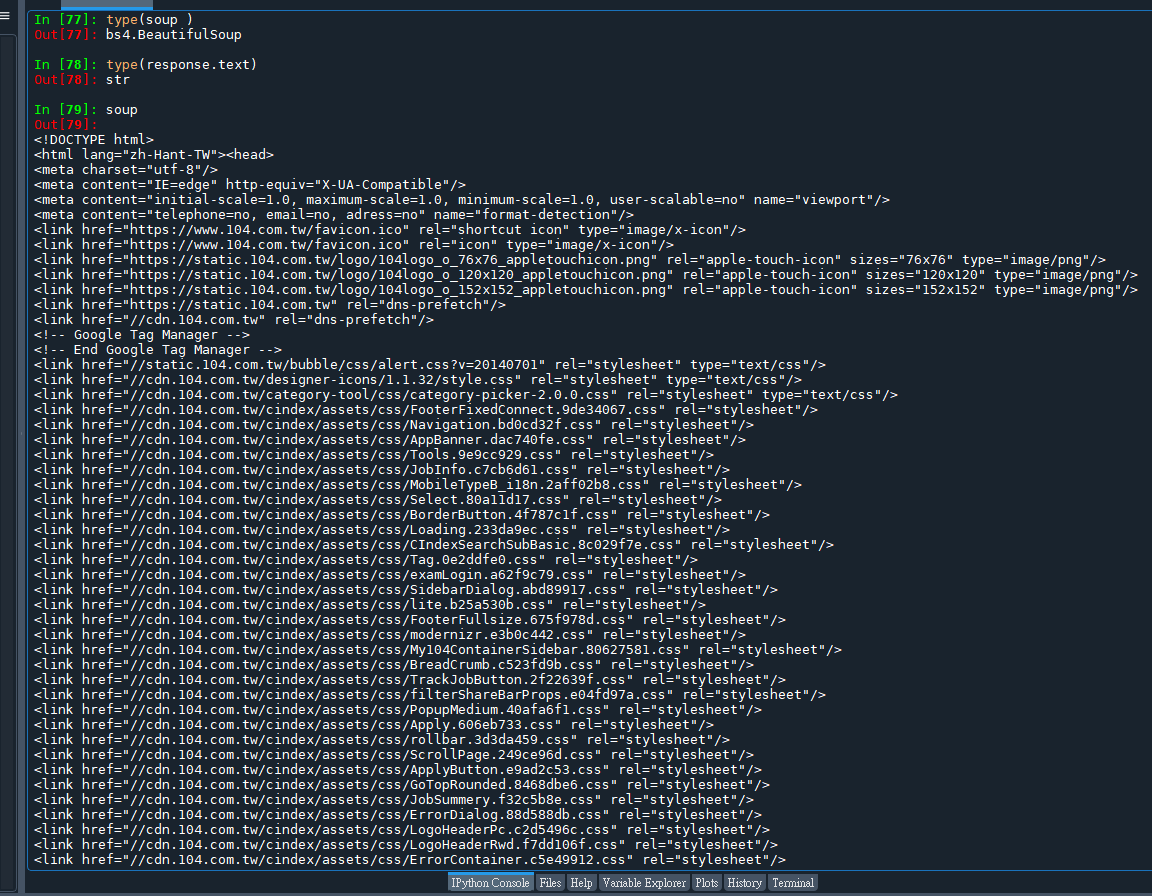
soup(由 BeautifulSoup 解析後的對象)和 response.text(從 requests 庫獲取的原始HTML文本)在本質上確實都與HTML格式相關,但它們之間存在幾個關鍵的區別:
response.text
這是通過HTTP請求(使用 requests 庫)從網頁URL獲取的原始HTML內容的字符串表示。
它是一個純文本字符串,包含了網頁的完整HTML代碼。
作為一個字符串,它不提供直接的方法來解析或操作HTML元素。
soup(BeautifulSoup 對象)
通過將 response.text 傳遞給 BeautifulSoup 構造函數,soup 變成了一個 BeautifulSoup 對象。
BeautifulSoup 對象表示的是一個解析後的文檔,它提供了許多方法和屬性來搜索和操作HTML文檔的結構。這意味著您可以方便地根據標簽名、屬性等來找到感興趣的HTML元素。
與 response.text 的純文本不同,soup 使得HTML內容變得像一個可遍歷和可操作的對象。您可以使用它的方法,如 find(), find_all(), select() 等,來提取或修改文檔的特定部分。
簡而言之,response.text 是從網頁獲取的未加工的HTML字符串,而 soup 是這個HTML字符串被 BeautifulSoup 解析後的對象,提供了豐富的API來使得HTML文檔的遍歷和操作更為簡單和直觀。這種轉換使得從HTML文檔中提取數據變得更加容易和高效。
推薦hahow線上學習python: https://igrape.net/30afN
Chrome瀏覽器
ctrl + shift +I
可以檢視網頁原始碼
做元素比對
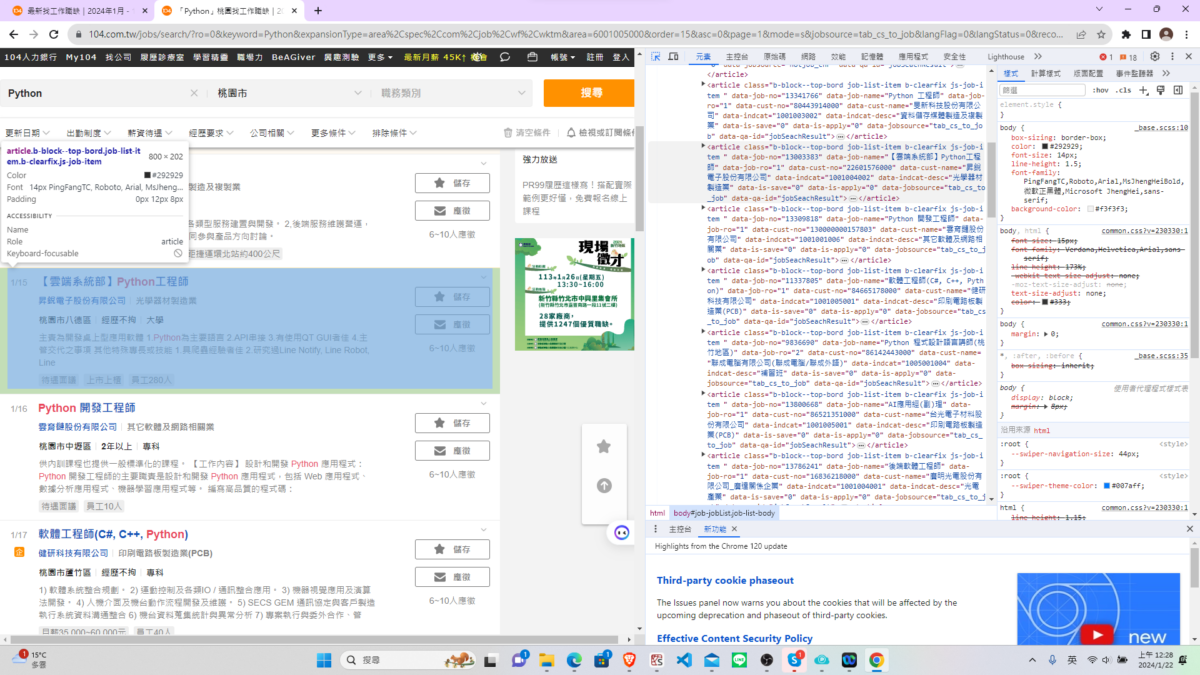
放大HTML:
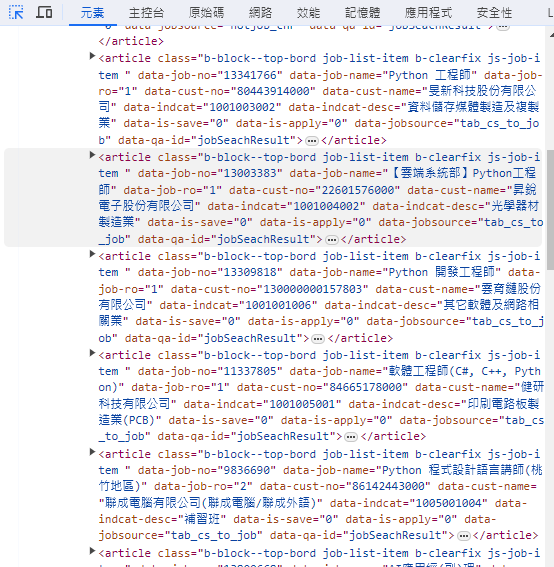
注意一頁中的每一個職缺資料,
標籤開頭都是article class="b-block--top-bord job-list-item b-clearfix js-job-item"
find_all() 中的參數
就是依據這個標籤result_set = soup.find_all("article", class_="b-block--top-bord job-list-item b-clearfix js-job-item")
#class 是python的關鍵字
因此用class_與關鍵字區別
find_all() 中
class_是外露的參數名稱
所以需要多加一個底線,
避免跟python關鍵字衝突
select()中,
class被包在字串的單引號中
(雙引號被屬性值用掉)
