next?
注意其參數為iterator
第一段:基本概念和語法
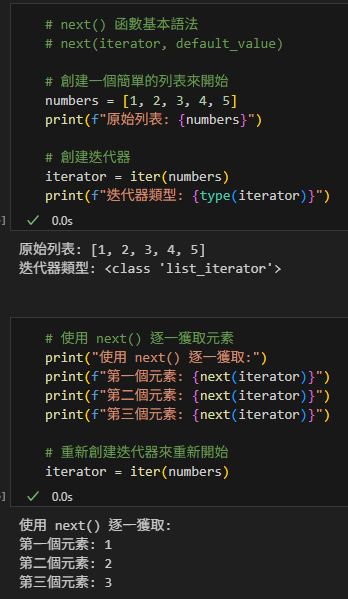
# next() 函數基本語法
# next(iterator, default_value)
# 創建一個簡單的列表來開始
numbers = [1, 2, 3, 4, 5]
print(f"原始列表: {numbers}")
# 創建迭代器
iterator = iter(numbers)
print(f"迭代器類型: {type(iterator)}")第二段:基本使用方式
# 使用 next() 逐一獲取元素
print("使用 next() 逐一獲取:")
print(f"第一個元素: {next(iterator)}")
print(f"第二個元素: {next(iterator)}")
print(f"第三個元素: {next(iterator)}")
# 重新創建迭代器來重新開始
iterator = iter(numbers)輸出:
第三段:預設值的重要性
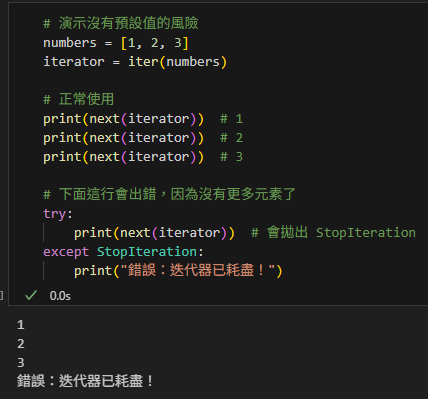
# 演示沒有預設值的風險
numbers = [1, 2, 3]
iterator = iter(numbers)
# 正常使用
print(next(iterator)) # 1
print(next(iterator)) # 2
print(next(iterator)) # 3
# 下面這行會出錯,因為沒有更多元素了
try:
print(next(iterator)) # 會拋出 StopIteration
except StopIteration:
print("錯誤:迭代器已耗盡!")輸出:
第四段:使用預設值避免錯誤
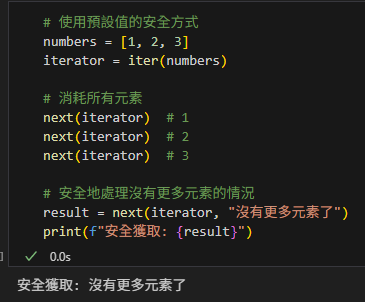
# 使用預設值的安全方式
numbers = [1, 2, 3]
iterator = iter(numbers)
# 消耗所有元素
next(iterator) # 1
next(iterator) # 2
next(iterator) # 3
# 安全地處理沒有更多元素的情況
result = next(iterator, "沒有更多元素了")
print(f"安全獲取: {result}")輸出:
第五段:結合生成器表達式 – 找第一個符合條件的元素
# 找到第一個偶數
numbers = [1, 3, 5, 8, 10, 12]
# 方法1:使用 next() + 生成器表達式
first_even = next((num for num in numbers if num % 2 == 0), None)
print(f"第一個偶數: {first_even}")
# 方法2:找第一個大於 5 的數
first_big = next((num for num in numbers if num > 5), None)
print(f"第一個大於5的數: {first_big}")
# 方法3:找第一個不存在的條件
first_negative = next((num for num in numbers if num < 0), "找不到負數")
print(f"第一個負數: {first_negative}")輸出:
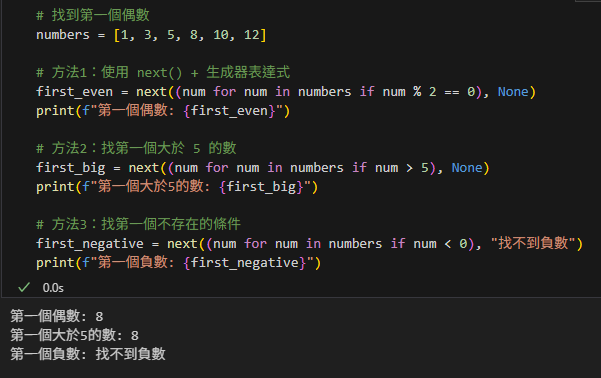
