前言
使用 OpenAI API 轉自然語言雖然方便,但每次都要花錢。
現在你可以用 Ollama 在本地端免費執行
Qwen、Yi、Deepseek 等強大中文 LLM,
自動把結構化 JSON 資料轉成容易閱讀的中文摘要!
一、環境準備
1. 安裝並啟動 Ollama
- 下載安裝:Ollama 官網
- 啟動 Ollama 服務(cmd)
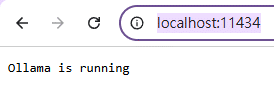
ollama serve運作正常的話,
Chrome連線http://localhost:11434/
要顯示Ollama is running
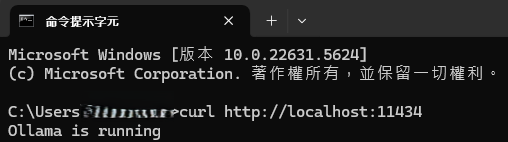
或者在cmd中輸入:
curl http://localhost:11434看到像這樣的回應:
下載支援中文的模型(任選)
ollama pull qwen:7b
ollama pull yi:9b
ollama pull deepseek-llm:7b
ollama pull deepseek-r1:8b把pull改成 run 可以在terminal與LLM對話
/bye 離開對話模式
ollama list 可以顯示已經下載的模型
Qwen(qwen:7b)
阿里巴巴開發,中文理解力強,摘要/轉寫表現出色。
Yi(yi:9b)
百川智能開發,中文和英文都很穩定,適合多領域應用。
Deepseek(deepseek-llm:7b)
開源大模型,中文能力佳且推理能力不俗。
更多模型可查詢 Ollama 官方模型庫。

