sample.docx 內容僅有
一段文字跟一張圖片:
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251105144007_0_e4b688.png)
sample.zip為sample.docx修改副檔名為.zip
其中的document.xml 內容:
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251119141811_0_6e9b5d.png)
部分XML內容:
<a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
<a:graphicData uri="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:pic xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:nvPicPr>
<pic:cNvPr id="1" name="圖片 1"/>
<pic:cNvPicPr/>
</pic:nvPicPr>
<pic:blipFill>
<a:blip r:embed="rId4" cstate="print">a:blip r:embed=”rId4″ cstate=”print”
# a:blip這個元素,有一個r:embed屬性,其屬性值為 “rId4”
# a:blip 有一個祖先元素為 w:drawing
# w:drawing的父元素為w:r, 但可以使用.getparent()自動獲取
# w:r .remove() 清理掉w:drawing以下的所有子孫節點
# 可以修訂document.xml 內容 ,但僅視覺效果,尚未清理實體資源
# 內容變少,但容量卻幾乎沒有減少
# 務必記住這個XML的結構
# 留意其祖先:
<a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">有一個屬性xmlns:a (#xml name space)
其屬性值為
“http://schemas.openxmlformats.org/drawingml/2006/main”
這代表a前綴的命名空間為
“http://schemas.openxmlformats.org/drawingml/2006/main”
勿混淆a:graphicData:
<a:graphicData uri="http://schemas.openxmlformats.org/drawingml/2006/picture">這裡的 uri 並不是 XML 命名空間的宣告 (xmlns)。
不能看 a:graphicData 的 uri 屬性來決定 a: 的命名空間,原因有二:
- 那個
uri是一個普通屬性值,不是xmlns宣告。 a:的定義是由上層的xmlns:a決定的,
它始終指向 DrawingML Main (.../2006/main)。
document.xml.rels:
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251125093308_0_78b969.png)
用 VS Code 開啟該檔案。
按下快捷鍵 Shift + Alt + F。
或者在編輯區按右鍵,
選擇「格式化文件 (Format Document)」。
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251125093846_0_abc3b6.png)
元素 Relationships xmlns=”http://schemas.openxmlformats.org/package/2006/relationships”
有一個子元素:
Id=”rId4″ ;
Target=”media/image1.jpeg”
D:\Temp\sample.zip\word\media
image1.jpeg 容量為1009KB
主要目標就是要移除這個檔案,
才能對docx瘦身
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251125094254_0_8e3f03.png)
從document.xml 知道
a:blip r:embed=“rId4”
再從document.xml.rels 知道
Id=”rId4″ ;
Target=”media/image1.jpeg”
從Target=”media/image1.jpeg”
可以拼接出圖檔路徑
word/media/image1.jpeg
重建zip (docx)時,
遇到該路徑,跳過複製
目標
- 從 .docx(或同內容的 .zip)中找出文件內嵌圖片的 rId,
映射到實際檔案路徑,並讀出圖片位元組。 - 對比兩種做法:
- python-docx 的 qn + ElementTree 的 find/findall
- XPath(含前綴版與無前綴 fallback)
可直接貼進 Jupyter 執行。程式避免 Path.resolve 等易踩雷 API。
準備
- 檔案:sample.docx 或 sample.zip(二擇一;.docx 本質也是 ZIP 容器)
- 套件:lxml、python-docx
- 在 Jupyter 可先執行:%pip install lxml python-docx
教學程式(可直接複製執行)
# 若環境未安裝,解除註解以下一行:
# %pip install lxml python-docx
import zipfile
from pathlib import PurePosixPath
# POSIX = Portable Operating System Interface
# 主要針對類 Unix 系統的介面與行為做規範,
# 讓程式在不同 Unix/Unix-like 系統間更容易移植。
from lxml import etree
from docx.oxml.ns import qn
# python-docx 內建的前綴→URI 轉換
#========================
# 1) 指定你的文件
#========================
# 填入 sample.docx 或 sample.zip 皆可(兩者都是 ZIP 容器)
DOCX_OR_ZIP = r"D:\Temp\sample.docx"
assert zipfile.is_zipfile(DOCX_OR_ZIP), "請提供 .docx 或 .zip(OOXML ZIP 容器)路徑"
#========================
# 2) 安全的 ZIP 內相對路徑拼接(不使用 resolve)
#========================
def join_zip_path(base_dir: str, rel_path: str) -> str | None:
"""
以 POSIX 規則將 base_dir 與 rel_path 串接並手動規範化 . 與 ..