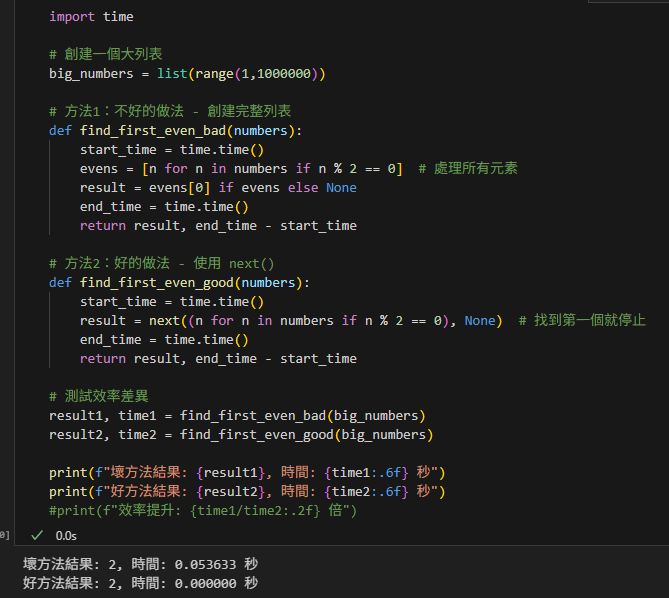
第六段:效率對比 – 為什麼要用 next()
import time
# 創建一個大列表
big_numbers = list(range(1,1000000))
# 方法1:不好的做法 - 創建完整列表
def find_first_even_bad(numbers):
start_time = time.time()
evens = [n for n in numbers if n % 2 == 0] # 處理所有元素
result = evens[0] if evens else None
end_time = time.time()
return result, end_time - start_time
# 方法2:好的做法 - 使用 next()
def find_first_even_good(numbers):
start_time = time.time()
result = next((n for n in numbers if n % 2 == 0), None) # 找到第一個就停止
end_time = time.time()
return result, end_time - start_time
# 測試效率差異
result1, time1 = find_first_even_bad(big_numbers)
result2, time2 = find_first_even_good(big_numbers)
print(f"壞方法結果: {result1}, 時間: {time1:.6f} 秒")
print(f"好方法結果: {result2}, 時間: {time2:.6f} 秒")
#print(f"效率提升: {time1/time2:.2f} 倍")輸出:
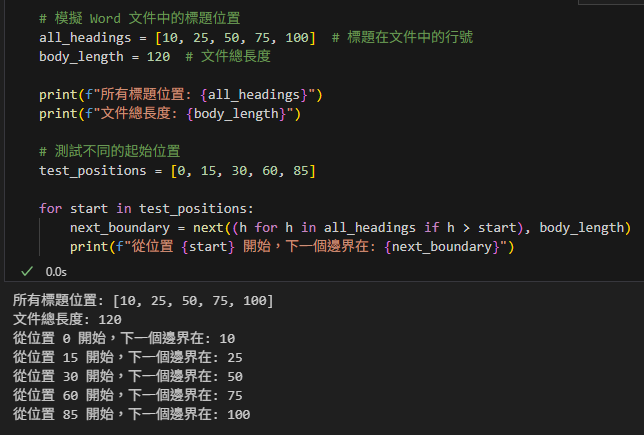
第七段:模擬文件標題
# %%
# 模擬 Word 文件中的標題位置
all_headings = [10, 25, 50, 75, 100] # 標題在文件中的行號
body_length = 120 # 文件總長度
print(f"所有標題位置: {all_headings}")
print(f"文件總長度: {body_length}")
# 測試不同的起始位置
test_positions = [0, 15, 30, 60, 85]
for start in test_positions:
next_boundary = next((h for h in all_headings if h > start), body_length)
print(f"從位置 {start} 開始,下一個邊界在: {next_boundary}")輸出:
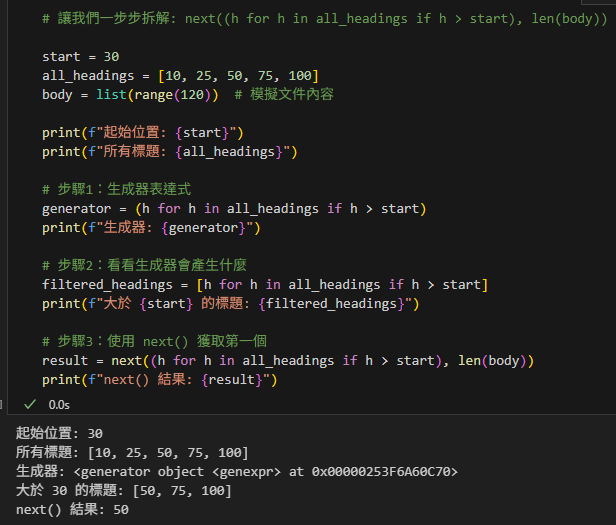
第八段:拆解文件標題例子
# 讓我們一步步拆解: next((h for h in all_headings if h > start), len(body))
start = 30
all_headings = [10, 25, 50, 75, 100]
body = list(range(120)) # 模擬文件內容
print(f"起始位置: {start}")
print(f"所有標題: {all_headings}")