所以不需要避免跟python關鍵字衝突
find_all() 中,
除了手動幫class多加一個底線
都是從HTML中複製貼上
會比select更直觀
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 21 23:00:08 2024
@author: SavingKing
"""
import requests
from bs4 import BeautifulSoup as bs
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
url = "https://www.104.com.tw/jobs/search/?ro=0&keyword=Python&expansionType=area%2Cspec%2Ccom%2Cjob%2Cwf%2Cwktm&area=6001005000&order=15&asc=0&page=1&mode=s&jobsource=tab_cs_to_job&langFlag=0&langStatus=0&recommendJob=1&hotJob=1"
response = requests.get(url,headers=headers)
"""
#<Response [200]>
response.status_code
Out[30]: 200
"""
soup = bs(response.text,features="lxml")
"""
type(soup )
Out[77]: bs4.BeautifulSoup
type(response.text)
Out[78]: str
"""
result_set = soup.find_all("article",
class_="b-block--top-bord job-list-item b-clearfix js-job-item")
#bs4.element.ResultSet
print(result_set[0].prettify())
"""
type(result_set[0])
Out[118]: bs4.element.Tag
"""
tag0 = result_set[0]result_set = soup.find_all(“article”,class_=”b-block–top-bord job-list-item b-clearfix js-job-item”)
#bs4.element.ResultSet
result_set是像list的BeautifulSoup實例
tag0 = result_set[0]
tag0的type為bs4.element.Tag
print(tag0.prettify()) #兩個t,不要拼錯
部分內容如下:
