在自然語言處理 (NLP) 與 AI 應用中,文字轉向量 (Text Embedding) 是非常核心的一步。它可以將一段文字轉換成數字化的向量表示,方便電腦進行 相似度計算、語意檢索 (RAG)、推薦系統 等任務。
這篇文章會帶你了解:
- 為什麼要做文字轉向量
- 常用的向量模型有哪些
- 如何用 OpenAI API 生成向量
- 如何用 開源模型 (Sentence Transformers, BGE) 本地生成向量
- 模型選擇建議
1. 為什麼要將文字轉向量?
電腦本質上只能理解數字,像「我愛知識圖譜」這句話,模型需要將它轉換成一組數字向量,例如:
[0.12, -0.08, 0.33, ...]這樣一來:
- 不同句子之間就能比較「語意距離」
- 可以拿來做 相似度檢索(例如搜尋引擎、問答系統)
- 可以用在 推薦系統(找出語意相近的內容)
2. 常用的向量模型
目前主流有兩大類:
✅ OpenAI (雲端 API)
- text-embedding-3-small → 1536 維,速度快、便宜,效果比舊版好
- text-embedding-3-large → 3072 維,更高精度,適合需要極致語意理解的場景
✅ 開源模型 (本地部署)
- Sentence Transformers (SBERT):
all-MiniLM-L6-v2(小巧快速,英文檢索常用) - BGE (BAAI General Embedding):
BAAI/bge-base-zh(中文檢索表現優秀) - E5 系列:
intfloat/multilingual-e5-base(多語言支援)
3. OpenAI 文字轉向量範例
先安裝套件:
pip install openaiPython 實作:
from openai import OpenAI
client = OpenAI(api_key="your_api_key_here")
text = "我愛知識圖譜與自然語言處理"
# 使用最新 embedding 模型
response = client.embeddings.create(
model="text-embedding-3-large", # 或 "text-embedding-3-small"
input=text
)
vector = response.data[0].embedding
print(len(vector)) # 向量維度
print(vector[:10]) # 前10個數值輸出結果:
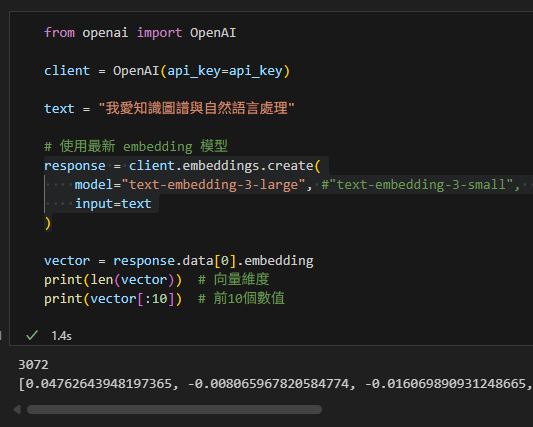
輸出結果:
text-embedding-3-small→ 向量長度 = 1536text-embedding-3-large→ 向量長度 = 3072
4. 開源模型 (本地轉向量)
如果你想在本地跑,不依賴雲端,可以用 HuggingFace 的 sentence-transformers。
安裝:
pip install sentence-transformersPython 範例:
from sentence_transformers import SentenceTransformer
# 輕量英文模型
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 中文檢索建議用 BGE
# model = SentenceTransformer('BAAI/bge-base-zh')
text = "我愛知識圖譜與自然語言處理"
vector = model.encode(text)
print(len(vector)) # 向量維度
print(vector[:10]) # 前10個數值常見維度:
all-MiniLM-L6-v2→ 384 維bge-base-zh→ 768 維bge-large-zh→ 1024 維
5. 模型選擇建議
- 快速檢索 / 成本敏感 →
text-embedding-3-small(1536 維) - 高精度需求 →
text-embedding-3-large(3072 維) - 中文專案 / 本地部署 →
BAAI/bge-base-zh - 多語言場景 →
multilingual-e5-base
🔚 總結
文字轉向量是 RAG (檢索增強生成)、語意搜尋 的基石。
- 如果你要快速上手,直接用 OpenAI
text-embedding-3-small。 - 如果你要本地化,推薦 BGE 中文模型 或 SBERT。
- 如果你要高精度,選
text-embedding-3-large。
推薦hahow線上學習python: https://igrape.net/30afN

 #封裝 CT_P (Complex Type Paragraph)為 Paragraph 物件")
![Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220923222039_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言")
串接; numpy.concatenate() ; pandas.concat() ; 擴充ndarray的維度 np.expand_dims()")
 如何略過首n列,末m列? df_footer = pd.read_csv(‘test.txt’, skiprows=1, skipfooter=1, engine=’python’) #”Footer” 可以翻譯為 “頁腳”,通常指網頁底部的區域,包含版權聲明、聯絡資訊、隱私政策等相關資訊。")

![Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/10/20221028151556_42.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6")
:台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免")


![Python TQC考題610 平均溫度,不要自找麻煩用2D list做,可練習2D轉1D: 一維串列.extend(二維串列[index]) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/05/20220515192908_35-520x245.png)

近期留言