將一個list轉為set,可以去除重複值
但因為set是無序的
將set 再轉為list
原本的順序可能被打亂
要如何去除重複值並維持順序?
在 Python 中,字典 (dict) 的有序性是從 Python 3.7 版本開始的。在這個版本之前,字典中元素的順序是不確定的,這意味著字典的鍵值對的存儲和遍歷順序不能保證與添加順序相同。
自 Python 3.7 起,字典被改進為按照插入順序來維護鍵值對。這一改變最初在 Python 3.6 中作為實現細節被引入,但直到 3.7 版本才正式成為語言規範的一部分,確保所有 Python 的實現都必須按照這種方式操作字典。
這項改變意味著當你在 Python 3.7 及以後的版本中添加項到字典時,可以預期該項的插入位置就是它的存儲和遍歷位置。這使得某些操作變得更加直觀和便捷,例如保持配置項的順序或者在需要有序數據時無需額外使用如 OrderedDict 這類的數據結構。
dict.fromkeys() 是一個 Python 的內建方法,用於創建一個新字典,其中包含來自給定可叠代對象的鍵,所有鍵對應的值則設置為一個指定的統一值。這個方法非常有用當你需要初始化一個字典,使得多個鍵共享相同的初始值。
dict.fromkeys(iterable, value=None)
iterable: 一個可迭代對象,其元素將被用作新字典的鍵。
value (可選): 所有鍵的初始值,默認為 None。
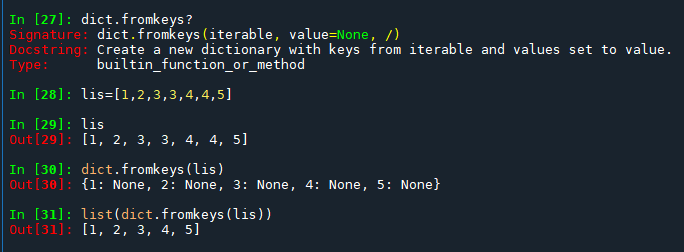
code:
# 原始列表,包含重覆元素
lis = [1, 2, 3, 3, 4, 4, 5]
# 使用 dict.fromkeys() 去除重覆元素並保持原始順序
unique_dict = dict.fromkeys(lis)
# 將字典的鍵轉換為列表
unique_list = list(unique_dict)
# 輸出結果
print(unique_list)說明:
dict.fromkeys(lis) 創建了一個字典,其中 lis 中的每個元素都作為鍵被添加到字典中。由於字典的鍵必須是唯一的,所以重覆的元素在這個過程中被自動丟棄。
由於 Python 3.7 及更高版本的字典保持鍵的插入順序,所以轉換後的字典會按照 lis 中元素首次出現的順序來排列鍵。
list(dict.fromkeys(lis)) 簡單地將字典的鍵轉換回列表形式,這樣就得到了一個沒有重覆元素、且保持原始插入順序的列表。
這種方法是去除列表重覆元素並保持順序的一種非常高效的方式,特別是在處理大型數據集時,相比傳統的遍歷或其他方法,它更為簡潔且性能更好。
推薦hahow線上學習python: https://igrape.net/30afN
去除列表中的重复值并保持元素顺序,除了使用 dict.fromkeys() 之外,还可以采用以下三种方法:
1. 使用有序集合(OrderedDict)
与 dict.fromkeys() 类似,collections.OrderedDict 同样可以用来去除重复元素并保持顺序。这在 Python 3.6 之前的版本中尤其有用,因为那时的普通字典还不保持插入顺序。
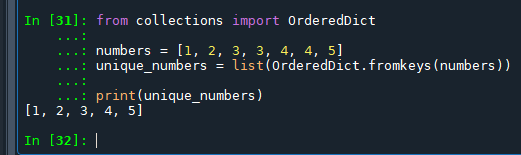
from collections import OrderedDict
numbers = [1, 2, 3, 3, 4, 4, 5]
unique_numbers = list(OrderedDict.fromkeys(numbers))
print(unique_numbers)OrderedDict.fromkeys()
2. 利用循环和集合
这种方法通过手动检查已见元素,结合使用集合(快速检查是否已存在元素)和列表(保持元素顺序)来实现:
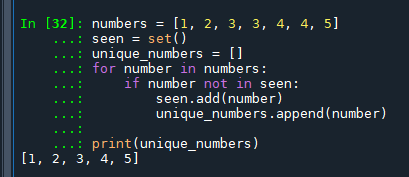
这种方法的优点是清晰易懂,且你可以在循环中添加更多的逻辑处理。
3. 使用列表推导式
列表推导式可以结合集合来去除重复项,这种方法是上述循环方法的紧凑版本:
numbers = [1, 2, 3, 3, 4, 4, 5]
seen = set()
unique_numbers = [x for x in numbers if not (x in seen or seen.add(x))]
print(unique_numbers)[x for x in numbers if not (x in seen or seen.add(x))]