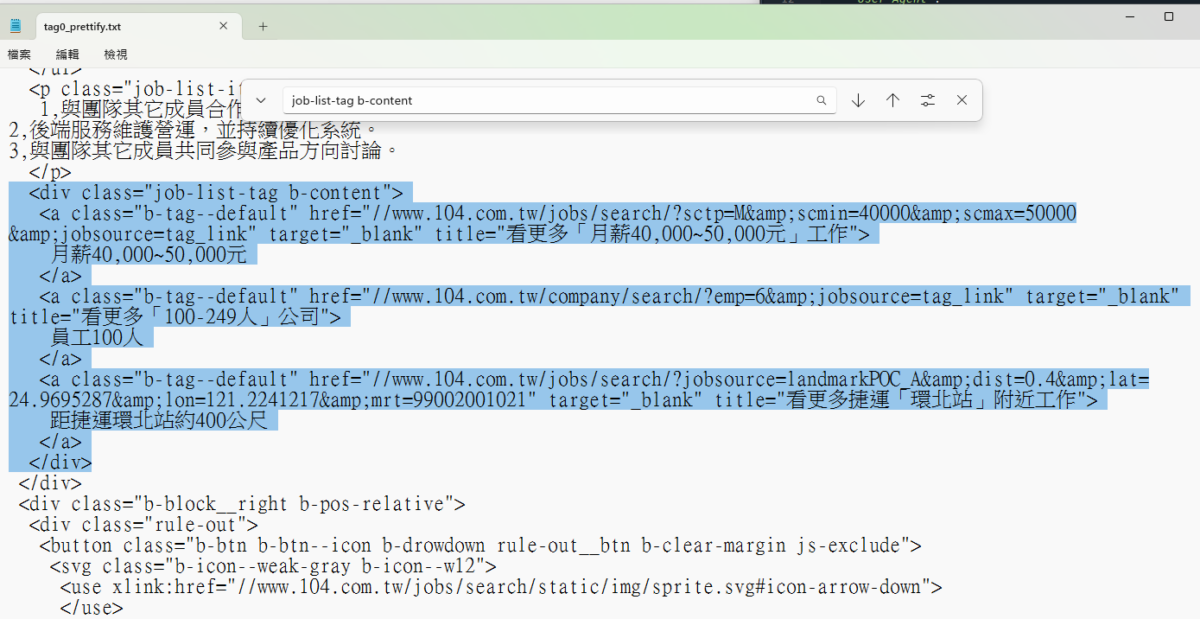
分別使用find_all() 與 select
取出標記起來的bs4.element.Tag:
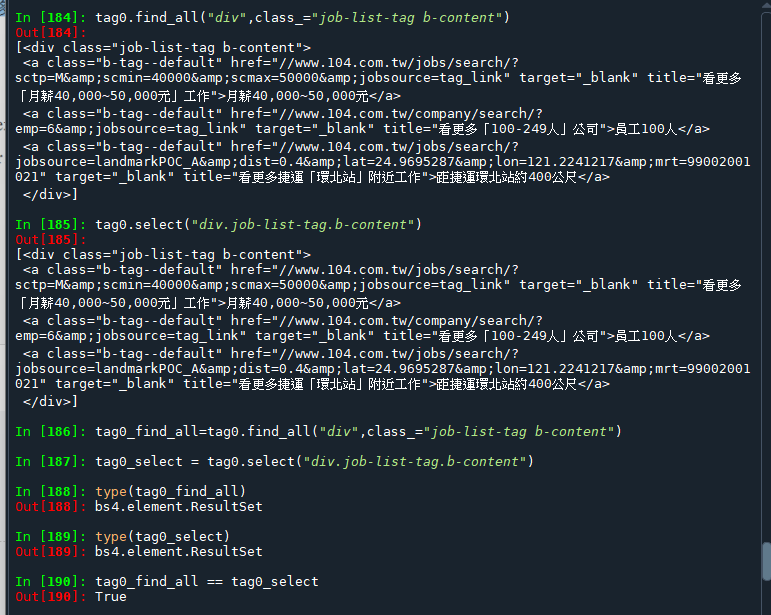
.find_all() 與 .select()
soup.find_all("div",class_="job-list-tag b-content")
soup.select("div.job-list-tag.b-content").find_all() 與 .select()
使用不一樣的下參數方法
返回一樣的ResultSet:
在使用BeautifulSoup的.select()方法時,它允許使用CSS選擇器來定位元素。當使用.來連接時,它特指元素的class屬性。這是因為在CSS中,.被用來選擇具有特定類名的元素。因此,當你使用.select(“div.job-list-tag.b-content”)時,它會查找所有div元素,這些元素同時擁有job-list-tag和b-content這兩個類名。
如果你想通過BeautifulSoup的.select()方法基於其他屬性來選擇元素,你需要使用不同的語法。例如,如果你想選擇具有特定id屬性的元素,你可以使用#符號,因為在CSS中,#符號用於選擇具有特定id的元素。
對於其他屬性,你可以使用方括號[]來指定。例如,如果你想選擇具有attribute屬性且屬性值為value的元素,可以這樣寫:
soup.select('[attribute="value"]')
#標籤名稱都要的話:
soup.select('div[class="job-list-tag b-content"]')因為屬性名稱剛好是class,
使用select,參數可以使用.連接
等效於:
soup.select('div.job-list-tag.b-content')總結一下:
使用.連接的是類名(class屬性)。
使用#連接的是ID(id屬性)。
使用[]可以指定其他屬性及其值
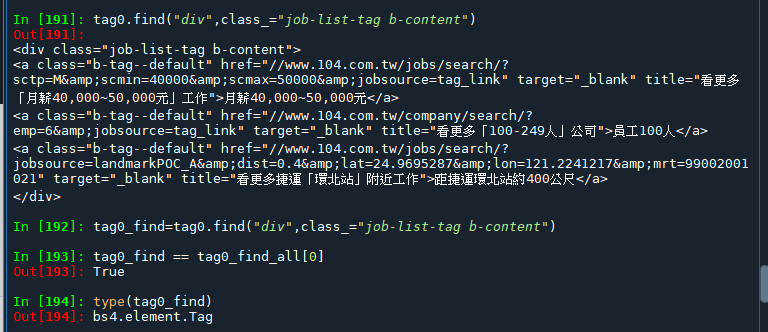
.find() 與.find_all() or .select()
內容幾乎一樣,
只差最外層少了一個中括號[]
因為.find()返回的是
第一個 bs4.element.Tag
.find_all() or.select()返回的是
bs4.element.ResultSet (像list)
取其中index 0的bs4.element.Tag
tag0.find_all(“div”,class_=”job-list-tag b-content”)[0] ==
tag0.find(“div”,class_=”job-list-tag b-content”)