# 步驟1:生成器表達式
generator = (h for h in all_headings if h > start)
print(f"生成器: {generator}")
# 步驟2:看看生成器會產生什麼
filtered_headings = [h for h in all_headings if h > start]
print(f"大於 {start} 的標題: {filtered_headings}")
# 步驟3:使用 next() 獲取第一個
result = next((h for h in all_headings if h > start), len(body))
print(f"next() 結果: {result}")輸出:
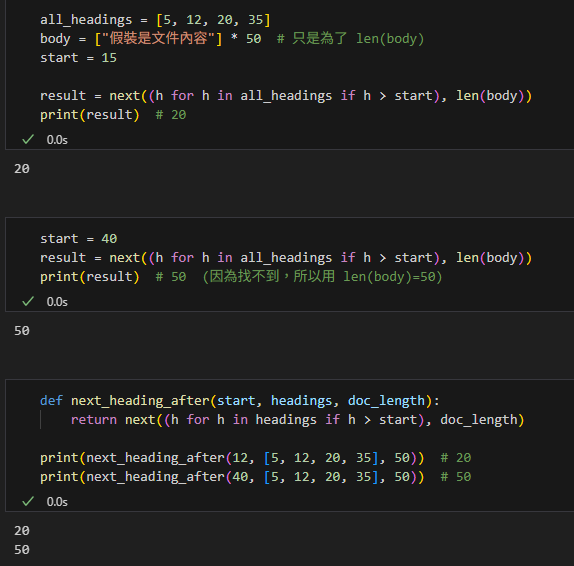
最小示範 1:直接執行
all_headings = [5, 12, 20, 35]
body = ["假裝是文件內容"] * 50 # 只是為了 len(body)
start = 15
result = next((h for h in all_headings if h > start), len(body))
print(result) # 20最小示範 2:換個 start
start = 40
result = next((h for h in all_headings if h > start), len(body))
print(result) # 50 (因為找不到,所以用 len(body)=50)最小示範 3:包成函數(實務最常用)
def next_heading_after(start, headings, doc_length):
return next((h for h in headings if h > start), doc_length)
print(next_heading_after(12, [5, 12, 20, 35], 50)) # 20
print(next_heading_after(40, [5, 12, 20, 35], 50)) # 50輸出:
對照:如果不用 next(較囉嗦)
def manual_version(start, headings, doc_length):
for h in headings:
if h > start:
return h
return doc_length記住一句話:這種寫法就是「找第一個符合條件的值,沒有就用備胎」。
常見錯誤和最佳實踐
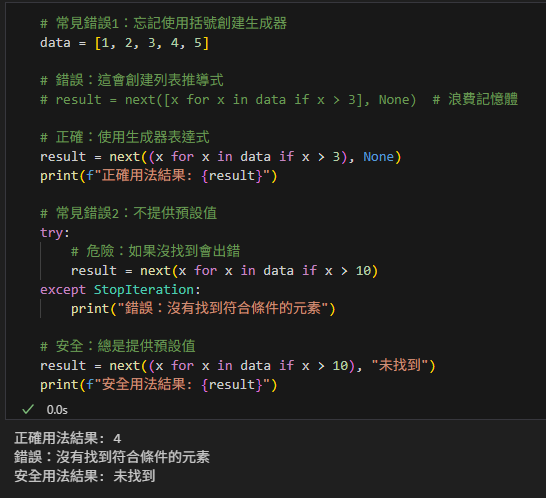
# 常見錯誤1:忘記使用括號創建生成器
data = [1, 2, 3, 4, 5]
# 錯誤:這會創建列表推導式
# result = next([x for x in data if x > 3], None) # 浪費記憶體
# 正確:使用生成器表達式
result = next((x for x in data if x > 3), None)
print(f"正確用法結果: {result}")
# 常見錯誤2:不提供預設值
try:
# 危險:如果沒找到會出錯
result = next(x for x in data if x > 10)
except StopIteration:
print("錯誤:沒有找到符合條件的元素")
