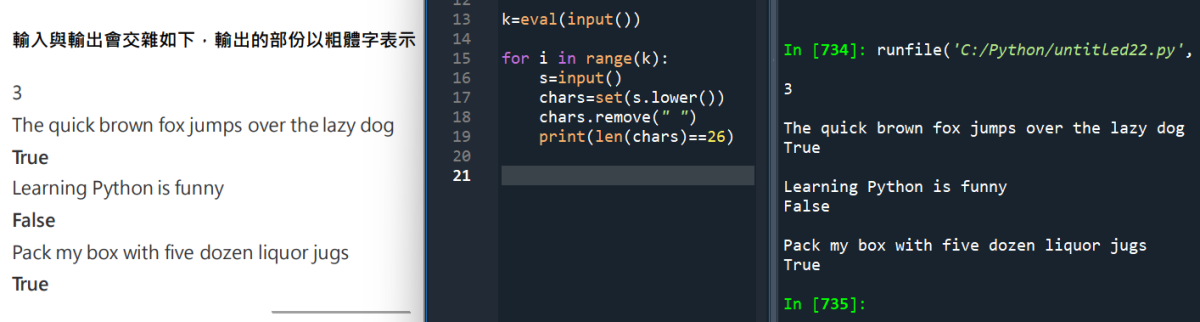
#Python TQC考題706 全字母句
k=eval(input())
for i in range(k):
s=input()
chars=set(s.lower())
#set沒有重複值
chars.remove(” “)
print(len(chars)==26)
#做第二次:
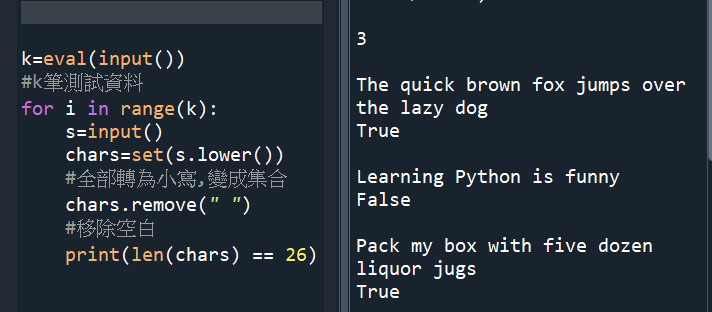
#str1.replace(” “,””) 把空白取代為什麼都沒有
#不能用.strip(),只會去除左右兩邊的空白
#中間的空白無法用.strip()去除
#重點是記得用set()做
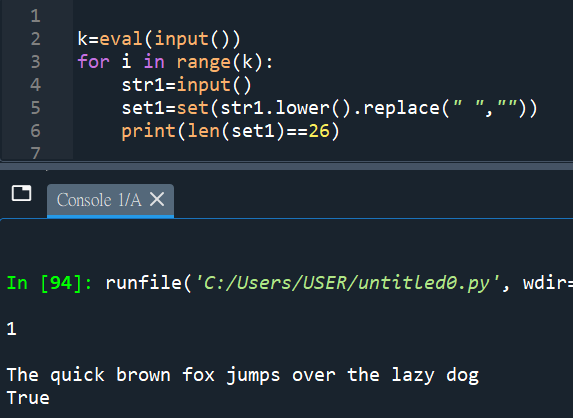
“””
這次做複雜了
set(str)就可以將字串拆分為各字母
不用透過list()中介
“””
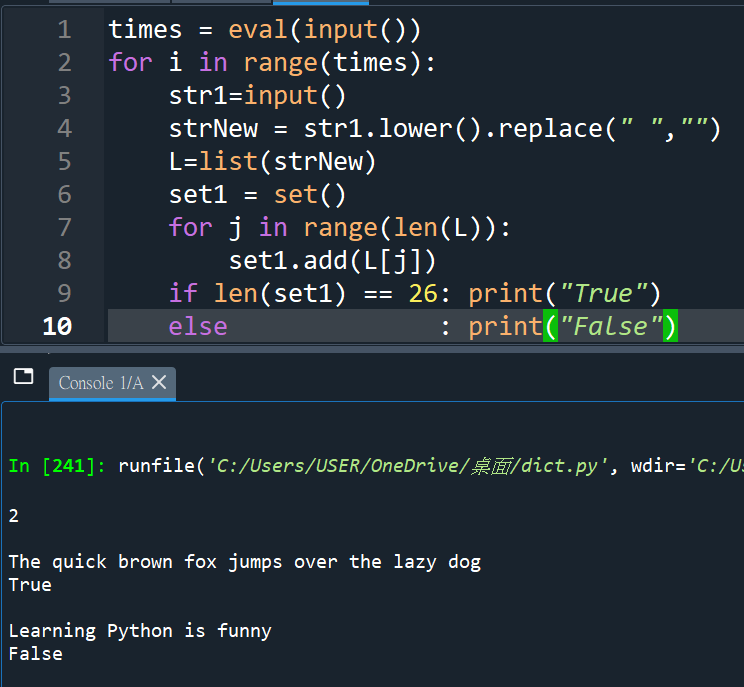
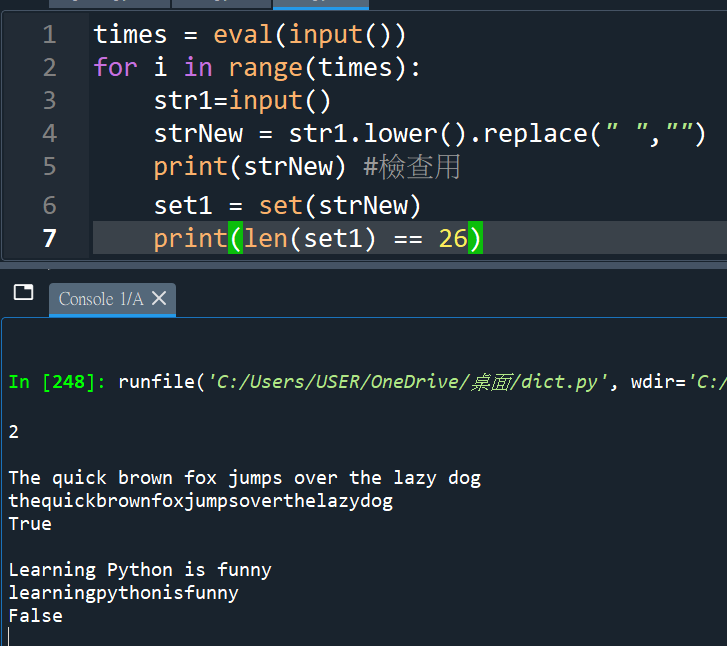
“””
做回原本簡單的作法
list使用.remove(” “) 移除空白
str使用.replace(” “,”” )
將空白取代為什麼都沒有
且要用strNew承接replace後的字串
“””
“””
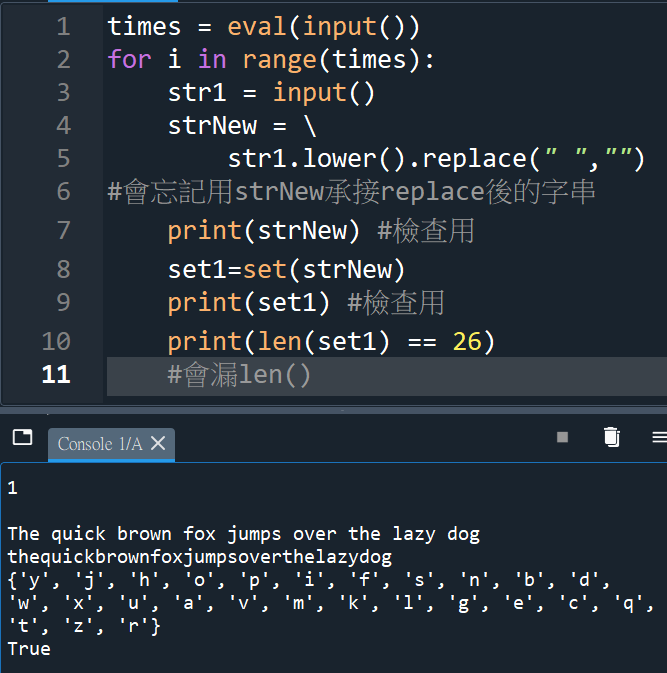
雖然簡單,還是會小漏
例如:忘記使用strNew
承接.replace()後的字串
最後一行的len()也會遺漏
“””
 ; table = Table(child, doc)")
 ; 如何將資料夾中的多個csv檔求平均?")

![Python TQC 510 費氏數列,list[], f.append(n3)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220522152013_66.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC 510 費氏數列,list[], f.append(n3)")
, candidates, n=1, cutoff=0.6)")

)")
![Python Pathlib 實戰:優雅地篩選多種圖片檔案; images = [f for f in p.glob(“*”) if f.suffix.lower() in img_extensions]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260128111659_0_736612.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Pathlib 實戰:優雅地篩選多種圖片檔案; images = [f for f in p.glob(“*”) if f.suffix.lower() in img_extensions]")
 與 re.split() 的用法與比較")

近期留言