回傳 ZipFile.namelist() 可用之相對路徑(不以 / 開頭)
base='word',rel='media/image1.png' → 'word/media/image1.png'
base='word',rel='./media/image1.png' → 'word/media/image1.png'(. 會被忽略)
base='word',rel='../media/image2.jpg' → 'media/image2.jpg'(往上跳一層)
base='word/charts',rel='../media/image3.png' → 'word/media/image3.png'
"""
if not rel_path:
return None
base = list(PurePosixPath(base_dir).parts)
rel = list(PurePosixPath(rel_path).parts)
parts = base[:]
for seg in rel:
if not seg or seg == ".":
continue
if seg == "..":
if parts:
parts.pop()
continue
parts.append(seg)
return "/".join(parts)
#========================
# 3) 讀取核心 XML:word/document.xml 與 word/_rels/document.xml.rels
#========================
with zipfile.ZipFile(DOCX_OR_ZIP) as z:
doc_xml = z.read("word/document.xml") #bytes
rels_xml = z.read("word/_rels/document.xml.rels") #bytes
parser = etree.XMLParser(remove_blank_text=True)
"""
#remove_blank_text=True
處理 Word/Excel XML 時,結構更乾淨,
使用 getchildren() 或索引存取子元素時,
不會意外抓到「換行符號」當作一個元素。
若沒有此設定
會導致解析出來的樹狀結構變得很亂,
充滿了無意義的文字節點。
給程式讀:不需要漂亮格式,越緊湊越好。
給人讀:如果真的要 Debug,用 VS Code 或瀏覽器
打開 XML 自動格式化一下就好,
不需要在 Python 處理階段浪費資源去排版。
"""
doc_root = etree.fromstring(doc_xml, parser=parser)
rels_root = etree.fromstring(rels_xml, parser=parser)
# lxml.etree._Element
"""
parser = etree.XMLParser(remove_blank_text=True)
doc_root = etree.XML(doc_xml, parser=parser)
etree.HTML(html, parser = etree.HTMLParser())
用來解析網頁
容錯能力 (寬容度)
etree.XML (嚴格): 如果標籤沒閉合(例如 <br> 沒寫成 <br/>),
或者語法有錯,程式會直接報錯 (Error)。
etree.HTML (寬容): 它是設計來解析網路上亂七八糟的網頁原始碼的。
遇到沒閉合的標籤或錯誤語法,它會嘗試修復而不是報錯。
"""
#========================
# 4) 方法一:qn + find/findall
# - 不需自行維護 namespaces 字典 {前綴:命名空間URI}
# - 適合抓常見節點與屬性
#========================
def get_rids_with_qn(root_el):
rids = []
# a:blip 的 r:embed
for blip in root_el.findall(f".//{qn('a:blip')}"):
"""
# qn('a:blip')
# '{http://schemas.openxmlformats.org/drawingml/2006/main}blip'
# {命名空間URI}local_name = tag = 展開的QName
# QName 是一個概念:合格名稱,既可以是帶前綴的形式(a:blip),
也可以是展開形式({URI}blip)。
通俗說法: 元素名稱 (Element Name / Tag Name)
# blip : lxml.etree._Element
# qn("r:embed")
# '{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed'
"""
rid = blip.get( qn("r:embed") ) #'rId4'
if rid:
rids.append(rid)
"""
#第一次搜尋: root_el.findall(f".//{qn('a:blip')}")
.// 代表搜尋 root_el 下所有層級的子節點。
這意味著它會找出這棵樹裡所有的 <a:blip>,無論它的父節點是誰。
第二個 for 迴圈是完全多餘的
"""
# 某些文件圖片在 pic:pic 節點內
# 在 root_el 這棵子樹裡搜尋所有層級的節點:
# - 先找出所有 <pic:pic>(不限深度,因為使用 .//)
# - 再在每個 <pic:pic> 之下,繼續找其任意深度的 <a:blip>
# qn('ns:local_name') 會把前綴名轉成 Clark notation
# "{namespace-uri}local_name",供 ElementTree 正確比對
for blip in root_el.findall(f".//{qn('pic:pic')}//{qn('a:blip')}"):
# qn('pic:pic')
# '{http://schemas.openxmlformats.org/drawingml/2006/picture}pic'
rid = blip.get(qn("r:embed")) #'rId4'
if rid:
rids.append(rid)
return sorted(set(rids))
rids_qn = get_rids_with_qn(doc_root)
print("A) qn + find/findall rId:", rids_qn)
# A) qn + find/findall rId: ['rId4']
#========================
# 5) 方法二:XPath
# 5-1) 前綴版:可讀性好,但需 namespaces 映射
#========================
NS = {
"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main",
"a": "http://schemas.openxmlformats.org/drawingml/2006/main",
"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships",
"pic": "http://schemas.openxmlformats.org/drawingml/2006/picture",
"wp": "http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing",
"a14": "http://schemas.microsoft.com/office/drawing/2010/main",
"w14": "http://schemas.microsoft.com/office/word/2010/wordml",
} #Dict[前綴,命名空間]
def get_rids_with_xpath_prefix(root_el):
rids = []
rids += root_el.xpath("//a:blip/@r:embed", namespaces=NS)
