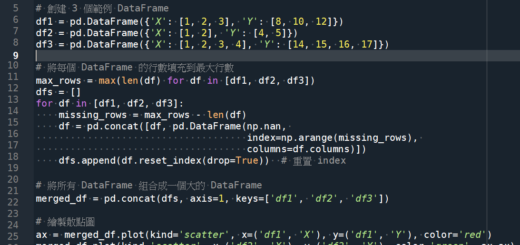
20140817_09_HX400V_宜蘭國際童玩節_土耳其 by 儲蓄保險王 · 2014-08-27 20140817_09_HX400V_宜蘭國際童玩節_土耳其 https://www.youtube.com/watch?v=gnCYOBgK9Js 相關文章Python四種型態增加元素 list.append(元素), tuple = tuple + (元素, ), set.add(元素), dict[key]=value20140817_18_HX400V_宜蘭國際童玩節_俄羅斯Python:使用struct() 對二進位數據打包、解包 data = struct.pack (format_str, 1, 2, 3.14) ; result = struct.unpack (format_str, data) ; numpy.fromfile() ;Python: 如何用tkinter做出 對話 Button GUI? 點Button即可選擇一個或多個檔案 file_paths = filedialog .askopenfilenames (filetypes = ( ("CSV files", "*.csv"), ("PNG files", "*.png"), ("All files","*.*") ) ) ; 關閉視窗後Spyder 的 console 自動回到正常狀態,不需要手動按 Ctrl + C ; root.destroy()Python中的文件和路徑操作:使用os.path函數和__file__變數; os.path.split() #一次取得dirname , basename 可以取代os.path.dirname() + os.path.basename() ;分離主/副檔名: os.path.splitext() #split ext ; os.path.join( folder, fname) #將folder, fname合併為完整的路徑Python: 網路爬蟲 selenium 開啟chrome瀏覽器自動連線 ; chrome = webdriver.Chrome( options=options ) ; Python的命名慣例: 全大寫表示常數,首字大寫表示ClassWord表格設計,TQC考題204:成績單,段落前分頁Python: 三個不同長度 pandas.DataFrame 的資料如何繪製在同一張散佈圖?Python TQC考題802 字元對應,ASCII碼ord(), chr(), list(str)會把字串的每一個字母拆分進入list中,string跟list都可以使用index定位,沒有非要將string轉為list, for i in str: i 也可以依序代入str的每一個chr
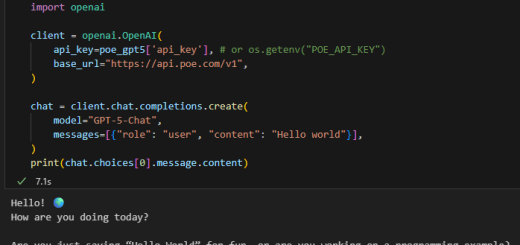
0 Python 進階實戰:深入 Word 核心,挖出那一坨 BLOB (含自省 Debug 技巧, BLOB= Binary Large Object) ; part = doc.part.rels[rid].target_part ; return part.blob if “ImagePart” in type(part).__name__ else None 2026-01-25

![Python四種型態增加元素 list.append(元素), tuple = tuple + (元素, ), set.add(元素), dict[key]=value](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220513083711_22.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python四種型態增加元素 list.append(元素), tuple = tuple + (元素, ), set.add(元素), dict[key]=value")

 對二進位數據打包、解包 data = struct.pack (format_str, 1, 2, 3.14) ; result = struct.unpack (format_str, data) ; numpy.fromfile() ;")
, (“PNG files”, “*.png”), (“All files”,”*.*”) ) ) ; 關閉視窗後Spyder 的 console 自動回到正常狀態,不需要手動按 Ctrl + C ; root.destroy()")
 #一次取得dirname , basename 可以取代os.path.dirname() + os.path.basename() ;分離主/副檔名: os.path.splitext() #split ext ; os.path.join( folder, fname) #將folder, fname合併為完整的路徑")
 ; Python的命名慣例: 全大寫表示常數,首字大寫表示Class")


, chr(), list(str)會把字串的每一個字母拆分進入list中,string跟list都可以使用index定位,沒有非要將string轉為list, for i in str: i 也可以依序代入str的每一個chr")
![Python 進階實戰:深入 Word 核心,挖出那一坨 BLOB (含自省 Debug 技巧, BLOB= Binary Large Object) ; part = doc.part.rels[rid].target_part ; return part.blob if "ImagePart" in type(part).__name__ else None - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/01/20260126111046_0_cd8751-520x245.png)
近期留言