當我們要從 URL 中獲取參數時,
我們可以使用 urlparse 函數來解析 URL,
並使用 parse_qs 函數來解析查詢參數。
假設有以下 URL:http://example.com/?name=John&age=30&gender=male
示範如何使用 urlparse 和 parse_qs:
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 29 20:21:54 2023
@author: SavingKing
"""
from urllib.parse import urlparse, parse_qs
url = "http://example.com/?name=John&age=30&gender=male"
parsed_url = urlparse(url)
query_params = parse_qs(parsed_url.query)
print("Parsed URL:", parsed_url)
print("Query Parameters:", query_params)
print("Name:", query_params['name'][0])
print("Age:", query_params['age'][0])
print("Gender:", query_params['gender'][0])輸出結果:
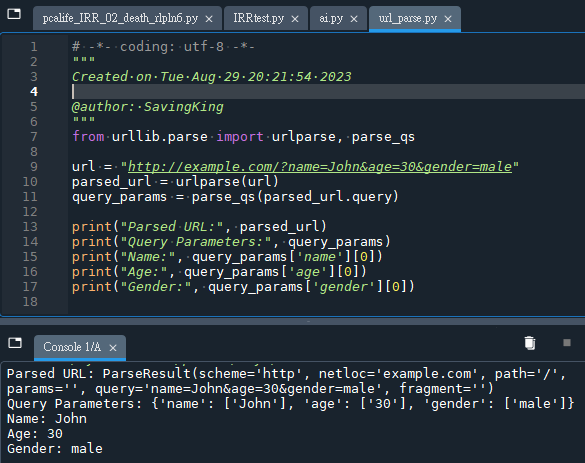
在這個示範中,我們使用了 urlparse 來解析 URL,
並使用 parse_qs 來解析查詢參數。
注意,parse_qs 返回的是一個字典,
其中鍵是參數名,值是包含參數值的列表。
因此,我們使用 query_params['name'][0] 來獲取名為 name 的參數的值。
可以自己寫出相似的程式:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 24 23:35:04 2023
@author: SavingKing
"""
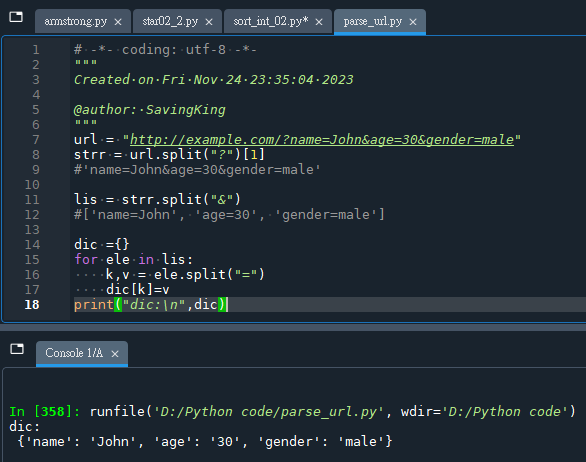
url = "http://example.com/?name=John&age=30&gender=male"
strr = url.split("?")[1]
#'name=John&age=30&gender=male'
lis = strr.split("&")
#['name=John', 'age=30', 'gender=male']
dic ={}
for ele in lis:
k,v = ele.split("=")
dic[k]=v
print("dic:\n",dic)執行結果:
推薦hahow線上學習python: https://igrape.net/30afN
 ; 如何獲取pandas.DataFrame多層索引MultiIndex中的第二層內容? df.columns.get_level_values(1).unique()")

 as source: audio = r.record(source) ; 如何使用mic當音源? with sr.Microphone() as source: audio_data = recognizer.listen(source)")
")
 比較像實際行為; setdefault() vs defaultdict(list)")

 與 os.stat() 讀懂檔案資訊; from pathlib import Path ; type(p).__name__ #’WindowsPath’; p.stat().st_size == os.stat(p).st_size == os.path.getsize(p)")

如何設定sep參數才能讀取分隔子同時有, ” ” (空白)的csv檔? df = pd.read_csv(‘test.txt’, sep = ‘\s*,\s*|\s+’, engine=’python’)")



近期留言