#要搜尋到: a:blip r:embed="rId4" cstate="print"
#取出 屬性名r:embed 的 屬性值"rId4"
#List[屬性值] # ['rId4']
rids += root_el.xpath("//pic:pic//a:blip/@r:embed", namespaces=NS)
return sorted(set(rids))
"""
在 XPath 裡,/@r:embed 的「/」是必要語法的一部分,
表示「從前一個步驟選到的節點,取其屬性 r:embed 的值」。不能用空格取代。
寫法 //a:blip/@r:embed 是正確的:
它會在文件中所有 a:blip 元素上,
選取屬性 r:embed 的值(例如 "rId4")。
若某個 a:blip 沒有 r:embed,該元素就不會產生結果。
如果還想同時篩選出具有特定屬性或屬性值的 a:blip,可以在元素步驟加條件:
只要有 r:embed 的 a:blip: //a:blip[@r:embed] #取到的是元素
root_el.xpath("//a:blip[@r:embed]", namespaces=NS):
List[ lxml.etree._Element ]
同時有 cstate="print"://a:blip[@r:embed][@cstate='print']
#List[ lxml.etree._Element ]
若只想拿到元素節點(而不是屬性值),用上面兩個。
若要直接拿 rId 值,用 //a:blip[@cstate='print']/@r:embed。
//a:blip/@r:embed → 回傳每個 a:blip 的 r:embed 屬性值(如 "rId4")
//a:blip[@r:embed] → 回傳符合條件的 a:blip 元素節點本身(僅篩選出有該屬性的元素)
//a:blip[@cstate='print']/@r:embed →
先篩選 cstate='print' 的 a:blip,再取其 r:embed 屬性值
"""
rids_xpath_prefix = get_rids_with_xpath_prefix(doc_root)
print("B1) XPath(前綴)rId:", rids_xpath_prefix)
# 5-2) 無前綴 fallback:不依賴文件裡的前綴
A = NS["a"]; R = NS["r"]
#A #'http://schemas.openxmlformats.org/drawingml/2006/main'
#R #'http://schemas.openxmlformats.org/officeDocument/2006/relationships'
def get_rids_with_xpath_noprefix(root_el):
# 取得所有符合條件的屬性值,整理為去重後的排序列表
return sorted(set(root_el.xpath(
"//*[local-name()='blip' and namespace-uri()=$A]"
"/@*[local-name()='embed' and namespace-uri()=$R]",
A=A, R=R
)))
rids_xpath_noprefix = get_rids_with_xpath_noprefix(doc_root)
print("B2) XPath(無前綴)rId:", rids_xpath_noprefix)
#========================
# 6) 合併 rId(去重)
#========================
rids = sorted(set(rids_qn) | set(rids_xpath_prefix) | set(rids_xpath_noprefix))
print("合併 rId:", rids)
#========================
# 7) 解析 _rels:rId -> Target
# - .rels 使用 package relationships 命名空間
# - 三種寫法擇一,這裡採用前綴版(最直覺)
#========================
PKG_REL = "http://schemas.openxmlformats.org/package/2006/relationships"
NS_RELS = {"rel": PKG_REL}
"""
.rels 文件根元素是
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
無前綴,需要自定義前綴,命名空間則是
"http://schemas.openxmlformats.org/package/2006/relationships"
其中一個子元素(期待命中的目標):
<Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image" Target="media/image1.jpeg"/>
有 Id, Target 屬性
"""
rid_to_target = {
el.get("Id"): el.get("Target")
for el in rels_root.xpath("//rel:Relationship", namespaces=NS_RELS)
}
""" #rid_to_target
{'rId3': 'webSettings.xml',
'rId2': 'settings.xml',
'rId1': 'styles.xml',
'rId6': 'theme/theme1.xml',
'rId5': 'fontTable.xml',
'rId4': 'media/image1.jpeg'}
"""
targets = [rid_to_target.get(r) for r in rids]
print("rId → Target:", targets)
# ['media/image1.jpeg']
#========================
# 8) 轉成 ZIP 內實際路徑(以 word/ 為基準)並讀圖片 bytes
#========================
zip_paths = [join_zip_path("word", t) if t else None for t in targets]
#img_pathes 會比較貼切
print("ZIP 內圖片路徑:", zip_paths)
# ['word/media/image1.jpeg']
images = {}
with zipfile.ZipFile(DOCX_OR_ZIP) as z:
names = set(z.namelist())
for p in zip_paths:
if p and p in names:
images[p] = z.read(p)
print(f"讀到 {len(images)} 張圖片。前幾個鍵:", list(images.keys())[:3])
# 如需落地存檔,可解除以下範例:
# for i, (p, data) in enumerate(images.items(), 1):
# out = f"img_{i}{PurePosixPath(p).suffix}"
# with open(out, "wb") as f:
# f.write(data)
# print("saved:", out)XPath 語法說明:
root_el.xpath(
"//*[local-name()='blip' and namespace-uri()=$A]"
"/@*[local-name()='embed' and namespace-uri()=$R]",
A=A, R=R
)
# XPath 語法說明:
# //* → 遍歷整個文件中所有節點(“*”代表任意元素)
# [local-name()='blip' → 篩選本地名稱(忽略命名空間前綴)為 blip 的元素
# and namespace-uri()=$A] → 並且該元素的命名空間 URI 等於參數 $A
# /@* → 從這些元素中取出所有屬性(@* 代表任意屬性)
# [local-name()='embed' → 篩選本地名稱為 embed 的屬性
# and namespace-uri()=$R] → 並且屬性的命名空間 URI 等於參數 $R
//* 是「從文件根節點開始,選取整個文件中所有元素(任意層級、任意名稱)」。