會返回True
推薦hahow線上學習python: https://igrape.net/30afN
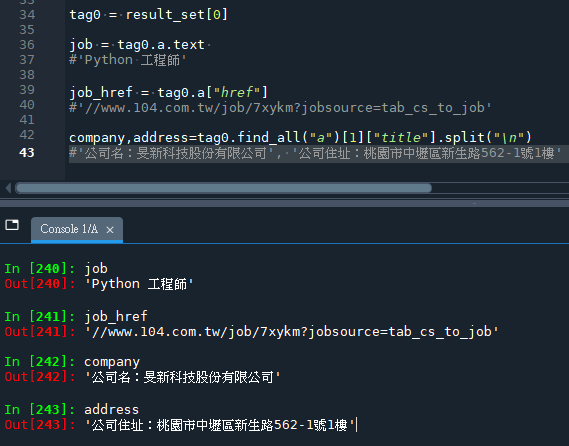
從tag0中撈出
職稱,網址,公司名,公司地址
再看一次tag0的html:
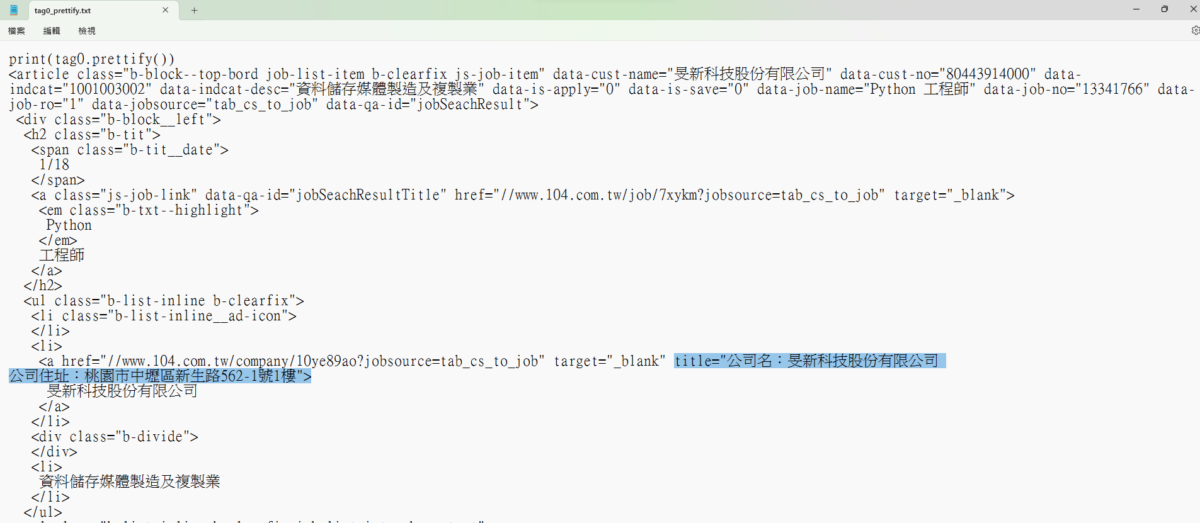
code:
tag0 = result_set[0]
job = tag0.a.text
#'Python 工程師'
job_href = tag0.a["href"]
#'//www.104.com.tw/job/7xykm?jobsource=tab_cs_to_job'
company,address=tag0.find_all("a")[1]["title"].split("\n")
#'公司名:旻新科技股份有限公司', '公司住址:桃園市中壢區新生路562-1號1樓'輸出結果:
目前已經可以抓下一整頁資料
輸出為excel
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 21 23:00:08 2024
@author: SavingKing
"""
import requests
from bs4 import BeautifulSoup as bs
import time
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
page=1
url = f"https://www.104.com.tw/jobs/search/?ro=0&keyword=Python&expansionType=area%2Cspec%2Ccom%2Cjob%2Cwf%2Cwktm&area=6001005000&order=15&asc=0&page={page}&mode=s&jobsource=tab_cs_to_job&langFlag=0&langStatus=0&recommendJob=1&hotJob=1"
response = requests.get(url,headers=headers)
"""
#<Response [200]>
response.status_code
Out[30]: 200
"""
soup = bs(response.text,features="lxml")
"""
type(soup )
Out[77]: bs4.BeautifulSoup
type(response.text)
Out[78]: str
"""
result_set = soup.find_all("article",class_="b-block--top-bord job-list-item b-clearfix js-job-item")
