code:
my_list = [1, 2, 3, 2, 4, 2, 5]
target = 2
# 使用列表推导式找出所有 target 的索引
indexes = [index for index, value in enumerate(my_list) if value == target]
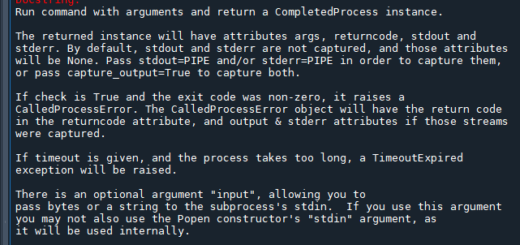
print(indexes)輸出結果:
![Python: list.index() 只能找到第一個元素的index,若元素有重複,如何找出所有index? indexes = [index for index, value in enumerate(my_list) if value == target] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/10/20241010101057_0_74ffb7.png)
enumerate(my_list) 會遍歷列表 my_list 並提供每個元素的索引(index)和值(value)。
列表推導式檢查每個 value 是否等於 target。如果 value 等於 target,它就會將當前的 index 添加到列表 indexes 中。
最終 indexes 包含所有 target 值的索引。
這種方法簡單且高效,特別適用於查找列表中所有重覆元素的索引。
推薦hahow線上學習python: https://igrape.net/30afN

![Python: 字串 str.find(關鍵字[,start][,end]),找不到的話回傳-1,如何找出資料字串中,所有關鍵字的index?詞頻計算](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221122100657_32.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 字串 str.find(關鍵字[,start][,end]),找不到的話回傳-1,如何找出資料字串中,所有關鍵字的index?詞頻計算")
 方法處理鍵不存在的情況; apple_count = my_dict .get( ‘apple’ , 0) # 如果鍵存在,返回對應的值,否則返回預設值 0")
![Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220901154435_19.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()")
 #zinfo_or_arcname: ZipInfo | str ; data: bytes | str")
串接; numpy.concatenate() ; pandas.concat() ; 擴充ndarray的維度 np.expand_dims()")
, math.pow(), ** 次方")

,計算香港保單富衛人壽(FWD)盈聚優裕(UFE1)IRR,免費下載IRR計算機")


近期留言