因為開頭有 /,它會先回到根節點,再展開 descendant-or-self 軸。
.//* 則是「從當前節點開始,選取該節點及其後代中的所有元素」。
只有當上下文節點本來就在根節點時,
.//* 和 //* 才會選到同樣的節點;
若上下文不是根節點,兩者就不同。
語法結構:動作 vs. 目標
XPath 的邏輯可以拆解為「路徑(怎麼走)」和「節點測試(找什麼)」。
// (Double Slash):這是一個**軸(Axis)**或路徑運算符。
它的意思是「從當前位置向下遞歸查找所有後代(Descendants)」。它只代表「方向」。
* (Asterisk):這是一個節點測試(Node Test)。
它的意思是「任何元素(Element)」。它代表「目標」。
結論:
如果您只寫 //,就像是跟程式說「去幫我把所有的......找出來」,
但是沒說要找什麼。解析器(如 lxml)會報 Syntax Error(語法錯誤)。
在 XPath 中,/ 是根節點,// 是後代。
通常我們寫 //*(連在一起)。
意思是:從根節點開始 (/),遞歸查找 (/) 所有元素 (*)。
如果您寫 /(只有一個斜線):這代表「文件本身(Document Root)」,
它不是一個列表,而是整個文件的起點物件。輸出:
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251119130848_0_3fbf6b.png)
你會學到什麼
- qn 是什麼、為什麼好用
- qn 由 python-docx 提供(docx.oxml.ns.qn),
把 “前綴:名稱(local name)” 轉成
lxml 需要的擴展 QName(tag) “{uri}local”。 - 好處:不用自己維護 namespaces 字典;
docx 常用前綴(w, a, r, pic, wp …)已內建。 - 適用:Element/屬性存取(find/findall/get/set)。
不適用:XPath 字串內直接用 Clark notation。
- qn 由 python-docx 提供(docx.oxml.ns.qn),
- find/findall 的優勢與侷限
- 優勢:寫法直覺、學習成本低;搭配 qn 幾乎不會被前綴差異卡住。
- 侷限:只能走樹狀路徑,複雜條件(AND/OR、位置過濾、聚合)表達力不足。
- XPath 的兩種寫法與取捨
- 前綴版:可讀性最好,像 //a:blip/@r:embed;
但必須提供 namespaces=…,且文件內前綴要吻合。 - 無前綴版:用 local-name() + namespace-uri() 避免前綴依賴,較冗長,勝在穩定。
- 前綴版:可讀性最好,像 //a:blip/@r:embed;
- .rels 檔的命名空間
- document.xml.rels 使用 package relationships 命名空間(http://schemas.openxmlformats.org/package/2006/relationships)。
- 在 XPath 中必須用前綴或 local-name()/namespace-uri();
不能把 {uri}Relationship 放進 XPath(會報錯)。
- ZIP 內路徑處理的坑
- OOXML 是 ZIP 容器,內部路徑一律使用 POSIX「/」。
- 用 PurePosixPath 規範化相對路徑(處理 ..、.)避免平台差異;
不要用 OS 的實體路徑 API 來拼 ZIP 內部路徑。
- 圖片抽取流程的重要關聯
- document.xml 中的 a:blip/@r:embed 給出 rId。
- document.xml.rels 將 rId 對應到 Target 路徑(例如 media/image1.png)。
- 以 word/ 為基準拼成 ZIP 內實際路徑,最後從 ZIP 讀出位元組。
在 XML 領域,「tag」通常指帶有前綴的名稱或裸名稱,例如 a:blip 或 blip;
而 “{namespace-uri}local-name” 是一種序列化表示法(Clark notation),
用來在程式庫中唯一定位元素或屬性,不是人讀的「標籤字面」。
說清楚幾個名詞
- qualified name(QName,合格名稱):prefix:local-name,例如 a:blip、r:embed。
- local name:不含前綴的實名,例如 blip、embed。
- namespace URI:例如 http://schemas.openxmlformats.org/drawingml/2006/main。
- Clark notation:”{namespace-uri}local-name” 的字串形式,
用於 ElementTree 等庫做匹配,例如 “{…/drawingml/2006/main}blip”。
在 lxml/ElementTree 裡
- 元素的 .tag 屬性值就是 Clark notation(若有命名空間):elem.tag == “{ns}local”.
- 沒有命名空間時,.tag 直接是 “local”。
- qn(“a:blip”) 會回傳 “{ns-of-a}blip”,讓你在 XPath 或 findall 中精確匹配。
所以:
- 人類閱讀或原始 XML 內看到的 <a:blip> 叫「tag(QName)」。
- 在 ElementTree 內部,對應的 .tag 字串是 Clark notation;
它也是一個「tag 字串表示」,但重點在唯一性,而非人類可讀的標籤寫法。
qn(‘a:blip’) ; qn(“r:embed”) ; qn(‘pic:pic’)
在 Python ElementTree / lxml 的程式開發語境下,它就是「tag」。
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251119143447_0_27a8b8.png)
for blip in root_el.findall(f".//{qn('a:blip')}"):
print( etree.tostring(blip, encoding="unicode",
pretty_print=True) )
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251120112312_0_9dcd49.png)
print( etree.tostring(rels_root, encoding=”unicode” , pretty_print=True) )
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251119150448_0_202b69.png)
get_rids_with_qn()
最終可以獲得[‘rId4’]
再看rels_root 的內容
‘rId4’ 對應的Target=”media/image1.jpeg”
若僅修訂 document.xml 內容,讓圖片消失
檔案幾乎不會縮小
要刪除這一張圖,才能對docx瘦身
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/>
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/>
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>
<Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
<Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
<Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image" Target="media/image1.jpeg"/>
</Relationships>實務建議
- 初學與日常維護