#bs4.element.ResultSet
print(result_set[0].prettify())
"""
type(result_set[0])
Out[118]: bs4.element.Tag
"""
tag0 = result_set[0]
tag1 = result_set[1]
def tag2tup_info(tag0):
job = tag0.a.text
#'Python 工程師'
job_href = tag0.a["href"]
#'//www.104.com.tw/job/7xykm?jobsource=tab_cs_to_job'
company,address=tag0.find_all("a")[1]["title"].split("\n")
#'公司名:旻新科技股份有限公司', '公司住址:桃園市中壢區新生路562-1號1樓'
tup=(job,job_href,company,address)
return tup
tup = tag2tup_info(tag0)
print(tup)
def get_salary(tag1):
if "待遇面議" in str(tag1):
salary = "待遇面議"
else:
salary = tag1.find_all("a")[2].text
return salary
import pandas as pd
def get_1page_info(result_set):
lis_info = []
for tag in result_set:
tup = tag2tup_info(tag)
salary = get_salary(tag)
tup2 = tup + (salary,)
lis_info.append(tup2)
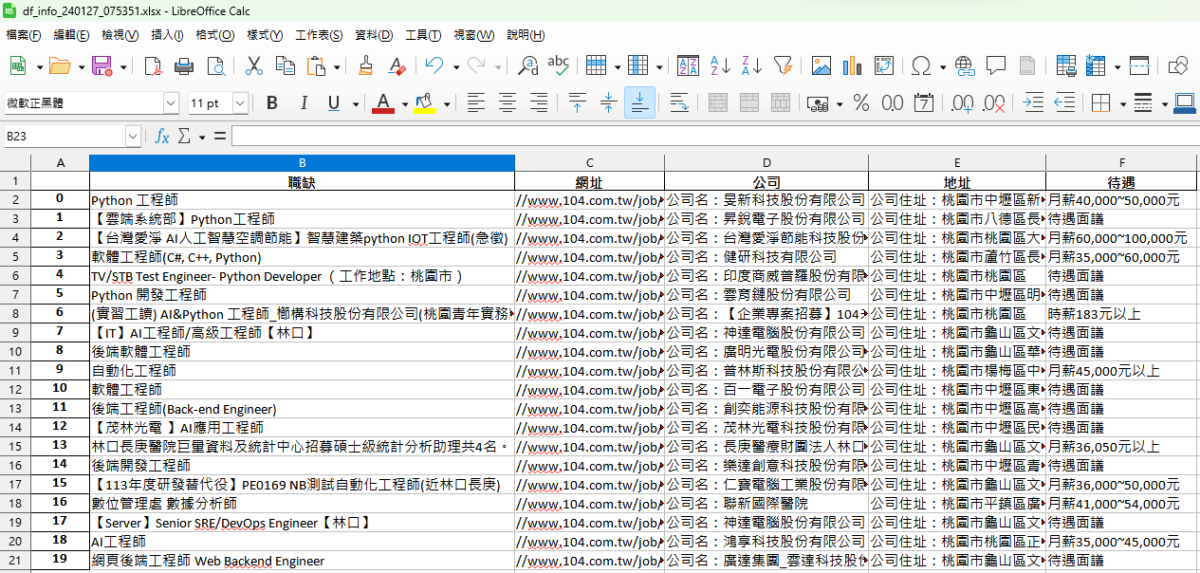
df_info = pd.DataFrame(lis_info,columns=["職缺","網址", "公司","地址","待遇"])
return lis_info,df_info
pd.set_option('display.max_columns', None)
lis_info,df_info = get_1page_info(result_set)
#已經成功抓完一頁的資料了
timestamp = time.time()
localtime = time.localtime(timestamp)
strftime = time.strftime("%y%m%d_%H%M%S",localtime)
#'240126_234705'
df_info_xlsx = "df_info_"+strftime+".xlsx"
df_info.to_excel(df_info_xlsx)
