sort_values() 是 pandas 中最常用的排序方法,
它可以按指定欄位對資料進行排序。
讓我用一個簡單的例子來解釋:
基本例子:水果價格表
import pandas as pd
# 創建簡單的水果價格表
fruits_df = pd.DataFrame({
'水果': ['蘋果', '香蕉', '橙子', '草莓', '藍莓'],
'價格': [30, 15, 25, 80, 120],
'庫存': [100, 200, 80, 50, 30]
})
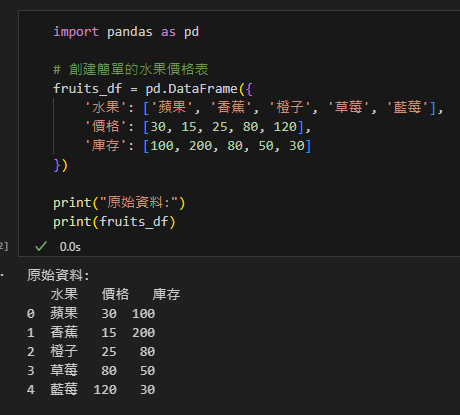
print("原始資料:")
print(fruits_df)輸出:
單一欄位排序:
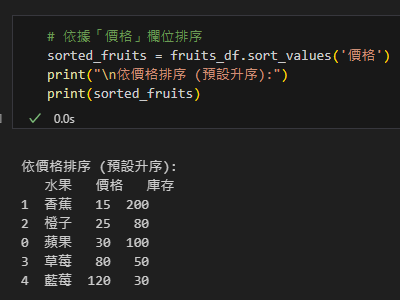
# 依據「價格」欄位排序
sorted_fruits = fruits_df.sort_values('價格')
print("\n依價格排序 (預設升序):")
print(sorted_fruits)輸出:
降序排序
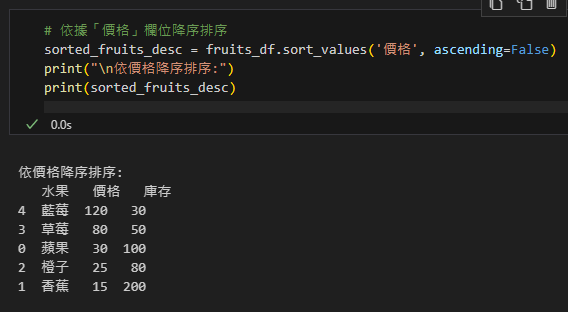
# 依據「價格」欄位降序排序
sorted_fruits_desc = fruits_df.sort_values('價格', ascending=False)
print("\n依價格降序排序:")
print(sorted_fruits_desc)輸出:
推薦hahow線上學習python: https://igrape.net/30afN

 ; 那些參數可以設為None?")
 讀取csv檔案?若該檔案奇異列長度太短,如何用try:~except:~避免取直欄時出現IndexError: list index out of range?")

 as z: print(z.namelist()) ; z.infolist()")
![Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/07/20230717184401_87.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext")
, **dict(取value), *dict(取key)解包的差別? *第一個(不定長度)參數:打包為tuple,**最後一個(不定長度)選擇性參數:打包為dict,解包時dict的key要與參數的名稱一樣,而且不可多,不可少,解包與打包運算子")
 ; from docx.document import Document as DocxDocument #類別,非function ; from docx.table import _Cell, Table #儲存格/表格 類別")
的函式.rfind() .replace() 切片與串接; 如何尋找直欄中,含有特定關鍵字的列數? pandas.Series.str.contains(“Hz”) ;如何將Series中的內容去掉首末的空格並小寫? pandas.Series .str.strip() .str.lower() #需要兩次.str")


近期留言