📚 前言:兩種遍歷方式的差異
使用 python-docx 時,有兩種主要的遍歷文檔方式:
- 簡單方式:
doc.paragraphs– 只能看到段落 - 進階方式:遍歷
doc.element.body– 能看到完整結構
本文將詳細說明兩種方式的差異、使用場景和注意事項。
📖 第一章:基礎對比
1.1 簡單方式:doc.paragraphs
from docx import Document
# 創建測試文檔
doc = Document()
doc.add_heading('第一章', level=1)
doc.add_paragraph('這是第一段文字')
doc.add_table(rows=2, cols=2) # 添加表格
doc.add_paragraph('這是表格後的文字')
# 簡單方式:只能看到段落
print("使用 doc.paragraphs:")
for i, para in enumerate(doc.paragraphs):
print(f"段落 {i}: {para.text}")
print(f" 樣式: {para.style.name}") # ✅ 可以安全訪問樣式
# 輸出:
# 段落 0: 第一章
# 段落 1: 這是第一段文字
# 段落 2: 這是表格後的文字
# 注意:看不到表格!輸出:

1.2 進階方式:遍歷 body 元素
# 進階方式:能看到所有元素
print("\n遍歷 doc.element.body:")
body = doc.element.body
for i, elem in enumerate(body):
elem_type = elem.tag.split('}')[-1] # 獲取元素類型
if elem_type == 'p': # 段落
# 獲取段落文字(不創建 Paragraph 對象)
text = ''.join(t.text for t in elem.iter() if t.tag.endswith('}t') and t.text)
print(f"位置 {i}: [段落] {text}")
elif elem_type == 'tbl': # 表格
print(f"位置 {i}: [表格]")
elif elem_type == 'sectPr': # 節屬性
print(f"位置 {i}: [節屬性/分頁]")
# 輸出:
# 位置 0: [段落] 第一章
# 位置 1: [段落] 這是第一段文字
# 位置 2: [表格] ← 看到表格了!
# 位置 3: [段落] 這是表格後的文字輸出:

🎯 第二章:正確的使用方式
2.1 手動創建 Paragraph 對象的正確方法
‘D:\Temp\test_document.docx’ #path
#有段落,也有表格

當我們需要遍歷 body 元素並同時訪問段落屬性時,正確的做法是:
from docx import Document
from docx.text.paragraph import Paragraph
doc = Document(path)
body = doc.element.body
for elem in body:
if elem.tag.endswith('p'):
# ✅ 正確:使用 doc 作為 parent
para = Paragraph(elem, doc)
#可改為 doc._body,
#用 doc.element.body 屬性會有少
#docx.text.paragraph.Paragraph
# 現在可以訪問所有屬性
print(f"文字: {para.text}")
print(f"樣式: {para.style.name}")
print(f"對齊: {para.alignment}")
print(f"Runs: {len(para.runs)}")輸出:

2.2 為什麼必須用 doc 作為 parent?
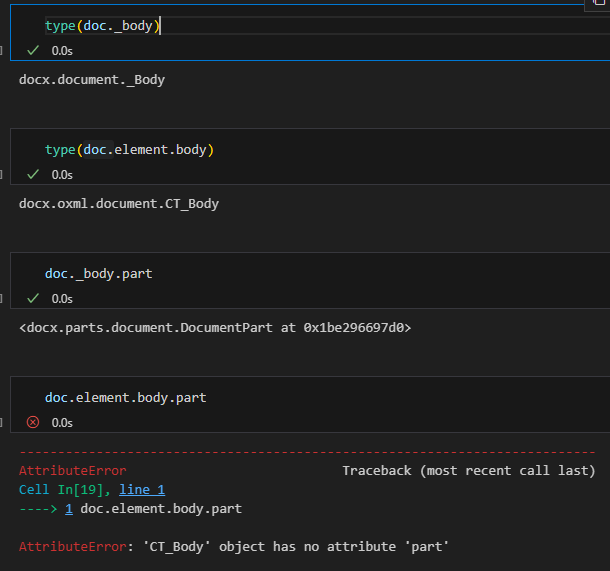
關鍵在於 part 屬性:
# Document 對象有 part 屬性
doc.part # ✅ <docx.parts.document.DocumentPart object>
# CT_Body 對象沒有 part 屬性
body.part # ❌ AttributeError: 'CT_Body' object has no attribute 'part'doc._body vs doc.element.body
Paragraph 類的許多屬性都依賴 part:
# Paragraph 類內部簡化示意
class Paragraph:
def __init__(self, p_element, parent):
self._element = p_element
self._parent = parent
@property
def style(self):
# 需要通過 parent.part 來獲取樣式
style_id = self._element.style
return self._parent.part.get_style(style_id) # 這裡需要 part!2.3 實際應用:帶樣式判斷的章節定位
def find_sections_with_style(doc, style_name="Heading 1"):
"""
找出所有特定樣式的章節
"""
from docx.text.paragraph import Paragraph
body = doc.element.body
sections = []
for idx, elem in enumerate(body):
if elem.tag.endswith('p'):
# 使用 doc 作為 parent
para = Paragraph(elem, doc)
if para.style.name == style_name:
sections.append({
'index': idx,
'text': para.text,
'style': para.style.name,
'alignment': para.alignment,
'font_name': para.style.font.name,
'font_size': para.style.font.size.pt if para.style.font.size else None
})
return sections
# 使用範例
sections = find_sections_with_style(doc, "Heading 1")
for s in sections:
print(f"\n📍 {s['text']}")
print(f" 位置: body[{s['index']}]")
print(f" 字型: {s['font_name']} {s['font_size']}pt")輸出:

