# -*- coding: utf-8 -*-
"""
Created on Fri Jun 06 08:13:12 2024
@author: SavingKing
"""
import re
import pandas as pd
def strr2dict(strr) -> dict:
"""
Parameters
----------
strr : str
日誌字符串,例如:
' 2024-02-19 11:44:43,179 INFO - [opentest_boost.process_steps.boosted_step:987] MEASUREMENT >>> NAME: sensor-count STATUS: PASSED VALUE: 129 LL: 129 UL: '
Returns
-------
dict
解析後的字典,例如:
{'name': 'sensor-count', 'status': 'PASSED', 'value': '129', 'll': '129', 'ul': ''}
"""
strr_end = strr.split(">>>")[-1].lstrip()
pattern = re.compile(
r'NAME: (?P<name>[\w-]+) STATUS: (?P<status>\w+) VALUE: (?P<value>[\d.-]*) (LL: (?P<ll>[\d.-]*) )?(UL: (?P<ul>[\d.-]*))?'
)
"""
pattern = re.compile(
r'NAME: (?P<name>[\w-]+) STATUS: (?P<status>\w+) VALUE: (?P<value>[\d.-]*) LL: (?P<ll>[\d.-]*)? UL: (?P<ul>[\d.-]*)?'
)
"""
match = pattern.search(strr_end)
if match:
log_dict = match.groupdict()
return log_dict
else:
print(f"Regular expression not found in {strr_end}")
return {}
def parse_logs(wanted):
"""
解析日誌列表並返回包含字典的列表。
Parameters
----------
wanted : list
包含日誌字符串的列表。
Returns
-------
list
包含解析後的字典的列表。
"""
lis_json = []
for strr in wanted:
log_dict = strr2dict(strr)
lis_json.append(log_dict)
return lis_json
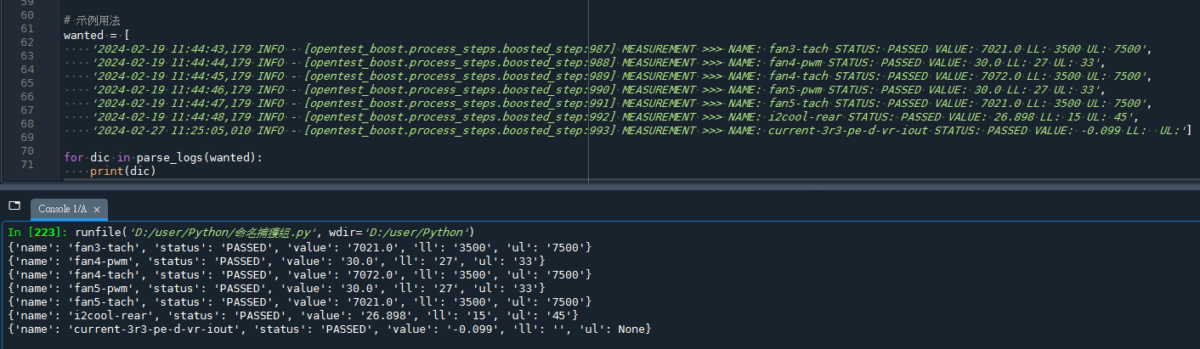
# 示例用法
wanted = [
'2024-02-19 11:44:43,179 INFO - [opentest_boost.process_steps.boosted_step:987] MEASUREMENT >>> NAME: fan3-tach STATUS: PASSED VALUE: 7021.0 LL: 3500 UL: 7500',
'2024-02-19 11:44:44,179 INFO - [opentest_boost.process_steps.boosted_step:988] MEASUREMENT >>> NAME: fan4-pwm STATUS: PASSED VALUE: 30.0 LL: 27 UL: 33',
'2024-02-19 11:44:45,179 INFO - [opentest_boost.process_steps.boosted_step:989] MEASUREMENT >>> NAME: fan4-tach STATUS: PASSED VALUE: 7072.0 LL: 3500 UL: 7500',
'2024-02-19 11:44:46,179 INFO - [opentest_boost.process_steps.boosted_step:990] MEASUREMENT >>> NAME: fan5-pwm STATUS: PASSED VALUE: 30.0 LL: 27 UL: 33',
'2024-02-19 11:44:47,179 INFO - [opentest_boost.process_steps.boosted_step:991] MEASUREMENT >>> NAME: fan5-tach STATUS: PASSED VALUE: 7021.0 LL: 3500 UL: 7500',