二、Python 程式簡介
這份程式會「逐筆」將 JSON 中每一筆資料,
透過本地 LLM 轉成自然語言描述,
過程中即時存檔,避免中途斷掉資料遺失,
程式執行期間, ollama serve 的terminal不能關掉,
要先pip install ollama。
三、簡化範例程式
import os
import json
from ollama import Client
#要先 pip install ollama
# 設定資料路徑
json_path = "你的資料夾/fixtureRepair.json"
save_dir = "你的資料夾/Neutral Lang"
os.makedirs(save_dir, exist_ok=True)
# 選擇模型:qwen:7b、yi:9b、deepseek-llm:7b
model_name = "qwen:7b"
save_path = os.path.join(save_dir,
f"nl_by_{model_name.replace(':','-')}.json")
tmp_path = os.path.join(save_dir,
f"nl_tmp_by_{model_name.replace(':','-')}.json")
# 讀取 JSON 原始資料
with open(json_path, "r", encoding="utf-8") as f:
records = json.load(f)
# 連接本地 Ollama
client = Client(host="http://localhost:11434")
# few-shot 範例 prompt
prompt = """
請將下列JSON格式的維修紀錄,
轉換成精簡易懂的中文自然語言描述,
若某些欄位為空,則省略該資訊,不要胡亂補充。
範例:
{
"Family_家族": "['ASTORIA']",
"sn_治具序号": "015ATR30",
"faultType_故障分类": "UUT IP FAIL",
"defectSymptom_故障现象": "無法正常開機",
"rootCause_故障原因": "Agora 無法正常讀取",
"correctiveAction_解决方案": "更換agor轉板*1",
"startTime_开始时间": "2025/03/13 09:09:02",
"endTime_完成时间": "2025/03/13 10:04:06"
}
輸出:2025年3月13日09:09,
ASTORIA家族的治具(序號015ATR30)發生UUT IP FAIL,
現象為無法正常開機,原因是Agora無法正常讀取,
處理方式為更換Agora轉板,於10:04修復完成。
請處理下列資料:
"""
# 逐筆處理
nl_records = []
for i, rec in enumerate(records):
user_prompt = prompt + json.dumps(rec,
ensure_ascii=False)
response = client.chat(
model=model_name,
messages=[{"role": "user",
"content": user_prompt}]
)
content = response['message']['content']
rec_nl = rec.copy()
rec_nl["自然語言描述"] = content
nl_records.append(rec_nl)
# 每筆即時存檔,避免資料遺失
with open(tmp_path, "w", encoding="utf-8") as f:
json.dump(nl_records, f,
ensure_ascii=False, indent=2)
print(f"第{i+1}筆完成:{content}")
# 全部完成後存正檔
os.rename(tmp_path, save_path)
print("全部完成!已存檔:", save_path)client.chat()chat() 與 generate() 差異與選用時機
1. chat() 方法
- 用途:模擬多輪對話(如聊天機器人),可以一次傳入多個角色(user、assistant)訊息,維持上下文脈絡。
- 適合情境:需要多輪互動、上下文記憶、或要自訂 system prompt。
- 訊息格式:
messages=[{"role": "user", "content": "..."}],可以累積對話歷史。
2. generate() 方法
- 用途:單次問題單次回答,適合簡單 Prompt→回應的場景。
- 適合情境:只要發送一個 prompt、取得一個 output,不需要維持對話狀態。
- 訊息格式:直接用
prompt="...",簡單直觀。
輸出格式差異
chat()回傳物件要抓response['message']['content']generate()回傳物件要抓response['response']
範例比較
多輪對話(chat):
messages = [
{"role": "system", "content": "你是一位專業助理"},
{"role": "user", "content": "幫我介紹一下Python。"},
{"role": "assistant", "content": "Python是一種簡單易用的程式語言。"},
{"role": "user", "content": "它適合初學者嗎?"}
] #範例程式messages:List[dict] 長度僅1 ,效果同generate
response = client.chat(
model="qwen:7b",
messages=messages
)
print(response['message']['content'])適合需要上下文的應用
單輪對話(generate):
response = client.generate(
model="qwen:7b",
prompt="請用一句話介紹Python。"
)
print(response['response'])適合只要問一題就拿答案
from ollama import Client
上述是使用 ollama 客戶端庫
第二個方法使用 HTTP 請求
(requests 庫向本地運行的 Ollama API 發送請求)
import requests # 引入 requests 模組,這是 Python 中最常用的 HTTP 用戶端函式庫
import json # 引入 json 模組 (為了演示等效寫法,實際上如果只用 response.json() 可以不用 import 這個)
# 1. 定義 API 端點 (Endpoint)
# Ollama 預設在本地端的 11434 埠號執行。
# /api/generate 是用來產生單次回應的 API 路徑。
url = "http://localhost:11434/api/generate"
# 2. 準備請求資料 (Payload)
# 這是我們要傳送給 Ollama 的指令,必須是 Python 字典 (dict) 格式。
payload = {
# "model": 指定要使用的模型名稱。
# 請確保您已經在終端機執行過 `ollama pull llama3` 下載此模型。
"model": "llama3",
# "prompt": 提示詞,也就是您要問 AI 的問題或指令。
"prompt": "用中文簡單介紹Ollama的用途。",
# "stream": 串流模式設定
# False: (推薦用於簡單測試) 等待 AI 生成完「所有」內容後,才一次性回傳完整的 JSON。
# True: (推薦用於聊天機器人) AI 每生成一個字 (Token) 就回傳一次,可以做出打字機效果。
"stream": False
}
# 3. 發送 HTTP POST 請求
# requests.post() 會幫我們把 payload 字典自動轉換成 JSON 格式字串 (因為用了 json=payload 參數)。
# 這行程式碼會「卡住 (Block)」,直到 Ollama 生成完畢並回傳結果。
print("正在等待 Ollama 回應...")
response = requests.post(url, json=payload)
# 4. 處理回應結果
# response.json():
# 這是一個 requests 模組提供的捷徑 (Shortcut) 方法。
# 它內部的運作邏輯「完全等效」於執行以下兩步:
# 1. 讀取 raw string: raw_str = response.text
# 2. 解析 JSON: data_dict = json.loads(raw_str)
#
# 所以寫 response.json() 就等於寫 json.loads(response.text),
# 只是 requests 幫您少寫了一行 import json 和解析的程式碼。
#
# ["response"]: 是從解析後的字典中,取出 AI 真正回答的文字內容。
print("-" * 30)
print(response.json()["response"])
print("-" * 30)小結

如果只是單題單答,兩種方法都可以用,結果一樣!
四、重點說明
- 逐筆處理+即時存檔:遇到中斷也能保留處理進度。
- 模型切換超簡單:只要改
model_name,就能比對不同模型的表現。 - prompt 內建 few-shot 範例:讓模型學會你想要的描述格式。
五、結論
只要安裝好 Ollama 跟中文 LLM,
就能本地高效安全地批次將結構化資料自動「翻譯」成自然語言。
不用花 OpenAI API 錢,也不用擔心資料外流!
缺點則是普通電腦執行速度極慢,
不適合數千筆資料的轉換
推薦hahow線上學習python: https://igrape.net/30afN
 ; pickle.loads(binary_data)")

![Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221112184006_50.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str]")
 ? 如何搭配portable Chrome? from selenium.webdriver.common.by import By ; from selenium.webdriver.chrome.options import Options ; option = Options() ; option.binary_location = chrome_portable_path")
 API? MIME (Multipurpose Internet Mail Extensions)")
; from bs4 import BeautifulSoup")
獲取index? from openpyxl.utils import column_index_from_string, get_column_letter ; 從DataFrame的column name獲取index: pandas.DataFrame.columns .get_loc( “column_name” )")

![Python如何讀取*.jsonl (JSON Lines)? 讀取為List[dict]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/10/20231024225613_30.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何讀取*.jsonl (JSON Lines)? 讀取為List[dict]")
![Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221112184006_50-520x245.png)

近期留言