code:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 15 06:30:23 2024
@author: SavingKing
"""
import os
import json
import jieba
import numpy as np
folder = r"D:\Python code\240107_爬蟲"
fname = "my_lis_msg_backup.json"
fpath = os.path.join(folder,fname)
#'D:\\Python code\\240107_爬蟲\\my_lis_msg.json'
with open(fpath,"r",encoding="UTF-8") as f:
dic = json.load(f)
k0 = list(dic.keys())[0]
lis = dic[k0]
lis2D = []
for strr in lis:
lis_jieba = jieba.lcut(strr)
lis2D.append(lis_jieba)
lenN = len( lis2D )
#951
lis2D_flatten = []
for ele in lis2D:
lis2D_flatten.extend(ele)
#len = 9051
rm = [ ',', '。', '、', ';', ':', '“', '”', '?', '!', '(', ')', '《', '》', '...',
'的', '是', '在', '有', '和', '也', '了', '不', '人', '我', '他', '之', '為', '與',
'大', '來', '到', '上', '就', '很', '個', '去', '而', '要', '會', '可以', '你',
'對', '着', '還', '但', '年', '這', '那', '得', '着', '中', '一個',' ', '/', '\n','.'
'都','元','喔','說','沒',"1","2","4","7","(",")", "?","=", "+", ",",",","...","吧","才"
# 可以繼續添加更多的詞
]
for strr in rm:
if strr in lis2D_flatten:
while strr in lis2D_flatten:
lis2D_flatten.remove(strr)
dic_term_freq = {}
for term in lis2D_flatten:
if term in dic_term_freq:
dic_term_freq[term] += 1/len(lis2D_flatten)
else:
dic_term_freq[term] = 1/len(lis2D_flatten)
print("dic_term_freq:",dic_term_freq)
#出現最多的是那些詞? 詞頻多少?
max_count = max(dic_term_freq.values())
lis_max_count=[]
for k in dic_term_freq:
if dic_term_freq[k] == max_count:
lis_max_count.append(k)
print("max_count:",max_count)
print("lis_max_count:",lis_max_count)
#若沒有事先去掉不重要的詞
#lis_max_count: [',']
#詞頻最高的是 不重要的標點符號
#使用IDF過濾
set_lis2D_flatten = set(lis2D_flatten )
#去掉重複的詞,節省for迴圈次數
dic_IDF = {}
for strr in set_lis2D_flatten:
cnt= 0
for i in range(lenN):
if strr in lis2D[i]:
cnt+=1
idf = np.log(lenN/cnt)
dic_tmp = {strr:idf}
dic_IDF.update(dic_tmp)
max_IDF = max(dic_IDF.values())
lis_max_IDF = []
for word in dic_IDF:
if dic_IDF[word] == max_IDF:
lis_max_IDF.append(word)
# =============================================================================
# print("max_IDF:",max_IDF)
# print("lis_max_IDF:",lis_max_IDF)
# =============================================================================
dic_TFxIDF = {}
for word in dic_IDF.keys():
tf = dic_term_freq [word]
idf = dic_IDF [word]
dic_tmp = {word:tf*idf}
dic_TFxIDF.update(dic_tmp)
max_TFxIDF = max(dic_TFxIDF.values())
lis_max_TFxIDF = []
for word in dic_TFxIDF:
if dic_TFxIDF[word] == max_TFxIDF:
lis_max_TFxIDF.append(word)
print("max_TFxIDF:",max_TFxIDF)
#生成文字雲
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 創建一個文字雲實例
wordcloud = WordCloud(
width = 800, # 宽度
height = 800, # 高度
background_color ='white', # 背景颜色
min_font_size = 10, # 最小字體大小
font_path='C:\\Windows\\Fonts\\kaiu.ttf' #標楷體
) #type: wordcloud.wordcloud.WordCloud
# 生成文字雲
wordcloud.generate_from_frequencies(dic_TFxIDF)
# 可視化顯示
plt.figure(figsize = (8, 8), facecolor = None)
#8 inchs = 8*2.54cm = 20.32 cm
plt.imshow(wordcloud)
plt.axis("off") # 關閉座標軸
# plt.tight_layout(pad = 0)
plt.show()前半部為計算Term Frequency(TF)
Inverse Document Frequency(IDF)
TF*IDF
文字雲部分為最結尾:
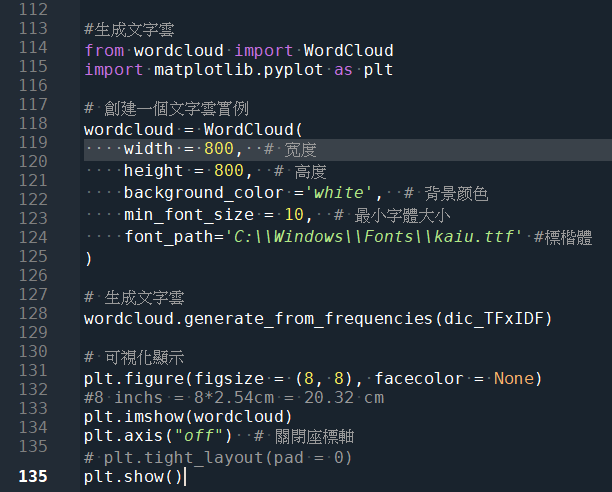
生成的文字雲:

推薦hahow線上學習python: https://igrape.net/30afN
或者將python生成的資料:
好看 49
可以 27
真的 17
回饋 16
100 15
這麼 15
https 14
直接貼進去Tableau中
也可以用Tableau生成文字雲
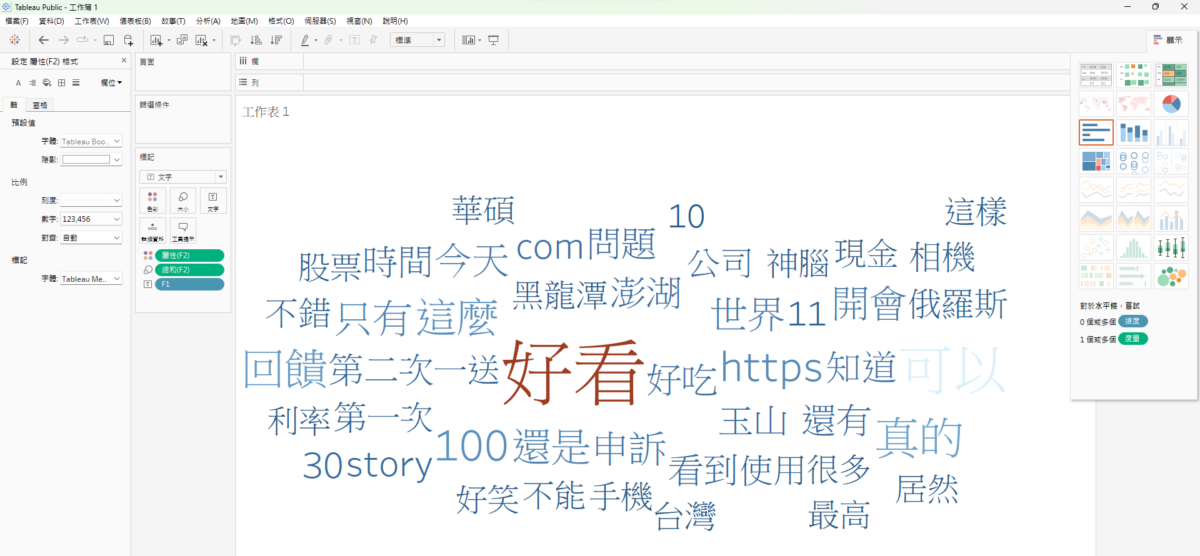
推薦hahow線上學習python: https://igrape.net/30afN
")
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df[‘Salary’] = df[‘Salary’].map( ‘${:,.2f}’ .format)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230527091636_49.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df[‘Salary’] = df[‘Salary’].map( ‘${:,.2f}’ .format)")
![Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/04/20230418154049_50.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask")

 #獲取時間戳; localtime = time.localtime( timestamp ) #獲取localtime; fmt= ‘%Y-%m-%d %H:%M:%S’ ; strftime = time.strftime(fmt, localtime) 等效於 datetime.datetime.now().strftime(fmt) #獲取strftime #str format time ;")
, list(n)*m #有m個元素n, ndarray.tolist()可以將array轉為list")
 vs 非貪婪 (Lazy) ; .* vs .*?")

![Python TQC考題610 平均溫度,不要自找麻煩用2D list做,可練習2D轉1D: 一維串列.extend(二維串列[index])](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220515192908_35.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題610 平均溫度,不要自找麻煩用2D list做,可練習2D轉1D: 一維串列.extend(二維串列[index])")

近期留言