这里使用了一个小技巧:seen.add(x) 在添加元素的同时返回 None,因此 not (x in seen or seen.add(x)) 会在 x 不在 seen 中时评估为 True。
总结
这些方法各有优缺点:
- OrderedDict 和 dict.fromkeys() 方法简洁且利用了内建数据结构的特性。
- 循环和集合 方法在处理过程中提供了更高的可定制性,易于添加额外的逻辑。
- 列表推导式 提供了一种简洁且高效的解决方案,但可能在可读性上略逊一筹。
你可以根据具体的应用场景和个人偏好选择最合适的方法。
表达式 (x in seen or seen.add(x)) 在 Python 中是利用了逻辑运算符的短路行为以及集合的性质来实现快速检查和添加元素的目的。让我们逐步解析这个表达式:
逻辑运算符的短路行为
在 Python 中,逻辑运算符 or 和 and 都有所谓的”短路”行为:
or:如果or运算符的左侧表达式为True,则整个表达式的结果立即确定为True,右侧表达式不会被评估。and:如果and运算符的左侧表达式为False,则整个表达式的结果立即确定为False,右侧表达式不会被评估。
表达式的组成
x in seen:检查x是否已经存在于集合seen中。如果存在,这个表达式的结果为True。seen.add(x):将x添加到集合seen中。add方法没有返回值,因此其结果为None,在布尔上下文中被视为False。
表达式的工作原理
当使用 (x in seen or seen.add(x)) 时,其执行流程如下:
x in seen首先被评估:- 如果
x已经在集合seen中,那么x in seen返回True。由于or的短路性质,整个表达式立即返回True,seen.add(x)不会被执行。 - 如果
x不在集合seen中,那么x in seen返回False。
- 如果
- 当
x in seen为False时,表达式继续执行seen.add(x):seen.add(x)将x添加到集合中,但此方法返回None,即在布尔上下文中视为False。
因此,整个表达式 (x in seen or seen.add(x)) 的结果总是 False:
- 如果
x已经存在,则x in seen为True,但由于or的结果取决于x in seen,所以整个表达式的结果看似True,但seen.add(x)不会执行。 - 如果
x不存在,则x in seen为False,seen.add(x)执行添加操作,但返回None,因此表达式结果为False。
使用场景
在列表推导式中,我们可以看到这样的使用:unique_numbers = [x for x in numbers if not (x in seen or seen.add(x))]
这里的 not (x in seen or seen.add(x)) 用于确认 x 是否之前未出现过并添加 x 到 seen。只有当 x 是新元素时,not (False) 即 True,x 才会被添加到结果列表 unique_numbers 中。这是一种既简洁又有效的方法来过滤出列表中的唯一元素。
關鍵在於 if not (x in seen or seen.add(x)) 這個條件:
- seen.add(x) 會將 x 加入 set 並返回 None
- Python 的 or 運算符具有短路特性
- 執行過程:
- 對於 x=1:
- 1 不在 seen 中
- seen.add(1) 執行
- None 被 not 轉為 True
- 1 被保留
- 對於 x=3(第二次出現):
- 3 已在 seen 中
- seen.add(3) 不會執行
- True 被 not 轉為 False
- 3 不被保留
- 對於 x=1:
這個方法很巧妙,但可能不如 dict.fromkeys() 直觀。它的優點是只遍歷一次列表。
推薦hahow線上學習python: https://igrape.net/30afN


 #可輸入多個參數 #有/無參數,有/無回傳值,四種自定義函數")
![Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313184351_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]")
)")

, list(n)*m #有m個元素n, ndarray.tolist()可以將array轉為list")



近期留言