新光人壽美添109建議書如下
若想了解IRR 5%的香港保單或其他台灣保單
複委託優惠或YTM超過6%的債券
請在此表單留下聯絡資料:
若您願意贊助我:
機構代號(391,一卡通),帳號:1501823311
FB粉絲團: 儲蓄保險王,
Line@: @wvr5039s,
Line社群: https://lihi1.com/MaSdv/blog
twitter: https://twitter.com/SavingKing925
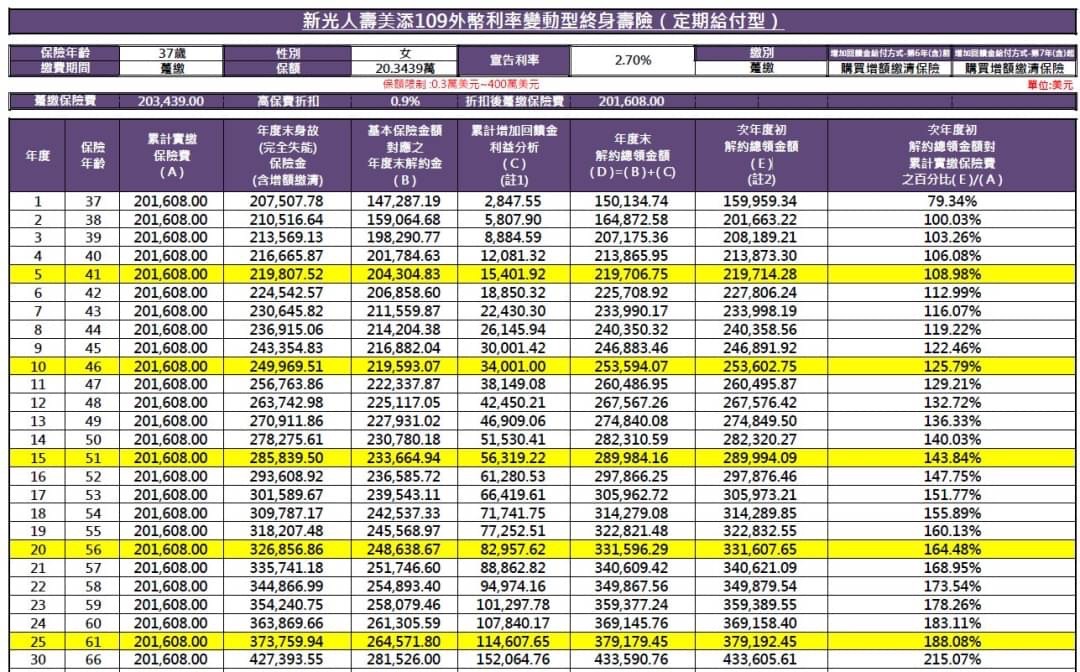
以下的cashFlow.txt
副檔名.csv亦可,
內容就是逗點分隔檔
每列現金流狀況與建議書一致
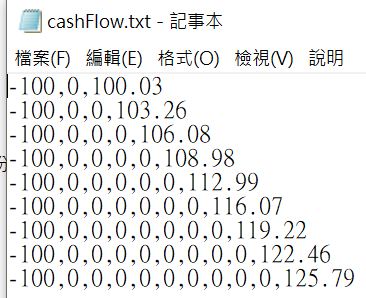
程式碼:
import csv
import numpy_financial as npf
import numpy as np
base = 0.01 # 基準利率1%,隨便key的,不用認真
year_IRR = [(“Year”, “IRR”, “絕對利差”, “相對利差”)]
with open(r”C:\Python\example\csvreader\cashFlow.txt”, “r”) as f:
csvreader = csv.reader(f)
csvlst = [r for r in csvreader]
# print(csvlst) #2D list,且都為字串,非數字
# 以下雙層for迴圈,把字串都轉成數字
for r in range(len(csvlst)):
for c in range(len(csvlst[r])):
csvlst[r][c] = eval(csvlst[r][c])
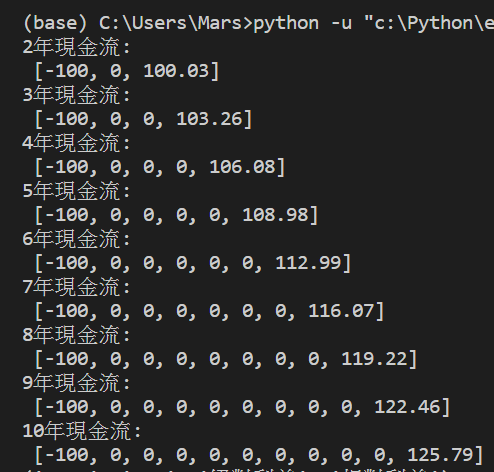
for r in csvlst:
print(f”{r.index(r[-1])}年現金流:\n”, r)
# 看起來沒問題,元素都是數字
for row in csvlst:
csvAry = np.array(row)
myirr = round(npf.irr(csvAry), 4)
# round函數本身的問題,有的資料取小數點下4位失敗
rateDiff = myirr – base # 絕對利差
rateDiffRel = rateDiff/base # 相對利差
year = row.index(csvAry[-1])
yearStr = “%02d” % year
myirrStr = “%.2f %%” % (myirr*100)
rateDiffStr = “%.2f %%” % (rateDiff*100)
rateDiffRelStr = “%.2f %%” % (rateDiffRel*100)
tup = (yearStr, myirrStr, rateDiffStr, rateDiffRelStr)
year_IRR.append(tup)
