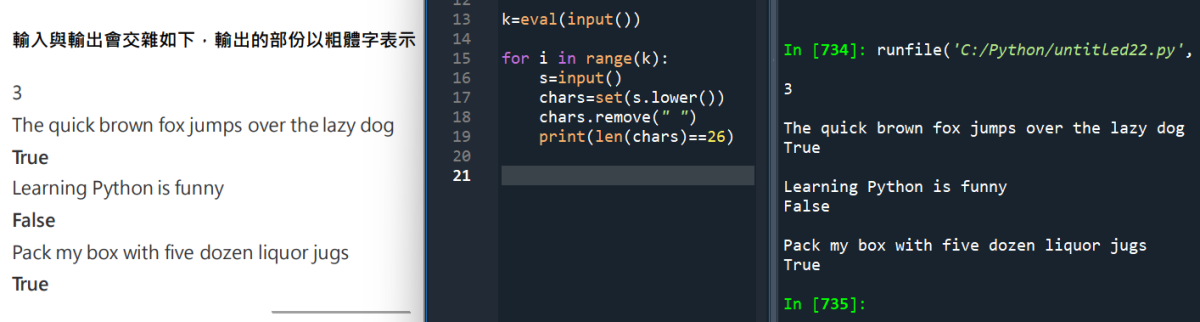
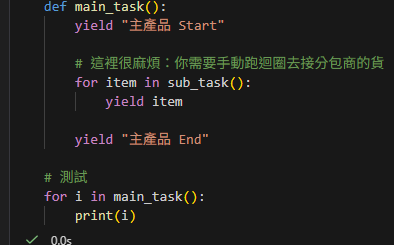
#Python TQC考題706 全字母句
k=eval(input())
for i in range(k):
s=input()
chars=set(s.lower())
#set沒有重複值
chars.remove(” “)
print(len(chars)==26)
#做第二次:
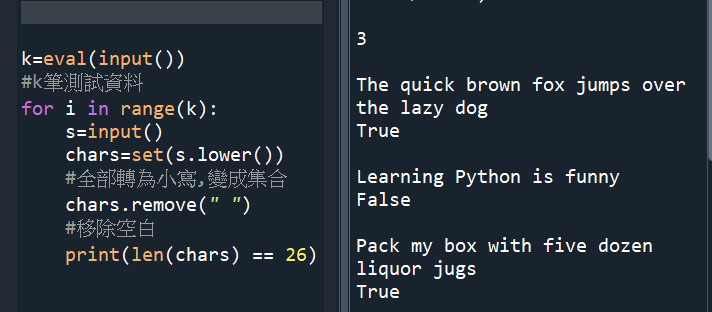
#str1.replace(” “,””) 把空白取代為什麼都沒有
#不能用.strip(),只會去除左右兩邊的空白
#中間的空白無法用.strip()去除
#重點是記得用set()做
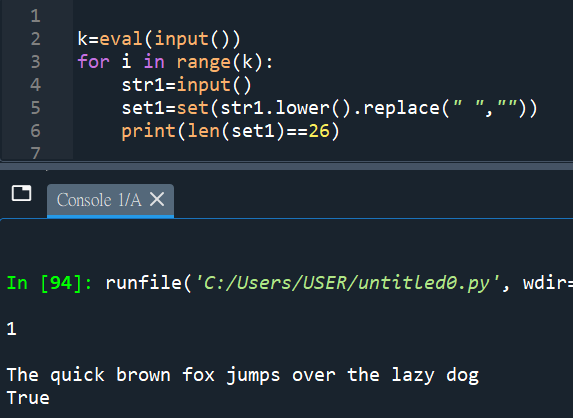
“””
這次做複雜了
set(str)就可以將字串拆分為各字母
不用透過list()中介
“””
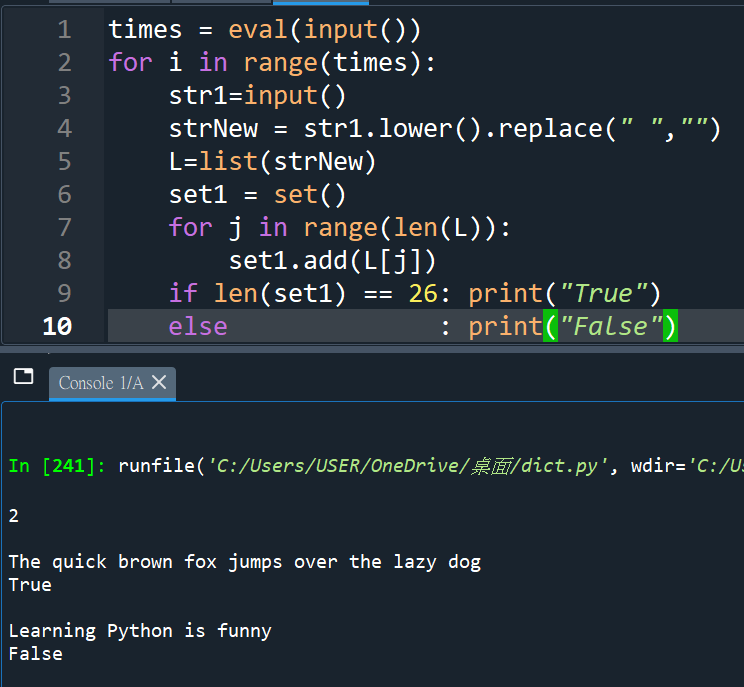
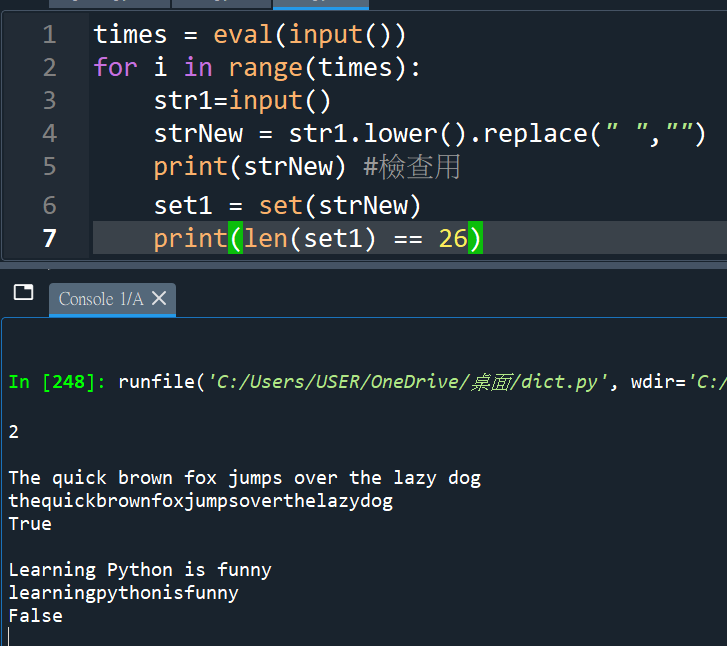
“””
做回原本簡單的作法
list使用.remove(” “) 移除空白
str使用.replace(” “,”” )
將空白取代為什麼都沒有
且要用strNew承接replace後的字串
“””
