先安裝Live Server
(可以預覽HTML的VS Code套件):
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330190318_0_925655.jpg)
index.html:
<!DOCTYPE html>
<html>
<!-- 註解標籤 -->
<!-- head標籤: 用來放網頁相關設定 -->
<head>
<title>網頁標題</title>
<meta charset="utf-8"></meta> <!-- 完整寫法 -->
<meta charset="utf-8" /> <!-- 空標籤 -->
<style>
.my-style {
color: aquamarine;
background-color: brown;
font-size: 2em;
}
.my-style-part2 {
text-decoration: underline;
}
</style>
</head>
<!-- body標籤: 網頁內容 -->
<body>
<h1 style="color: #cdc776; font-size: 3em;">網站標題</h1>
<div class="my-style my-style-part2">Hello</div>
<div id="hello">你好</div>
<img src="https://res.klook.com/image/upload/q_85/c_fill,w_563/activities/aetyjas9q4xb8bnc94zr.jpg" />
<div>這裡示範其他<br />標籤的用法</div>
<a href="https://www.yahoo.com.tw" target="_blank">前往<br/>Yahoo</a>
<ul>
<li>項目1</li>
<li>項目2</li>
<li attr-data="1">項目3</li>
<li>項目4</li>
</ul>
</body>
</html>Live Server安裝正確的話,
VS Code 右下角會出現Go Live
點擊Go Live,
網站預覽:
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330192614_0_bd4373.jpg)
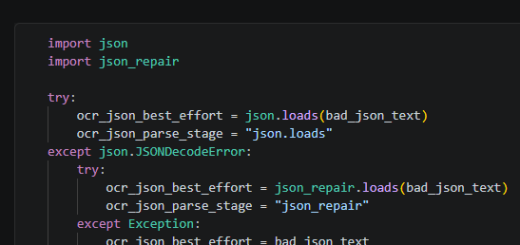
pip install bs4
from bs4 import BeautifulSoup
with open('index.html', 'r', encoding='utf-8') as file:
data = file.read() # 讀入全部檔案內容
soup = BeautifulSoup(data) # 解析網頁內容並回傳解析完成後的物件
# 將網頁內容格式化
print(soup.prettify())
print(soup.title)
輸出結果:
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330193149_0_09be1a.jpg)
取得指定的BeautifulSoup的標籤內容
(.string .text的差別):
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330193439_0_cae928.jpg)
index.html
( “前往Yahoo” 中間故意多一個換行標籤):
<a href="https://www.yahoo.com.tw" target="_blank">
前往<br/>Yahoo
</a>.string 返回None
.text 則忽略中間的標籤,返回文字
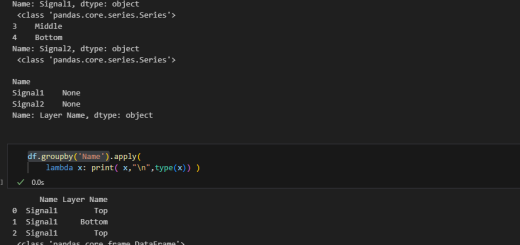
find()和find_all()方法
from bs4 import BeautifulSoup
with open('index.html', 'r', encoding='utf-8') as file:
data = file.read() # 讀入全部檔案內容
soup = BeautifulSoup(data,"lxml") # 解析網頁內容並回傳解析完成後的物件
# 將網頁內容格式化
# print(soup.prettify())
print(soup.title)
print(soup.html.body.a.string)
print(soup.html.body.a.text)
print(soup.body.ul.li) #只會找到第一個
#index.html:
"""
<body>
<h1 style="color: #cdc776; font-size: 3em;">網站標題</h1>
<div class="my-style my-style-part2">Hello</div>
<div id="hello">你好</div>
<img src="https://res.klook.com/image/upload/q_85/c_fill,w_563/activities/aetyjas9q4xb8bnc94zr.jpg" />
<div>這裡示範其他<br />標籤的用法</div>
<a href="https://www.yahoo.com.tw" target="_blank">前往<br/>Yahoo</a>
<ul>
<li>項目1</li>
<li>項目2</li>
<li attr-data="1">項目3</li>
<li>項目4</li>
</ul>
</body>
"""
# 以標籤名字來找
li = soup.find_all('li')
for i in li:
print(i.text)
# 以屬性來找標籤
li = soup.find(id='hello')
print(li.text)
# 以特殊屬性來找標籤
#class是python的關鍵字,
#HTML中的class,python中結尾要多_
li = soup.find(class_='my-style')
print(li.text)
# 以特殊屬性來找標籤
#attr-data 中的- ,python中也不合法,
#需使用字典的的型態,賦值給attrs
li = soup.find(attrs={'attr-data':'1'})
print(li.text)輸出:
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330194501_0_adcc03.jpg)
Jupyter輸出:
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330201841_0_27afe2.jpg)
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330201857_0_eb3dc2.jpg)
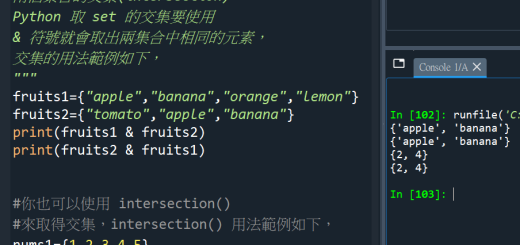
soup.select()
#不用為特殊屬性改屬性名
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330205330_0_57995c.jpg)
‘get()’方法來爬取屬性值
from bs4 import BeautifulSoup
import requests
with open('index.html', 'r', encoding='utf-8') as file:
data = file.read() # 讀入全部檔案內容
soup = BeautifulSoup(data,"lxml") # 解析網頁內容並回傳解析完成後的物件
# 將網頁內容格式化
# print(soup.prettify())
print(soup.title)
print(soup.html.body.a.string)
print(soup.html.body.a.text)
print(soup.body.ul.li)
# 以標籤名字來找
li = soup.find_all('li')
for i in li:
print(i.text)
# 以屬性來找標籤
li = soup.find(id='hello')
print(li.text)
# 以特殊屬性來找標籤
li = soup.find(class_='my-style')
print(li.text)
# 以特殊屬性來找標籤
li = soup.find(attrs={'attr-data':'1'})
print(li.text)
# 爬取屬性內容
img = soup.find_all('img')
cnt=0
for i in img:
src = i.get('src') # 取得src屬性內的網址
response = requests.get(src)
with open(f'img{cnt:2d}.jpg', 'wb') as file:
file.write(response.content)
cnt+=1下載下來一張圖片:
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330200302_0_216976.jpg)
selenium 使用WebElement.get_attribute()
獲取屬性值
不要跟BeautifulSoup的Tag.get()混淆了
推薦hahow線上學習python: https://igrape.net/30afN
 ; pickle.loads(binary_data)")

 ; 如果y是2D的 pandas.DataFrame ; 如何一次加入所有欄標籤當作圖例(legend)的labels? labels= y.columns.tolist() ; ax.legend(lines, labels)")
")


 ; 如何重置欄index? DataFrame的屬性與方法 .values ; .to_numpy()")
![「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260114094100_0_424ead.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇")
")

近期留言