for tup in lis_info:
print(tup)輸出的df_info_240127_075351.xlsx:
推薦hahow線上學習python: https://igrape.net/30afN
url中含有page= 的資訊,
所以可以變化網址,
造成翻頁的效果:
url = f"https://www.104.com.tw/jobs/search/?ro=0&keyword=Python&expansionType=area%2Cspec%2Ccom%2Cjob%2Cwf%2Cwktm&area=6001005000&order=15&asc=0&page={page}&mode=s&jobsource=tab_cs_to_job&langFlag=0&langStatus=0&recommendJob=1&hotJob=1"將程式放進去while迴圈中,
page+=1
直到網站沒有資料為止
function則移出迴圈之外,
以免每次迴圈都重新定義function
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 21 23:00:08 2024
@author: SavingKing
"""
import requests
from bs4 import BeautifulSoup as bs
import time
import pandas as pd
# tag0 = result_set[0]
# tag1 = result_set[1]
def tag2tup_info(tag0):
job = tag0.a.text
#'Python 工程師'
job_href = tag0.a["href"]
#'//www.104.com.tw/job/7xykm?jobsource=tab_cs_to_job'
company,address=tag0.find_all("a")[1]["title"].split("\n")
#'公司名:旻新科技股份有限公司', '公司住址:桃園市中壢區新生路562-1號1樓'
tup=(job,job_href,company,address)
return tup
# tup = tag2tup_info(tag0)
# print(tup)
def get_salary(tag1):
if "待遇面議" in str(tag1):
salary = "待遇面議"
else:
salary = tag1.find_all("a")[2].text
return salary
def get_1page_info(result_set):
lis_info = []
for tag in result_set:
tup = tag2tup_info(tag)