- 先選 qn + find/findall:簡單、穩、減少命名空間錯誤;對抓 blip 與 rId 已足夠。
- 只在需要複雜條件(例如依屬性篩選、一次抓多型資料、跨節點關係)時,才切到 XPath。
- 撰寫 XPath 的策略
- 優先用前綴版(可讀性好),並集中定義 namespaces 字典。
- 需要兼容「前綴不一致或缺失」的文件時,加上無前綴 fallback。兩段都跑、合併去重,實務最穩。
- 針對 .rels
- 一律用前綴或無前綴 XPath;或改用 Element.findall 的 Clark notation({uri}tag)但那不是 XPath 字串。
- 路徑與平台
- 只要處理 ZIP/OOXML 內部路徑,一律用 POSIX 風格與 PurePosixPath;不要把這些路徑丟給 Windows 路徑 API。
- 可靠性與除錯
- 每步都 print 出中間結果(rIds、targets、zip_paths、已讀圖片數量),可快速定位問題點。
- 用 set 去重,避免重複 rId 或重複圖片。
- 延伸
- 若需處理圖表、外部連結、嵌入物件,流程相同:從主文檔取得 rId → 讀對應 .rels → 拼路徑 → 讀取資源。
- 可將三種取得法封裝為函式與單元測試,之後套在任意 DOCX。
以下逐段與逐個函式解釋用途、重點與常見坑點。
為方便對照,先用小標題標出程式段落名稱,不重貼整段程式碼。
- 套件與基本設定
- 作用
- 匯入 zipfile:讀 .docx/.zip 內容(.docx 本質是 ZIP)。
- 匯入 lxml.etree:解析 XML。
- 匯入 docx.oxml.ns.qn:把 “前綴:名稱” 轉為擴展 QName “{uri}local”,供 Element API 使用。
- 匯入 PurePosixPath:用 POSIX 規則組合 ZIP 內部路徑。
- 重點
- 你可以用 sample.docx 或 sample.zip,兩者 zipfile 都能讀。
- assert zipfile.is_zipfile 確保路徑真的是 ZIP 容器,早期失敗早期發現。
- join_zip_path(base_dir, rel_path)
- 功能
- 把 .rels 的 Target(通常是相對路徑,如 media/image1.png 或 ../media/image2.jpg)與基準目錄(word/)以 POSIX 規則結合,並手動處理 . 與 ..。
- 為什麼不用 os.path 或 Path.resolve
- OOXML/ZIP 內部路徑永遠是 /,與作業系統無關。
用 PurePosixPath 可避免 Windows 反斜線或磁碟機代號污染。 - 我們只處理 ZIP 內部字串,不需要也不應該觸碰實體檔案系統。
- OOXML/ZIP 內部路徑永遠是 /,與作業系統無關。
- 邏輯
- 拆 base_dir 與 rel_path 的 parts。
- 迭代 rel_path 的每個片段:
- “.” 忽略
- “..” 就把 parts 最後一段 pop 掉(回上一層)
- 其他字串就 append
- 最後用 “/” join 回去,得到像 “word/media/image1.png” 這樣的 ZIP 相對路徑。
- 常見坑
- rel_path 可能為空或 None,先行判斷。
- 不回傳以 “/” 開頭的絕對路徑,
因為 ZipFile.namelist() 內的名稱都是相對路徑。
- 讀取核心 XML(document.xml 與 document.xml.rels)
- 功能
- 用 ZipFile 直接讀出兩個檔案:
- word/document.xml:主文檔,內含段落、圖片錨點等。
- word/_rels/document.xml.rels:主文檔對外部資源(含圖片)的關聯表。
- 用 etree.fromstring 解析成元素樹 root。
- 用 ZipFile 直接讀出兩個檔案:
- 重點
- XMLParser(remove_blank_text=True) 幫助後續輸出整齊,但對查詢無影響。
- 如果 zip 裡少其中一個檔案,這裡就會報錯,屬於早期應該發現的問題。
若parser確定要使用 etree.XMLParser(),
可以使用
etree.XML(doc_xml) 取代
etree.fromstring(doc_xml, parser=parser)
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251121153138_0_079b56.png)
- get_rids_with_qn(root_el) — 方法一:qn + find/findall
- 功能
- 在 document.xml 裡找出所有圖片用到的 rId(關聯 ID),來源是 a:blip 節點的 r:embed 屬性。
- 兩段查找的原因
- “.//a:blip”:通用情況,多數圖片都會出現在 a:blip。
- “.//pic:pic//a:blip”:某些文件的圖片包在 pic:pic 節點內層,補抓一次。
- 為什麼用 qn
- find/findall 需要 Clark notation “{uri}local”。用 qn(“a:blip”)、qn(“r:embed”) 讓 python-docx 替你把前綴轉 uri,不必自己維護命名空間字典。
- 回傳值
- 去重後的 rId 清單(排序穩定,利於除錯與比較)。
- 常見坑
- 若文件使用 python-docx 不認得的前綴,qn 會丟 ValueError。但對 OOXML 常見前綴(w、a、r、pic…)是安全的。
- get_rids_with_xpath_prefix(root_el) — 方法二之一:XPath(前綴版)
- 功能
- 用 XPath 直接抓 //a:blip/@r:embed 與 //pic:pic//a:blip/@r:embed。
- 為何需要 NS 映射
- XPath 裡的 a:、r:、pic: 是前綴,不等於實際 URI。必須傳 namespaces=NS 讓引擎知道每個前綴對應的 URI。
- 優點
- 表達式短且可讀性高,適合熟悉 XPath 的人,也利於加入條件過濾。
- 缺點
- 文件若用非常規前綴(雖然 URI 一樣),寫死的前綴 XPath 還是能用,因為前綴對照由你提供;但你要保證 NS 字典正確且齊全。
- get_rids_with_xpath_noprefix(root_el) — 方法二之二:XPath(無前綴 fallback)
- 功能
- 用 local-name() 與 namespace-uri(),避免依賴文件內前綴。
- 表達式解讀
- 先找所有 blip 元素,且它們的 namespace-uri() 必須等於 A(DrawingML)。
- 然後取其屬性中名為 embed 且屬性的 namespace-uri() 等於 R(Relationships)的值。
- 優點
- 文件即使更換前綴也不受影響;對怪文件更堅固。
- 缺點
- 表達式冗長;你仍需要維護關鍵 URI 常數(A、R)。
- 合併 rId
- 為什麼要合併
- 三種找法可能重疊或取到不同位置的重複 rId。以 set 合併去重,再排序,讓後續映射更乾淨。
- 好處
- 即使某一種方法在特定文件失效,其他方法仍可補足,提高穩定度。
- 解析 .rels:rId → Target
- 背景
- document.xml 本身只有 rId,不知道實際檔案位置。document.xml.rels 把每個 rId 對應到 Target(路徑或 URL)。
- XPath 的選擇
- .rels 使用 package relationships 命名空間(http://schemas.openxmlformats.org/package/2006/relationships)。
- 這裡用前綴查詢 //rel:Relationship 並傳入 namespaces={“rel”: PKG_REL}。
- 為什麼不用 “{uri}Relationship” 放在 XPath
- Clark notation 是 Element API 的語法,XPath 不認得。若這樣寫會報 XPathEvalError。
- 回傳