# 安全:總是提供預設值
result = next((x for x in data if x > 10), "未找到")
print(f"安全用法結果: {result}")輸出:
綜合練習
# %%
# 練習:使用 next() 解決實際問題
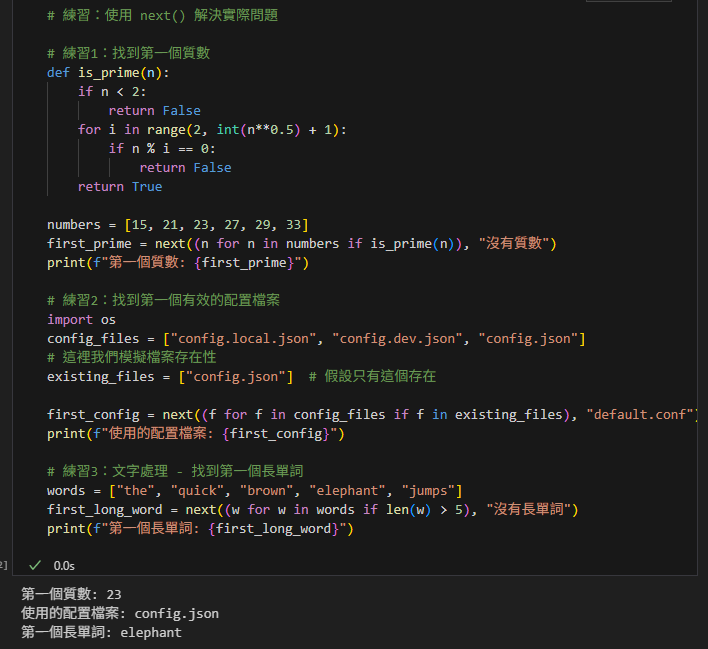
# 練習1:找到第一個質數
def is_prime(n):
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
numbers = [15, 21, 23, 27, 29, 33]
first_prime = next((n for n in numbers if is_prime(n)), "沒有質數")
print(f"第一個質數: {first_prime}")
# 練習2:找到第一個有效的配置檔案
import os
config_files = ["config.local.json", "config.dev.json", "config.json"]
# 這裡我們模擬檔案存在性
existing_files = ["config.json"] # 假設只有這個存在
first_config = next((f for f in config_files if f in existing_files), "default.conf")
print(f"使用的配置檔案: {first_config}")
# 練習3:文字處理 - 找到第一個長單詞
words = ["the", "quick", "brown", "elephant", "jumps"]
first_long_word = next((w for w in words if len(w) > 5), "沒有長單詞")
print(f"第一個長單詞: {first_long_word}")輸出:
推薦hahow線上學習python: https://igrape.net/30afN


 增加新的一欄? model = tensorflow.keras.models.Sequential()")
")
, loc=’upper left’) ; plt.tight_layout() ; 如何防止儲存的檔案圖例被裁切? plt.savefig(‘example.png’, dpi=300, format=’png’, bbox_extra_artists=(lg,), bbox_inches=’tight’)")

 與select() ; from bs4 import BeautifulSoup ; .string .text .get_text() 獲取文字內容")
![Word短篇文件編輯,TQC考題110:重點摘要與評量, \[(*)\] 萬用字元,格式>醒目提示*2次=非醒目提示](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/03/20220322172253_75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Word短篇文件編輯,TQC考題110:重點摘要與評量, \[(*)\] 萬用字元,格式>醒目提示*2次=非醒目提示")
![Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]")


近期留言