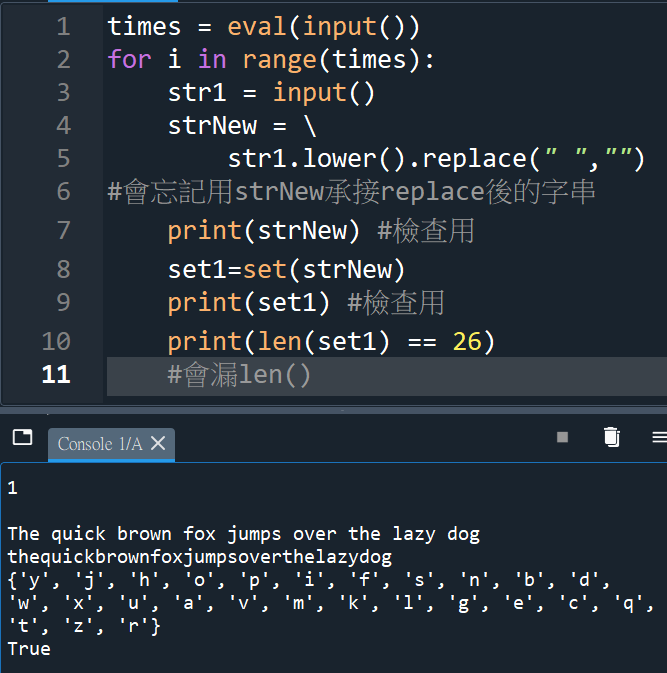
“””
雖然簡單,還是會小漏
例如:忘記使用strNew
承接.replace()後的字串
最後一行的len()也會遺漏
“””
.resolve().parent")
)")
![Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220923222039_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言")
![Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/05/20260527141829_0_5a8a75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?")
 ; median_np = numpy .nanmedian(arr)")
![Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/06/20250609143758_0_53821c.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )")


 ,19歲奧運跆拳銅牌美少女羅嘉翎的國光獎金,應該一次領500萬?還是終身月領2.4萬?Excel財務函數PMT, RATE, NPER, PV, FV")

近期留言