- 建一張 dict:{Id -> Target},例如 {“rId5”: “media/image1.png”}。
- 組 ZIP 內實際路徑並讀圖片 bytes
- 為什麼基準是 “word/”
- document.xml 位於 word/,它的 .rels 內 Target 通常是相對於 word/ 的路徑(例如 media/image1.png 或 ../media/image2.jpg)。
- join_zip_path 的用途
- 把 “word/” 與 Target 正確合併(處理 .. 與 .)。
- 讀取
- 用 ZipFile.namelist() 比對檔名存在後,再 read 取出位元組。
- 收集成 images 字典:{zip內路徑: bytes},方便後續存檔或內存處理。
- 常見坑
- 有些 Target 可能指向外部 URL(TargetMode=”External”),這種不是 ZIP 內檔案,read 會失敗。你的程式現在會自動跳過(因為 zip 裡找不到那個名字)。
整體流程圖(文字版)
- document.xml
- 找 a:blip → 取 @r:embed → 得到 rId 清單
- document.xml.rels
- 查 //Relationship → 用 rId 查到 Target
- ZIP 內
- 用 word/ 作基底 + Target → 實際路徑 → 讀出圖片 bytes
什麼時候選哪一種查法
- 只要「抓 blip 的 r:embed」這類固定任務:優先 qn + find/findall,簡潔且不需 NS 字典。
- 需要條件化與複合查詢(例如按父節點類型、同時抓多種節點、位置篩選):改用 XPath(前綴版)。
- 需要兼容未知或奇怪前綴:加跑一次無前綴 XPath,與其他結果 union。
推薦hahow線上學習python: https://igrape.net/30afN
如何真實移除圖片檔?
對docx瘦身?
Office Open XML (OOXML) 的本質:
「內容描述 (XML)」與「實體資源 (Binary)」是分離的。
要達成需求,我們需要執行以下步驟:
- 修改 XML (視覺移除):
在word/document.xml中找到圖片的標籤
(通常包裹在<w:drawing>中),
將其刪除。這樣打開 Word 時就看不到圖片了。 - 策略一 (假移除):只存回修改過的 XML,
但保留 ZIP 內的media/資料夾。 - 策略二 (真瘦身):存回修改過的 XML,
並且在重組 ZIP 時,跳過 那些被參照的圖片檔案。
以下是完整的實作程式碼:
import zipfile
import os
from lxml import etree
from docx.oxml.ns import qn
#========================
# 1) 設定檔案路徑
#========================
INPUT_DOCX = r"D:\Temp\sample.docx" # 原始檔
OUTPUT_FAKE = r"D:\Temp\sample_fake.docx" # 假移除 (看不到圖,但容量沒變)
OUTPUT_SLIM = r"D:\Temp\sample_slim.docx" # 真瘦身 (看不到圖,容量變小)
# 命名空間定義
NS = {
"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main",
"a": "http://schemas.openxmlformats.org/drawingml/2006/main",
"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships",
"rel": "http://schemas.openxmlformats.org/package/2006/relationships"
}
# 為什麼 "rel" 的 value 這樣定義?
# 請看 document.xml.rels 的最外層:
# <Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
#========================
# 2) 核心邏輯:從 document.xml 移除圖片節點並收集 rId
#========================
from typing import Set, Tuple
# 定義語意化的型別別名
XmlBytes = bytes
def remove_images_from_xml(doc_bytes:XmlBytes ) -> Tuple[XmlBytes, Set[str]]:
"""
解析 XML,移除所有含有圖片 (a:blip) 的 w:drawing 節點。
回傳: (修改後的 XML bytes, 被移除的 rId 集合)
"""
parser = etree.XMLParser(remove_blank_text=True)
root = etree.fromstring(doc_bytes, parser=parser)
# lxml.etree._Element
removed_rids = set()
# 策略:找到所有含有 <a:blip> 的 <w:drawing> 元素
# w:drawing 是 Word 中圖片、圖表、形狀的容器
# a:blip 是實際指向圖片資源的節點
drawings_with_images = root.xpath("//w:drawing[.//a:blip]",
namespaces=NS)
for drawing in drawings_with_images:
# 1. 先抓出裡面的 rId,以便後續知道要刪除哪個檔案
blips = drawing.xpath(".//a:blip",
namespaces=NS)
for blip in blips:
rid = blip.get(qn("r:embed"))
if rid:
removed_rids.add(rid)
# 2. 從 XML 樹狀結構中移除這個 drawing 節點
parent = drawing.getparent()
if parent is not None:
parent.remove(drawing)
# 另外也有可能是在 <w:pict> (舊版格式) 中,
# 這裡簡化只處理 <w:drawing>
return etree.tostring(root, encoding="UTF-8",
xml_declaration=True), removed_rids
#========================
# 3) 輔助邏輯:解析 _rels 找出 rId 對應的檔名
#========================
def get_target_files(rels_bytes, rids_to_remove):
"""
解析 .rels,找出 rId 對應的 Target 路徑 (例如 media/image1.jpeg)
"""
if not rids_to_remove:
return set()
parser = etree.XMLParser(remove_blank_text=True)
root = etree.fromstring(rels_bytes, parser=parser)
targets = set()
# 搜尋所有 Relationship
for rel in root.xpath("//rel:Relationship", namespaces=NS):
rid = rel.get("Id")
if rid in rids_to_remove:
target = rel.get("Target")
# Target 通常是相對路徑 "media/image1.jpeg"
# 在 ZIP 結構中,它相對於 word/ 資料夾,
# 所以完整路徑是 word/media/image1.jpeg
if target:
# 簡單處理路徑拼接 (假設沒有 ../ 跳轉)
full_path = f"word/{target}"
targets.add(full_path)
return targets
#========================