'2024-02-19 11:44:48,179 INFO - [opentest_boost.process_steps.boosted_step:992] MEASUREMENT >>> NAME: i2cool-rear STATUS: PASSED VALUE: 26.898 LL: 15 UL: 45',
'2024-02-27 11:25:05,010 INFO - [opentest_boost.process_steps.boosted_step:993] MEASUREMENT >>> NAME: current-3r3-pe-d-vr-iout STATUS: PASSED VALUE: -0.099 LL: UL:']
for dic in parse_logs(wanted):
print(dic)
輸出結果:
正則表達式
pattern = re.compile(
r'NAME: (?P<name>[\w-]+) STATUS: (?P<status>\w+) VALUE: (?P<value>[\d.-]*) LL: (?P<ll>[\d.-]*)? UL: (?P<ul>[\d.-]*)?'
)逐部分解释
r'...':- 字符串前的
r表示这是一个原始字符串(raw string),这样在字符串中反斜杠\不需要被转义。
- 字符串前的
NAME: (?P<name>[\w-]+):NAME:: 匹配字符串 “NAME:”。(?P<name>[\w-]+): 命名捕获组,名称为name。(?P<name>...): 定义了一个命名捕获组,组名为name。[\w-]+: 匹配一个或多个字母、数字、下划线或连字符。\w等价于[a-zA-Z0-9_]。
STATUS: (?P<status>\w+):STATUS:: 匹配字符串 “STATUS:”。(?P<status>\w+): 命名捕获组,名称为status。(?P<status>...): 定义了一个命名捕获组,组名为status。\w+: 匹配一个或多个字母、数字或下划线。
VALUE: (?P<value>[\d.-]*):VALUE:: 匹配字符串 “VALUE:”。(?P<value>[\d.-]*): 命名捕获组,名称为value。(?P<value>...): 定义了一个命名捕获组,组名为value。[\d.-]*: 匹配零个或多个数字、点或连字符。\d等价于[0-9]。
LL: (?P<ll>[\d.-]*)?:LL:: 匹配字符串 “LL:”。(?P<ll>[\d.-]*)?: 命名捕获组,名称为ll,并且整个捕获组是可选的。(?P<ll>...): 定义了一个命名捕获组,组名为ll。[\d.-]*: 匹配零个或多个数字、点或连字符。?: 表示前面的整个捕获组是可选的,可以出现零次或一次。
UL: (?P<ul>[\d.-]*)?:UL:: 匹配字符串 “UL:”。(?P<ul>[\d.-]*)?: 命名捕获组,名称为ul,并且整个捕获组是可选的。(?P<ul>...): 定义了一个命名捕获组,组名为ul。[\d.-]*: 匹配零个或多个数字、点或连字符。?: 表示前面的整个捕获组是可选的,可以出现零次或一次。
解释总结
这个正则表达式模式用于匹配类似以下格式的字符串:
NAME: tmp461-front-inlet STATUS: OK VALUE: 25.5 LL: 20.0 UL: 30.0
具体匹配内容和对应的命名捕获组为:
NAME: 匹配 tmp461-front-inlet 到 name 捕获组。
STATUS: 匹配 OK 到 status 捕获组。
VALUE: 匹配 25.5 到 value 捕获组。
LL: 匹配 20.0 到 ll 捕获组(可选)。
UL: 匹配 30.0 到 ul 捕获组(可选)。
通过使用命名捕获组和 groupdict() 方法,可以轻松地将匹配的子字符串提取到一个字典中,便于后续处理。,班排名=SUMPRODUCT((班級=A2)*(平均>M2))+1,設定格式化的條件")
 ; np.hstack(tuple) ; ravel(“F”) #解開(線團等),把二維array轉成一維")

 +(1個以上) ?(0 or 1個) 與貪婪/非貪婪, ? 的多重角色(量詞、非貪婪修飾、語法)")

; from bs4 import BeautifulSoup")
")
 完全指南; status = “成年” if age >= 18 else “未成年” ; 值_如果為真 if 條件判斷 else 值_如果為假 #取這個值 (如果條件成立),否則 (取那個值)")
:台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免")



近期留言