MRO 全名是 Method Resolution Order(方法解析順序)。它是一個列表(List),定義了 Python 在尋找屬性或方法時,會依照什麼順序遍歷類別繼承體系。
你可以透過類別的 .mro() 方法或 __mro__ 屬性來查看這個順序。
在 python-docx 中,CT_P 代表 Word 文件中的一個 段落 (Paragraph) 元素(對應 XML 標籤 <w:p>)。為了讓這個物件既能像 XML 元素一樣操作,又能擁有 Python 的便利功能,它繼承了多層類別。
1. 繼承結構模擬
簡化後的 CT_P 繼承結構大致如下(這不是完整源碼,而是邏輯結構):
# 這是 lxml 函式庫的基礎類別,處理底層 XML
class _Element:
def __init__(self):
print("-> 初始化 _Element (lxml 底層)")
# 這是 python-docx 的基礎類別,封裝了 lxml
class ElementBase(_Element):
def __init__(self):
print("-> 進入 ElementBase")
super().__init__() # 呼叫 MRO 下一個
print("<- 離開 ElementBase")
# 這是所有 Open XML 元素的基類
class BaseOxmlElement(ElementBase):
def __init__(self):
print("-> 進入 BaseOxmlElement")
super().__init__() # 呼叫 MRO 下一個
print("<- 離開 BaseOxmlElement")
# 這是具體的段落元素類別
class CT_P(BaseOxmlElement):
def __init__(self):
print("-> 進入 CT_P (段落)")
super().__init__() # 呼叫 MRO 下一個
print("<- 離開 CT_P")
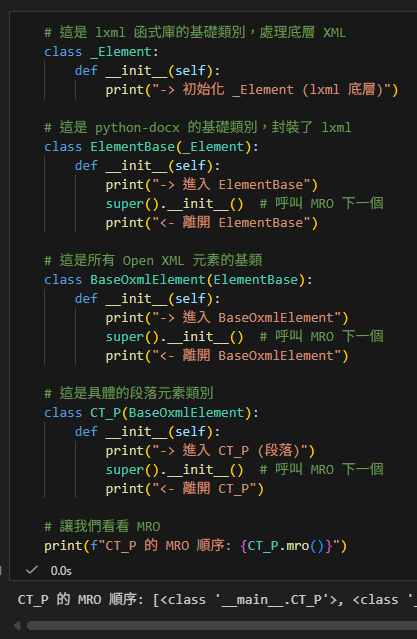
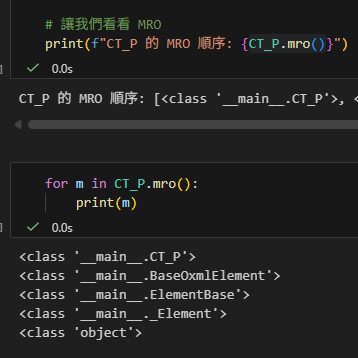
# 讓我們看看 MRO
print(f"CT_P 的 MRO 順序: {CT_P.mro()}")2. MRO 解析
當你執行 CT_P.mro() 時,
你會得到類似這樣的列表(順序至關重要):
[<class '__main__.CT_P'>,
<class '__main__.BaseOxmlElement'>,
<class '__main__.ElementBase'>,
<class '__main__._Element'>,
<class 'object'>]CT_P 的 MRO 順序:
3. 為什麼這在 python-docx 中很重要?
當我們創建一個段落物件 p = CT_P() 時,Python 會依照上述 MRO 順序執行 __init__ 或查找方法。
情境模擬:屬性查找 (Attribute Lookup)
假設你想存取段落的 XML 屬性,例如 p.attrib。
- Python 先去
CT_P找有沒有定義attrib?沒有。 - 接著去
BaseOxmlElement找?沒有。 - 接著去
ElementBase找?沒有。 - 最後去
_Element(lxml 的實作) 找?找到了!
