K-近鄰演算法(K Nearest Neighbor ,簡稱 KNN):

KNN 需要資料的 N 個屬性都是順序尺度,
可以比大小,可以比遠近,這樣才能算距離

from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split

sklearn

predict
predict_proba


部分資料:
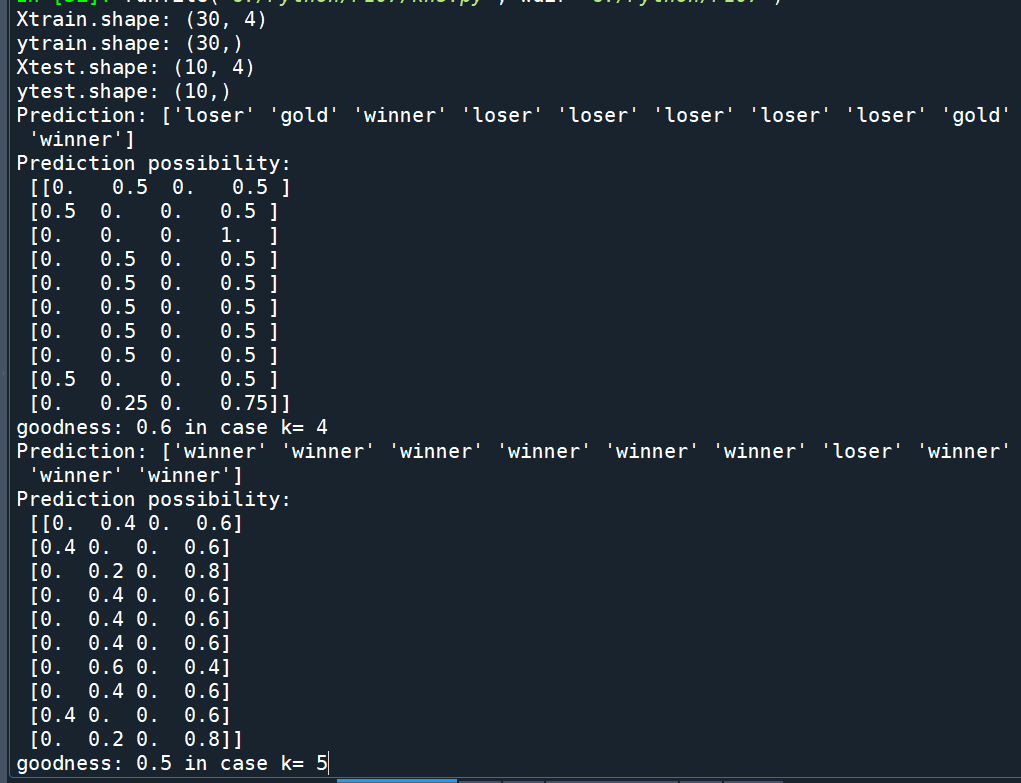
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
folder = “C:\Python\P107\doc”
fname = “student.csv”
import os
fpath = os.path.join(folder,fname)
# fpath = folder + “\\” + fname #同義
df = pd.read_csv(fpath,header=None,skiprows=[0])
df.to_excel(os.path.join(folder,”knsDF.xlsx”))
#df.index.size = 40 #df.columns.size = 5
X = df.drop([4],axis=1).values
#drop([0,4])可以提高score
#第0欄類似index, 非資料
#score仍勝出KNN去掉第0欄
y = df[4].values
Xtrain, Xtest, ytrain, ytest =\
train_test_split(X,y,test_size=0.25,
random_state= 42 ,shuffle =True)
XtestDF = pd.DataFrame(Xtest)
XtestDF.to_excel(os.path.join(folder,”knsXtest.xlsx”))
print(“Xtrain.shape:”,Xtrain.shape) #(30, 3)
print(“ytrain.shape:”,ytrain.shape) #(30,)
print(“Xtest.shape:”,Xtest.shape) #(10, 3)
print(“ytest.shape:”,ytest.shape) #(10,)
for k in range(4,11):
kns = KNeighborsClassifier(n_neighbors=k)
kns.fit(Xtrain,ytrain)
ypred = kns.predict(Xtest)
ypred2 = kns.predict_proba(Xtest)
print(“Prediction:”,ypred)
print(“Prediction possibility:\n”,ypred2)
howgood = kns.score(Xtest,ytest)
print(“goodness:”,howgood,”in case k=”,k)
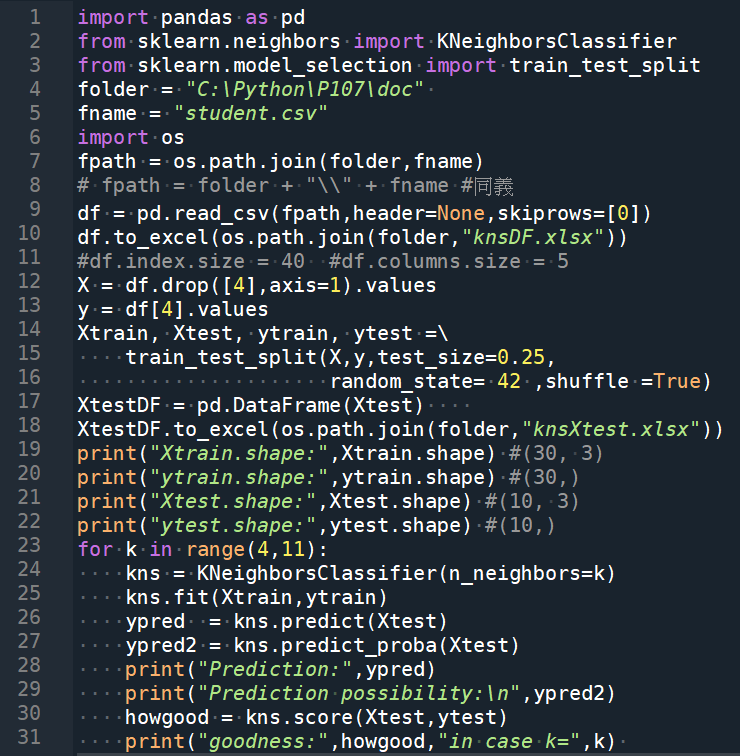
部分輸出結果:
![Python: 如何判斷字符串內容是否為數字(整數或浮點數)? isinstance( eval( entry.get() ), (float, int) ) ; str.isdigit() #不包括小數點和負號 ; try~ except ValueError~ ; 正則表示法 regular expression ; pattern = ‘^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$’](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230512152430_3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何判斷字符串內容是否為數字(整數或浮點數)? isinstance( eval( entry.get() ), (float, int) ) ; str.isdigit() #不包括小數點和負號 ; try~ except ValueError~ ; 正則表示法 regular expression ; pattern = ‘^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$’")
 as f: json_str = f.read() ; jsn = json.loads(json_str)")
? 如何做出計算機? eval() 可將字串還原為python指令")
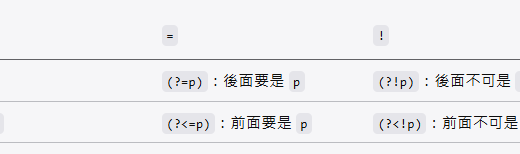
中 if 的位置差異; if 放在後面 (過濾條件) ; if 放在前面 (三元運算符)")
如何一次讀出所有keys, values, items? dic.keys() ; set(dic) 無序; dic.values() ; dic.items()")

![Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313184351_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]")
![Python TQC考題404 數字反轉判斷,n_rev=n[::-1], list1.reverse()](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220825152414_97.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題404 數字反轉判斷,n_rev=n[::-1], list1.reverse()")

![為什麼 Python 要用 `max` 配合 `key=lambda`?從找最長文字的 Span 談起 ; #spans:list[dict] ; max(spans, key=lambda s: len(s.get("text", ""))) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/06/20260602132524_0_c45d06-520x245.png)

近期留言