# 4) 執行流程
#========================
# 4-1 讀取原始資料
with zipfile.ZipFile(INPUT_DOCX, 'r') as z_in:
# 讀取必要 XML
doc_xml = z_in.read("word/document.xml")
rels_xml = z_in.read("word/_rels/document.xml.rels")
# 取得所有檔案列表
all_files = z_in.namelist()
# 4-2 處理 XML (記憶體中操作)
new_doc_xml, removed_rids = remove_images_from_xml(doc_xml)
files_to_delete = get_target_files(rels_xml, removed_rids)
print(f"偵測到將被移除的圖片 rId: {removed_rids}")
print(f"對應的 ZIP 內部路徑: {files_to_delete}")
#========================
# 5) 產出檔案 A:假移除 (Fake Removal)
# - document.xml 已經沒有圖片標籤 -> 打開 Word 看不到圖
# - 但 ZIP 裡面還保留著 media/image.png -> 檔案大小幾乎不變
#========================
with zipfile.ZipFile(INPUT_DOCX, 'r') as z_in:
with zipfile.ZipFile(OUTPUT_FAKE, 'w',
compression=zipfile.ZIP_DEFLATED) as z_out:
for filename in z_in.namelist():
if filename == "word/document.xml":
# 寫入修改過的 XML (沒有圖片標籤)
z_out.writestr(filename, new_doc_xml)
else:
# 其他檔案原封不動複製 (包含那些圖片檔!)
z_out.writestr(filename, z_in.read(filename))
#========================
# 6) 產出檔案 B:真瘦身 (Real Slimming)
# - document.xml 已經沒有圖片標籤
# - ZIP 裡面跳過 media/image.png 不寫入 -> 檔案大小顯著縮小
#========================
with zipfile.ZipFile(INPUT_DOCX, 'r') as z_in:
with zipfile.ZipFile(OUTPUT_SLIM, 'w',
compression=zipfile.ZIP_DEFLATED) as z_out:
for filename in z_in.namelist():
# 1. 如果是 document.xml,寫入修改版
if filename == "word/document.xml":
z_out.writestr(filename, new_doc_xml)
# 2. 如果是我們要刪除的圖片,直接跳過 (Skip)
elif filename in files_to_delete:
continue
# 3. 其他檔案照常寫入
else:
z_out.writestr(filename, z_in.read(filename))
#========================
# 7) 結果比較
#========================
size_origin = os.path.getsize(INPUT_DOCX)
size_fake = os.path.getsize(OUTPUT_FAKE)
size_slim = os.path.getsize(OUTPUT_SLIM)
print("-" * 30)
print(f"原始檔案大小: {size_origin/1024:.2f} KB")
print(f"假移除大小 : {size_fake/1024:.2f} KB (視覺無圖,但屍體還在)")
print(f"真瘦身大小 : {size_slim/1024:.2f} KB (視覺無圖,且移除資源)")
print("-" * 30)輸出:
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251124101911_0_998d08.png)
程式碼解析與策略說明
這段程式碼展示了操作 .docx 的兩個層次:
1. 邏輯層 (Logical Layer) – document.xml
- 操作:我們使用
lxml找到<w:drawing>標籤並將其remove()。 - 效果:這就像你在 Word 裡選取圖片並按下 Delete 鍵。Word 的排版引擎讀不到這個標籤,所以畫面上不會顯示圖片。
- 假移除的真相:如果你只做這一步(如
sample_fake.docx),Word 雖然不顯示圖片,但圖片的二進位資料(例如image1.jpeg)仍然躺在 ZIP 壓縮包的word/media/資料夾裡。這就是為什麼很多 Word 檔明明沒幾頁字,卻異常肥大的原因(可能有許多「刪除不乾淨」的圖片殘留)。
2. 物理層 (Physical Layer) – ZIP Container
- 操作:我們在建立新的 ZIP 檔時,利用
filename in files_to_delete判斷式。 - 效果:
- Fake 模式:我們把舊 ZIP 裡的所有檔案(包含圖片)都複製過去。
- Slim 模式:我們刻意不將圖片檔案寫入新的 ZIP。這才是真正減少檔案大小的關鍵步驟。
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f".//{ qn('a:blip') }" ) ; .get( qn("r:embed") ) #獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4') ; lxml.etree._Element.xpath( "//a:blip/@r:embed", namespaces = NS) #/@r:embed = 獲取 屬性名 'r:embed' 的 屬性值(如: 'rId4'),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用"//a:blip/@r:embed" ,可直接獲取屬性值(List[str]如: ['rId4', 'rId5']) ; 如何對docx真實移除圖片瘦身? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/11/20251124103511_0_1094e6.png)
進階思考:關於 _rels 的殘留
在「真瘦身」的程式碼中,為了簡化邏輯,
沒有去修改 word/_rels/document.xml.rels。
- 現狀:
document.xml裡的圖片參照沒了,圖片檔案也沒了,但是rels檔案裡還留著一句「rId4 對應到 media/image1.jpeg」。 - Word 的反應:當你打開
sample_slim.docx時,Word 讀取document.xml,發現沒有任何地方用到rId4,所以它根本不會去試著載入那張圖片。因此,即使rels裡有殘留的定義,通常也不會報錯,檔案依然可以正常開啟且體積變小。 - 完美主義:如果要做到 100% 乾淨,還應該順便把
relsXML 裡面的那個<Relationship Id="rId4"...>節點也刪除,這樣才算完全清除了該圖片的所有痕跡。
推薦hahow線上學習python: https://igrape.net/30afN
NS = {
"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main",
"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships",
# ... 把所有可能用到的都列進去
}如果遍歷xml內容的xmlns建立NS會怎樣?
