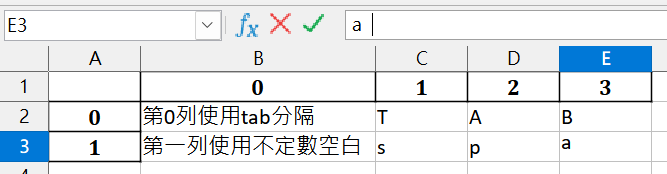
test.txt內容如下:
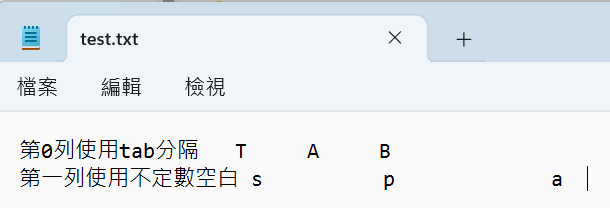
第一列最後的a之後,故意多兩個空白
Q1: 如何分辨分隔子是tab還是不定數空白?
Q2: 如何讀取tab與不定數空白混用的csv?
Q3: 如何用pandas.Series.str.split()
將Series依據分隔子(tab與不定數空白混用)
拆分為多欄的DataFrame?
Q1 & Q2:
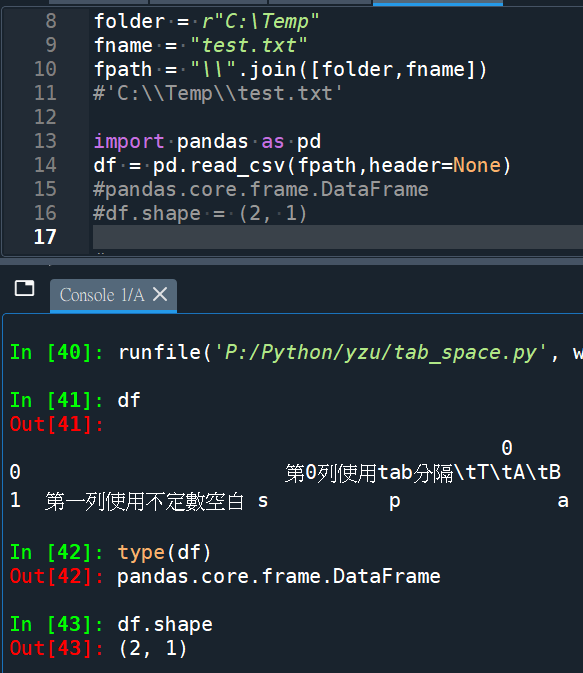
df的第0列出現三個 \t
第一列則無
可以據此分辨
tab與不定數空白
雖然df只有一欄而已
仍須注意其type為DataFrame
需要將df轉為Series
才能使用
pandas.Series.str.split( pat = “\s+|\t“, expand=True, n=3 )
使用 ser = df.iloc[:,0] 轉換:

或者df[0] 也可,
0為column name:
#df[[0]]則為DataFrame,
#內層的[]是list的意思

df_split = ser.str.split( pat =”\s+|\t“,expand=True)
正則表示法:
\s+ 不定數空白
\t TAB鍵
| 或
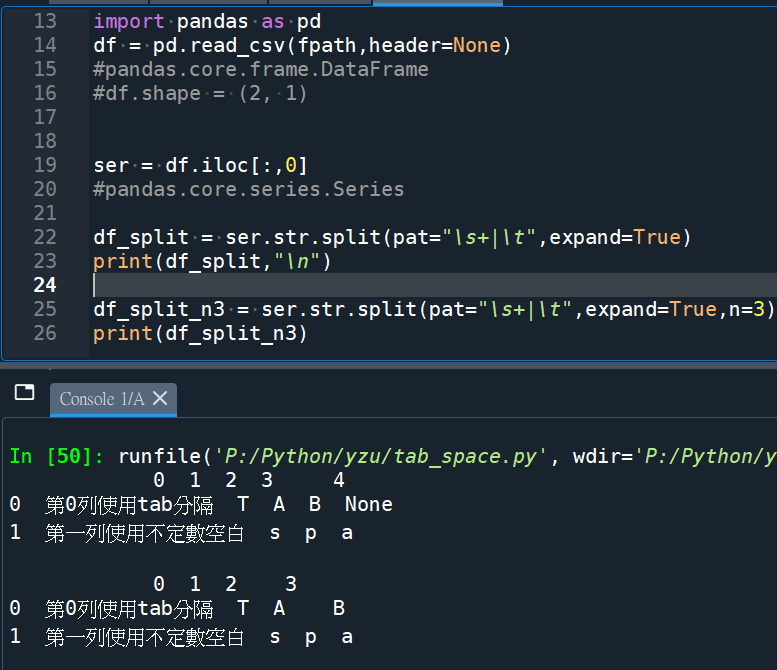
df_split
df_split_n3
可以看出參數n=3的差異
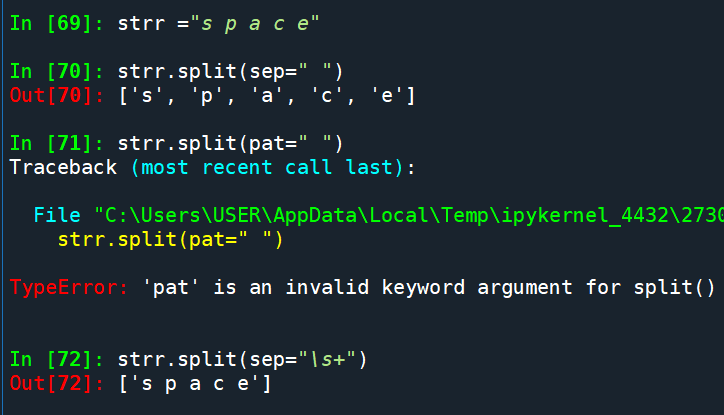
str type的變數,
參數使用sep (非pat)
且不支援 正則表示法:
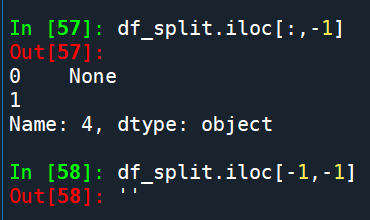
df_split.to_excel(r”C:\temp\df_split.xlsx”):

最後一欄為空
Python中顯示None ” (空字串):
多加一個參數n=3
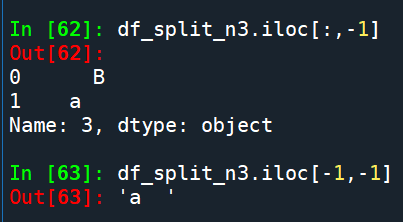
df_split_n3.to_excel(r”C:\temp\df_split_n3.xlsx”)
沒有出現最後一個空欄了
但a後面有多餘的空白
也就是剩下沒切割的
都堆在最後一欄
Python中顯示:
如果想要處理多餘的空白
df_split_n3.iloc[:, -1].str.strip()


推薦hahow線上學習python: https://igrape.net/30afN
,列高不同之下拉設定")
」與 AST 語法樹")
![Python: 如何用 pandas.DataFrame.apply 讓DataFrame增加新的一欄 ; df[“mean”] = df.apply( np.mean, axis=1) ; DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230519084320_22.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何用 pandas.DataFrame.apply 讓DataFrame增加新的一欄 ; df[“mean”] = df.apply( np.mean, axis=1) ; DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)")
 — 使用 groupby(“Name”).cumcount, set_index 與 unstack 將長格式轉為寬格式")
; from bs4 import BeautifulSoup")



的參數axis=0 / 1 vs index / columns ; 如何drop DataFrame的rows / columns ?")

近期留言