salary = get_salary(tag)
tup2 = tup + (salary,)
lis_info.append(tup2)
df_info = pd.DataFrame(lis_info,columns=["職缺","網址", "公司","地址","待遇"])
return lis_info,df_info
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
lis_df = []
page=1
while True:
url = f"https://www.104.com.tw/jobs/search/?ro=0&keyword=Python&expansionType=area%2Cspec%2Ccom%2Cjob%2Cwf%2Cwktm&area=6001005000&order=15&asc=0&page={page}&mode=s&jobsource=tab_cs_to_job&langFlag=0&langStatus=0&recommendJob=1&hotJob=1"
print(f"目前正要抓取Page{page}資料")
response = requests.get(url,headers=headers)
"""
#<Response [200]>
response.status_code
Out[30]: 200
"""
print("response.status_code:\t",response.status_code)
soup = bs(response.text,features="lxml")
"""
type(soup )
Out[77]: bs4.BeautifulSoup
type(response.text)
Out[78]: str
"""
result_set = soup.find_all("article",class_="b-block--top-bord job-list-item b-clearfix js-job-item")
#bs4.element.ResultSet
# print(result_set[0].prettify())
"""
type(result_set[0])
Out[118]: bs4.element.Tag
"""
if result_set == []:
break
lis_info,df_info = get_1page_info(result_set)
#已經成功抓完一頁的資料了
lis_df.append(df_info)
page+=1
pd.set_option('display.max_columns', None)
timestamp = time.time()
localtime = time.localtime(timestamp)