2.4 處理複雜文檔結構:包含表格
def find_all_headings(doc, heading_styles=["Heading 1", "Heading 2"]):
"""
找出所有標題,包括表格內的標題
"""
from docx.text.paragraph import Paragraph
body = doc.element.body
headings = []
for idx, elem in enumerate(body):
if elem.tag.endswith('p'):
para = Paragraph(elem, doc)
if para.style.name in heading_styles:
headings.append({
'index': idx,
'text': para.text,
'style': para.style.name,
'type': 'paragraph'
})
#因為標題不可能在表格中,以下是在做白工:
elif elem.tag.endswith('tbl'):
# 處理表格內的段落
for cell in elem.iter('{http://schemas.openxmlformats.org/wordprocessingml/2006/main}tc'):
for p in cell.iter('{http://schemas.openxmlformats.org/wordprocessingml/2006/main}p'):
para = Paragraph(p, doc)
if para.style.name in heading_styles:
headings.append({
'index': idx,
'text': para.text,
'style': para.style.name,
'type': 'table'
})
return headings輸出:

2.5 實戰案例:提取Heading 1 標題的邊界並刪除其下的整個內容:
def get_chapter_range(doc, chapter_keyword, style_name=None):
"""
獲取章節的起始和結束索引,以及所有相關元素的詳細資訊
Args:
doc: Document 對象
chapter_keyword: 章節關鍵字
style_name: 指定的樣式名稱。如果為 None,則收集所有 Heading 樣式
Returns:
dict: 包含章節範圍和元素詳細資訊
"""
from docx.text.paragraph import Paragraph
from docx.table import Table
body = doc.element.body
heading_indices = []
all_elements = [] # 記錄所有元素的類型和資訊
# 第一遍:收集所有元素資訊
for idx, elem in enumerate(body):
elem_info = {
'index': idx,
'element': elem,
'tag': elem.tag
}
if elem.tag.endswith('p'):
para = Paragraph(elem, doc)
elem_info['type'] = 'paragraph'
elem_info['text'] = para.text
elem_info['style'] = para.style.name
elem_info['paragraph_obj'] = para
# 判斷是否為標題
if style_name is None:
if para.style.name.startswith("Heading"):
elem_info['is_heading'] = True
elem_info['level'] = int(para.style.name.split()[-1])
heading_indices.append(elem_info)
else:
if para.style.name == style_name:
elem_info['is_heading'] = True
heading_indices.append(elem_info)
elif elem.tag.endswith('tbl'):
elem_info['type'] = 'table'
elem_info['table_obj'] = Table(elem, doc)
else:
elem_info['type'] = 'other'
all_elements.append(elem_info)
# 找到目標章節
for i, heading in enumerate(heading_indices):
if chapter_keyword in heading['text']:
start_idx = heading['index']
# 找到結束點
if style_name is None:
target_level = heading['level']
end_idx = len(body)
for j in range(i + 1, len(heading_indices)):
if heading_indices[j]['level'] <= target_level:
end_idx = heading_indices[j]['index']
break
else:
end_idx = heading_indices[i + 1]['index'] if i + 1 < len(heading_indices) else len(body)
# 收集範圍內的所有元素
elements_in_range = []
for elem_info in all_elements:
if start_idx <= elem_info['index'] < end_idx:
elements_in_range.append(elem_info)
return {
'found': True,
'title': heading['text'],
'style': heading['style'],
'start': start_idx,
'end': end_idx,
'level': heading.get('level', None),
'elements': elements_in_range,
'element_count': len(elements_in_range),
'paragraph_count': sum(1 for e in elements_in_range if e['type'] == 'paragraph'),