情境模擬:super() 的接力棒
這就是 MRO 最強大的地方。當我們在 CT_P 裡呼叫 super() 時:
- 它不是簡單地呼叫「父類別」。
- 它是看著 MRO 列表,說:「下一個是誰?喔,是
BaseOxmlElement,換你了。」 BaseOxmlElement執行完它的邏輯後,也呼叫super(),它看著 MRO 列表說:「下一個是ElementBase,換你了。」
這保證了一條單向、不重複的初始化鏈條。如果沒有嚴格的 MRO,在多重繼承(例如某個元素同時繼承了「可修改屬性」和「可被刪除屬性」兩個 Mixin 類別)的情況下,底層的 _Element 可能會被初始化兩次,導致 XML 解析錯誤或記憶體浪費。
結論
對於 CT_P 這樣的類別,MRO 就像是一個洋蔥的層次:
- 最外層 (CT_P):處理具體的段落邏輯(如對齊方式)。
- 中間層 (BaseOxmlElement):處理通用的 OpenXML 邏輯(如命名空間)。
- 核心層 (_Element):處理最底層的 XML 解析。
MRO 確保了當你操作一個段落時,Python 能精準地穿透這些層次,找到正確的方法來執行。
推薦hahow線上學習python: https://igrape.net/30afN
我們不模擬,直接 import 真實的 python-docx 函式庫來查看 CT_P 的 MRO。
這會揭示 python-docx 底層是如何依賴 lxml 這個強大的 C 語言 XML 處理庫的。
實際執行程式碼
如果你在安裝了 python-docx 的環境中執行以下 Python 程式碼:
# %%
from docx.oxml.text.paragraph import CT_P
# 列印出 CT_P 的方法解析順序 (MRO)
print("--- CT_P 的真實 MRO ---")
for i, cls in enumerate(CT_P.mro()):
print(f"{i}. {cls}")實際輸出結果
你會得到類似以下的輸出(視 python-docx 和 lxml 的版本微小差異,但結構是一致的):
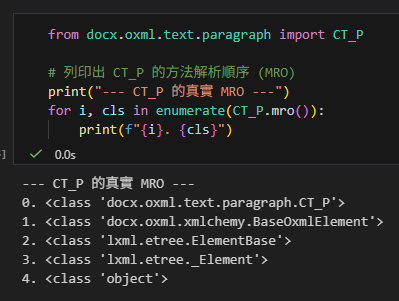
真實結構解析
這個真實的 MRO 列表告訴了我們幾個關鍵事實,這比剛才的模擬更具體:
docx.oxml.text.paragraph.CT_P(第 0 層)- 這是你在
python-docx中操作的最上層類別。它定義了 Word 段落特有的行為(例如:設定段落樣式pPr、添加run等)。
- 這是你在
docx.oxml.xmlchemy.BaseOxmlElement(第 1 層)- 這是
python-docx自己定義的基類。 - 關鍵作用:它負責將 Python 的屬性操作(如
paragraph.alignment)轉換為底層的 XML 操作。它實現了python-docx獨有的 “Xmlchemy” 魔法,讓 XML 節點操作起來像 Python 物件。
- 這是
lxml.etree.ElementBase(第 2 層)- 這裡跨越了邊界。我們離開了純 Python 的
docx程式碼,進入了lxml函式庫的領域。 - 這是
lxml允許使用者自定義 XML 元素行為的擴充點。python-docx正是利用這個類別,將自己的邏輯「掛載」到 XML 樹上。
- 這裡跨越了邊界。我們離開了純 Python 的
lxml.etree._Element(第 3 層)- 這是 C 語言實作 的核心。
- 它是
lxml對 C 語言libxml2的封裝。所有的記憶體管理、XML 解析、序列化都在這一層極速完成。 - 這解釋了為什麼
python-docx處理大型文件速度還不錯,因為最繁重的 XML 樹狀結構維護是由這一層 C 語言程式碼處理的。
object(第 4 層)- Python 的根類別。
結論
透過真實的 MRO,我們看到 CT_P 其實是一個「混血兒」:它外表是 python-docx 的物件,但骨子裡(透過繼承 lxml)直接連通到高效能的 C 語言 XML 引擎。MRO 確保了當你呼叫一個方法時,Python 能正確地在這些 Python 層和 C 擴充層之間導航。
推薦hahow線上學習python: https://igrape.net/30afN