strftime = time.strftime("%y%m%d_%H%M%S",localtime)
# #'240126_234705'
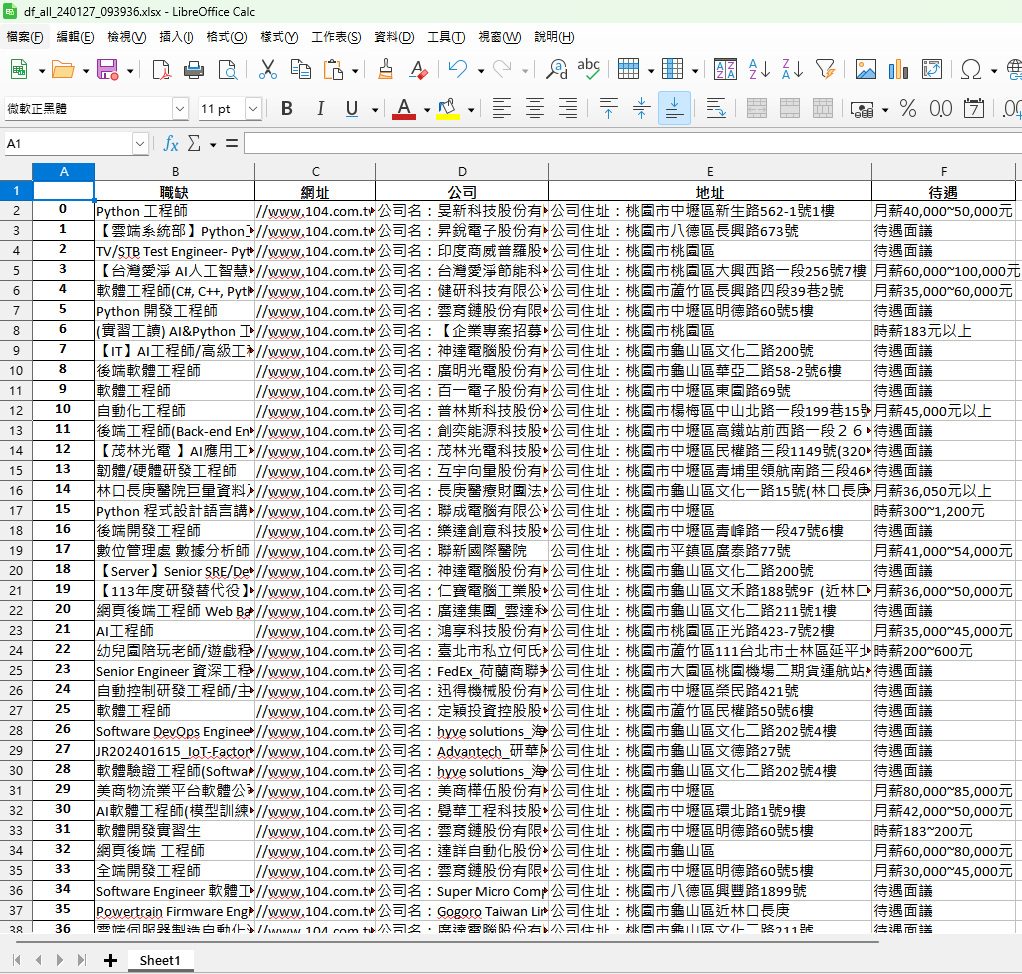
df_all = pd.concat(lis_df, axis="index").reset_index(drop=True)
xlsx = "df_all_"+strftime+".xlsx"
df_all.to_excel(xlsx)
print("資料已經輸出到:\n",xlsx)
# for tup in lis_info:
# print(tup)輸出的xlsx:
推薦hahow線上學習python: https://igrape.net/30afN
![Python: 如何使用 os.environ[“PATH”] 設定環境變數?與 sys.path.append() 差別為何?](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2024/09/20240905135312_0_890fa1.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用 os.environ[“PATH”] 設定環境變數?與 sys.path.append() 差別為何?")
![Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313160116_63.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列?")
、flatten()、reshape(-1)將多維array轉換成一維")
.f_code.co_name #動態取得function_name")
 ; axis參數如何用? numpy.max() ; numpy.min() ; numpy.argmax() #沿軸max的index; numpy.argmin() #沿軸min的index")


 函数方法的使用; df1.astype( dtype = np.float64, errors = “ignore”)")
")
![Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = "[d]{4}/[01][d]/[0123][d] [d]{6}" ; match = re .search (pattn,text) .group() - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/09/20220901154435_19-520x245.png)

近期留言