'table_count': sum(1 for e in elements_in_range if e['type'] == 'table')
}
return {'found': False}
def delete_chapter(doc, chapter_keyword, style_name=None, dry_run=True):
"""
刪除指定章節的所有內容
Args:
doc: Document 對象
chapter_keyword: 章節關鍵字
style_name: 指定的樣式名稱
dry_run: 如果為 True,只顯示將要刪除的內容,不實際刪除
Returns:
int: 刪除的元素數量
"""
# 獲取章節範圍
range_info = get_chapter_range(doc, chapter_keyword, style_name)
if not range_info['found']:
print(f"找不到包含 '{chapter_keyword}' 的章節")
return 0
print(f"\n找到章節: {range_info['title']} ({range_info['style']})")
print(f"範圍: [{range_info['start']} - {range_info['end']})")
print(f"包含: {range_info['paragraph_count']} 個段落, {range_info['table_count']} 個表格")
if dry_run:
print("\n[預覽模式] 將要刪除的內容:")
for elem in range_info['elements'][:10]: # 只顯示前10個
if elem['type'] == 'paragraph':
print(f" [{elem['index']}] 段落: {elem['text'][:50]}...")
elif elem['type'] == 'table':
print(f" [{elem['index']}] 表格")
if len(range_info['elements']) > 10:
print(f" ... 還有 {len(range_info['elements']) - 10} 個元素")
return 0
# 實際刪除操作
body = doc.element.body
deleted_count = 0
# 從後往前刪除,避免索引變化的問題
for elem in reversed(range_info['elements']):
try:
body.remove(elem['element'])
deleted_count += 1
except Exception as e:
print(f"刪除元素 {elem['index']} 時出錯: {e}")
print(f"\n成功刪除 {deleted_count} 個元素")
return deleted_count
# 使用範例
# 1. 查看章節資訊
range_info = get_chapter_range(doc, "PCBA測試計畫")
if range_info['found']:
print(f"章節資訊:")
print(f" 標題: {range_info['title']}")
print(f" 範圍: [{range_info['start']} - {range_info['end']})")
print(f" 元素數: {range_info['element_count']}")
print(f" 段落數: {range_info['paragraph_count']}")
print(f" 表格數: {range_info['table_count']}")
# 2. 預覽要刪除的內容(不實際刪除)
delete_chapter(doc, "PCBA測試計畫", dry_run=False)
# 3. 實際刪除章節
# delete_chapter(doc, "PCBA測試計畫", dry_run=False)
# doc.save("modified_document.docx")
# 4. 更精確的刪除:保留標題,只刪除內容
def delete_chapter_content_only(doc, chapter_keyword, style_name=None):
"""只刪除章節內容,保留章節標題"""
range_info = get_chapter_range(doc, chapter_keyword, style_name)
if not range_info['found']:
return 0
body = doc.element.body
deleted_count = 0
# 跳過第一個元素(標題),從第二個開始刪除
for elem in reversed(range_info['elements'][1:]):
try:
body.remove(elem['element'])
deleted_count += 1
except Exception as e:
print(f"刪除時出錯: {e}")
return deleted_count刪除後vs原始:

推薦hahow線上學習python: https://igrape.net/30afN
, f.write(datanew)")
 ; 如何處理unicode?")
 or Spyder import模組執行後,出現no module找不到指定模組錯誤, settings.json , import sys ; lst = sys.path ; sys.path.append() ;Spyder: Tools => PYTHONPATH manager")
,52)")
![Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220514163621_72.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1")



 ) .decode(‘utf-8’)")
![Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler('app.log', mode='a', encoding='utf-8')] ) ; inspect.currentframe().f_code.co_name #動態取得funcName - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/10/20251021155823_0_c16012-472x245.png)

近期留言