這五層結構並不是為了把事情搞複雜,而是為了**「職責分離」(Separation of Concerns)**。每一層都解決了一個特定的難題,如果不分層,整個 python-docx 的程式碼會變成一團無法維護的義大利麵。
我們可以把這五層想像成一個**「漢堡」**,每一層都有它存在的理由:
1. 最底層:lxml.etree._Element (C 語言層)
- 職責:效能與標準
- 為什麼需要它? XML 解析非常消耗資源。如果用純 Python 寫一個 XML 解析器,處理幾百頁的 Word 文件會慢到讓你懷疑人生。
- 它的工作: 這一層直接對接 C 語言的
libxml2,負責最髒、最累、但需要最快速度的工作(記憶體管理、指標操作、XML 規範解析)。它不關心什麼是 Word,它只關心什麼是 XML。
2. 中間層:lxml.etree.ElementBase (橋樑層)
- 職責:擴充性
- 為什麼需要它? C 語言層(上一層)是編譯好的,很難修改。
ElementBase是lxml留給 Python 開發者的一個「插座」。 - 它的工作: 它允許開發者說:「嘿,當你讀到一個
<w:p>標籤時,不要只把它當作普通 XML 節點,請把它當作我定義的特殊 Python 物件來處理。」沒有這一層,python-docx就無法將 XML 節點「變身」為聰明的 Python 物件。
3. 抽象層:docx.oxml.xmlchemy.BaseOxmlElement (魔法層)
- 職責:簡化 XML 操作 (DSL)
- 為什麼需要它? 直接操作
lxml還是很繁瑣(例如你需要手動處理命名空間w:,a:,r:等)。如果每個 Word 元素都要寫一堆find(),xpath(),set(),程式碼會很醜。 - 它的工作: 這是
python-docx最聰明的地方。它定義了一套規則(Xmlchemy),讓你可以用類似element.some_attribute的方式來操作 XML 屬性,它會自動幫你處理底層的 XML 命名空間和序列化細節。它是所有 Word 元素的「通用模板」。
4. 應用層:docx.oxml.text.paragraph.CT_P (業務邏輯層)
- 職責:定義 Word 的具體行為
- 為什麼需要它? 上一層只提供了「操作 XML 的工具」,但不懂「什麼是段落」。
- 它的工作: 這一層才真正定義了 Word 的業務邏輯。例如:「段落裡面可以有 Run(文字塊)」、「段落可以有對齊方式」。它利用上一層提供的工具,具體實作了 Word 規範(OOXML)中關於
<w:p>的所有規定。
總結:為什麼不合在一起?
如果把這四層的程式碼全部寫在一個類別裡:
- 效能崩潰:你得自己用 Python 處理 XML 解析。
- 維護地獄:想像一下,處理 C 記憶體的程式碼和處理 Word 段落對齊的程式碼混在一起。
- 無法重用:如果你想再寫一個處理 Excel (
python-pptx) 的庫,你就得把 XML 解析的邏輯重寫一遍。現在這樣分層,python-pptx也可以直接繼承BaseOxmlElement和lxml,完全不用重造輪子。
所以,這多層結構是為了讓底層夠快(C 語言),中間層夠通用(BaseOxmlElement),而頂層夠專注(CT_P 只管段落邏輯)。
推薦hahow線上學習python: https://igrape.net/30afN
")
) ; ax.annotate(text,xy,…) #註釋 ; 通用屬性 ; linestyle ;圖例 legend ; set_title()、set_xlabel()、set_ylabel() ; 網格 ax.grid(visible=None, axis=’both’, …) ; ax.set_xticks() ; ax.set_yticks()")
 ; glob.glob() #讀取資料夾中的所有檔案 ; os.path.split(fpath) = os.path.dirname(fpath) , os.path.basename(fpath) ; os.path.splitext(basename) #分離主/副檔名")



 刪除空列(axis=0) 空欄(axis=1) ; df_drop0 = df.dropna(axis=0, how=’all’)")
 合併兩個DataFrame? 具關聯性欄位合併")



近期留言