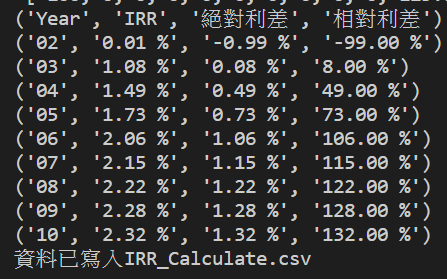
for ele in year_IRR:
print(ele)
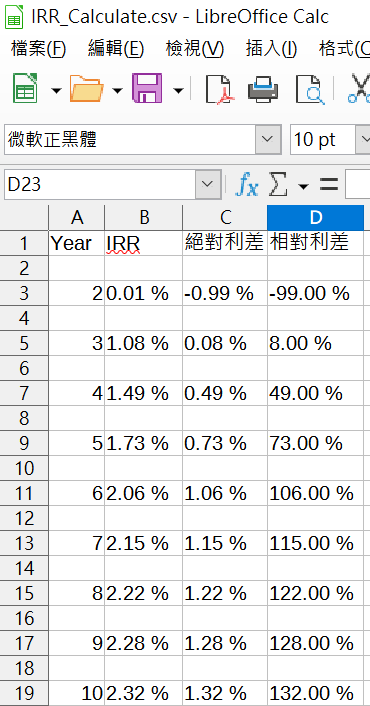
with open(r”C:\Python\example\csvreader\IRR_Calculate.csv”, “w”) as f2:
csv.writer(f2).writerows(year_IRR)
print(“資料已寫入IRR_Calculate.csv”)
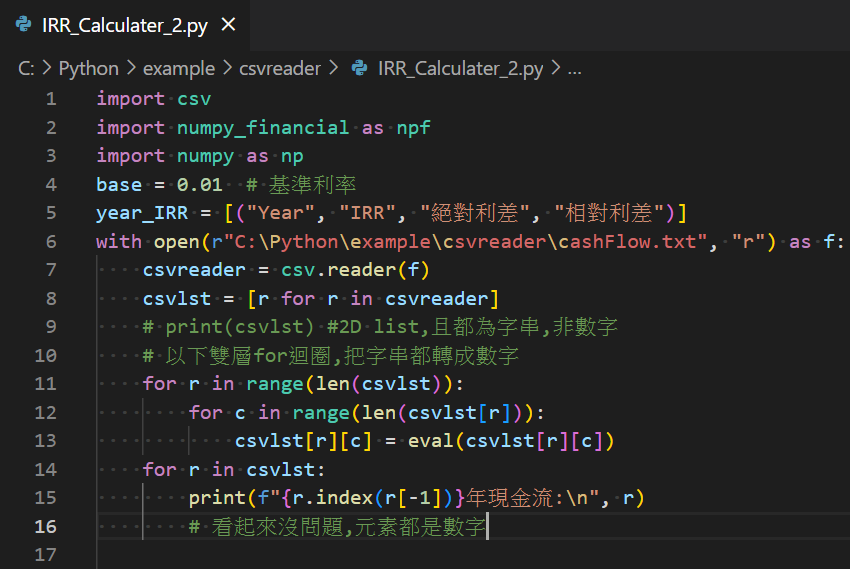
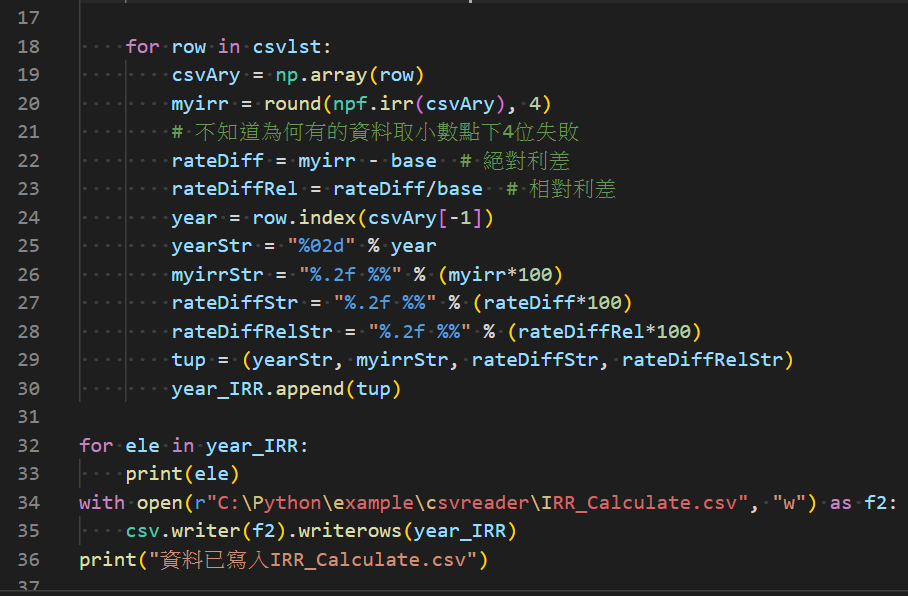
輸出結果:
寫出的csv檔:
![Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230222082954_53.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)")
 ? 如何搭配portable Chrome? from selenium.webdriver.common.by import By ; from selenium.webdriver.chrome.options import Options ; option = Options() ; option.binary_location = chrome_portable_path")

![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/03/20250330190318_0_925655.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)")
如何設定sep參數才能讀取分隔子同時有, ” ” (空白)的csv檔? df = pd.read_csv(‘test.txt’, sep = ‘\s*,\s*|\s+’, engine=’python’)")

)")
![Python 進階技巧:海象運算子 (Walrus Operator) 實戰教學 [w_clean for w in words if (w_clean:=w.lower().strip()) and w_clean not in STOPWORDS]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/02/20260210083748_0_a7d9bf.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 進階技巧:海象運算子 (Walrus Operator) 實戰教學 [w_clean for w in words if (w_clean:=w.lower().strip()) and w_clean not in STOPWORDS]")



近期留言