ECMA-376 (OOXML 標準) 規定了 Word 文件必須使用這個 URL
這就像是寫網頁爬蟲:
- 標準做法:我知道 HTML 的
<a>標籤是用來做超連結的,所以我寫程式去抓<a>。 - 遍歷做法:我先去分析這個網頁用了哪些標籤,發現它用了
<a>,所以我才去抓<a>。
2. 為什麼「遍歷」反而危險? (The Prefix Trap)
假設您寫了一個程式,邏輯是:「讀取 XML -> 抓取所有 xmlns -> 建立 NS 字典 -> 用於 XPath」。
情境 A (正常 Word):
XML 內容:<w:document xmlns:w="http://.../main"> ... </w:document>
程式抓到:{'w': 'http://.../main'}
XPath //w:p:成功。
情境 B (怪異但合法的 XML):
XML 內容:<my:document xmlns:my="http://.../main"> ... </my:document>
(注意:前綴變成了 my,但 URL 還是標準的 URL)
程式抓到:{'my': 'http://.../main'}
XPath //w:p:失敗! (因為字典裡沒有 w,只有 my)
情境 C (人工寫死/標準做法):
程式寫死:NS = {'w': 'http://.../main'}
XML 內容:<my:document xmlns:my="http://.../main"> ... </my:document>
XPath //w:p:成功!
(為什麼?因為 lxml 會把您的 w 對應到 URL,然後去 XML 裡找「對應到同一個 URL」的標籤,不管那個標籤在檔案裡叫 w 還是 my。)
結論
您說的沒錯,資訊來源都是 XML。但:
- 人工寫 (Hardcode):是建立一個「我預期要用的標準別名表」。這讓您的 XPath 程式碼 (//w:p) 永遠有效,不受檔案內部前綴命名影響。
- 程式遍歷 (Dynamic):是建立一個「檔案實際使用的別名表」。這會導致您的 XPath 程式碼必須跟著檔案變(如果檔案用 my:p,您的 XPath 也得改成 //my:p),這會讓程式變得非常難寫且不穩定。
所以,我們寫 NS 字典,其實是在定義我們自己的「查詢語言」,強迫 XML 解析器聽懂我們的 w 是什麼意思,而不是我們去配合 XML 檔案裡的叫法。
您可以在以下幾個地方查閱 ECMA-376 (OOXML) 標準:
- ECMA International 官方網站 (最權威,但文件極其龐大):
- Standard ECMA-376 Office Open XML File Formats
- 這裡可以下載完整的 PDF 規格書(分為 Part 1 到 Part 4)。Part 1 (Fundamentals) 和 Part 4 (Transitional Migration Features) 最常被參考。
- ISO/IEC 標準 (與 ECMA-376 等價):
- ISO/IEC 29500。這是經過 ISO 認證後的版本,內容與 ECMA-376 幾乎一致。
- Microsoft Open Specifications (實用性最高,推薦開發者使用):
- [MS-DOCX]: Word Extensions to the Office Open XML Structure
- 微軟的官方文件通常比標準書更好讀,而且會列出 Office 各個版本(2007, 2010, 2013…)的實作差異。
- 您可以在這裡搜尋特定的標籤(如
w:sectPr)或命名空間 URL。
- Office Open XML (OOXML) 結構瀏覽網站 (非官方,但極好用的速查工具):
- http://officeopenxml.com/
- 這個網站把龐大的規格書整理成好讀的網頁,分類清楚(Word, Excel, PowerPoint),解釋每個 XML 標籤的用途和屬性,非常適合開發者快速查找。
關於命名空間 (Namespaces) 的部分:
在上述文件的 “Namespaces” 章節,或者直接看 XML Schema 定義檔 (XSD),您就會看到那些我們熟悉的 URL:
http://schemas.openxmlformats.org/wordprocessingml/2006/main(對應w)http://schemas.openxmlformats.org/officeDocument/2006/relationships(對應 r)
這些 URL 就是定義在這些標準文件裡的「金鑰」,全球通用。
 客戶端:Azure、OpenAI 與 Poe 整合指南")
 ; 如何用numpy.polyfit() 做外插?")
和列表list(長度需一致)指配給DataFrame的新column?")
取代")
; 對於np.bool_ 做乘法等效於and ; 對於np.bool_ 做加法等效於or")
=TURE與IFERROR函數;IF ISNA()=TURE與IFNA函數")
.resolve().parent")
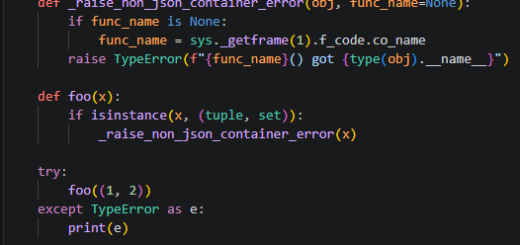
 實戰:教你如何讓程式碼「自我介紹」; func_name = sys._getframe().f_code.co_name ; inspect.currentframe().f_code.co_name")
轉成 AST (Abstract Syntax Tree , 抽象語法樹)並匯出成 JSON; markdown = mistune.create_markdown( renderer=’ast’ )")


近期留言