在 pandas 數據分析中,.apply() 是一個強大且靈活的工具,
但它的行為會根據使用環境產生顯著差異。
本文將通過實際案例深入探討 .apply()
在不同上下文中的運作方式,幫助您更精確地操作數據。
理解 pandas 中的 row 與 column
在開始之前,讓我們明確 pandas 中的基本概念:
- row:資料表中的橫向資料,代表一個完整觀測值
- column:資料表中的縱向資料,代表一個變數或特徵
三種 apply() 的使用情境
讓我們探討 .apply() 在三種不同情境下的不同行為。
1. DataFrame.apply() – 操作整個 row 或 column
當我們對 DataFrame 使用 .apply() 時,
函數會應用於每個 row 或 column(取決於 axis 參數):
# axis=0 (預設) - 按 column 方向應用函數(對每個 column 操作)
df.apply(lambda x: x.sum())
# axis=1 - 按 row 方向應用函數(對每個 row 操作)
df.apply(lambda x: x.max(), axis=1)在這種情況下,x 是一個 Series 對象,代表一整個 row 或 column。
2. Series.apply() – 操作單個元素
當我們對 Series 使用 .apply() 時,函數會應用於 Series 中的每個元素:
df['Column_A'].apply(lambda x: x * 2)在這種情況下,x 是 Series 中的單個元素(標量值)。
3. GroupBy.apply() – 根據實際截圖分析
現在,讓我們根據提供的截圖,深入理解 GroupBy 上下文中的 .apply()。
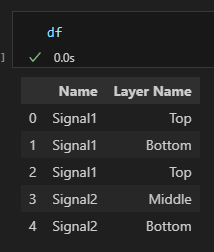
df.groupby(‘Name’)
df.groupby(‘Name’)[‘Layer Name’]
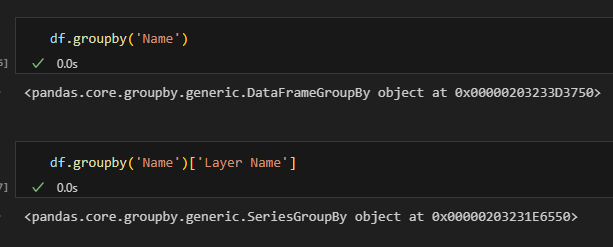
df.groupby(‘Name’)是一個
DataFrameGroupBy object
結構類似Dict[Name, DataFrame]
df.groupby(‘Name’)[‘Layer Name’]則是一個
SeriesGroupBy object
結構類似Dict[Name, Series]
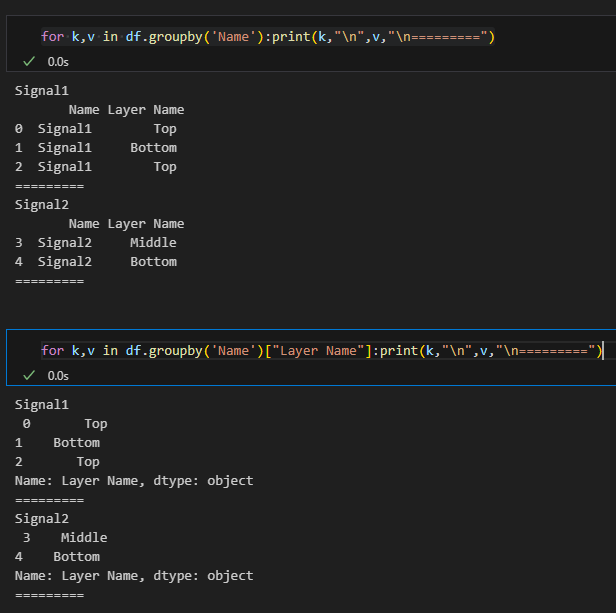
for k,v in df.groupby('Name'):print(k,"\n",v,"\n=========")
for k,v in df.groupby('Name')["Layer Name"]:print(k,"\n",v,"\n=========")
.apply()
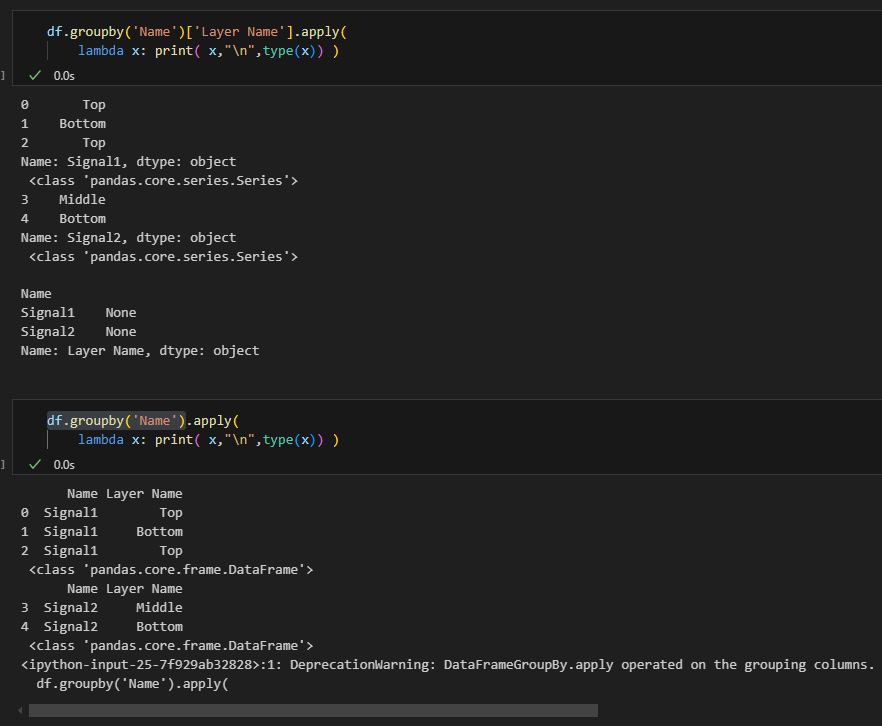
案例A:df.groupby(‘Name’)[‘Layer Name’].apply()
df.groupby('Name')['Layer Name'].apply(
lambda x: print(x, "\n", type(x),"\n==========") )截圖中的輸出清楚地展示了:
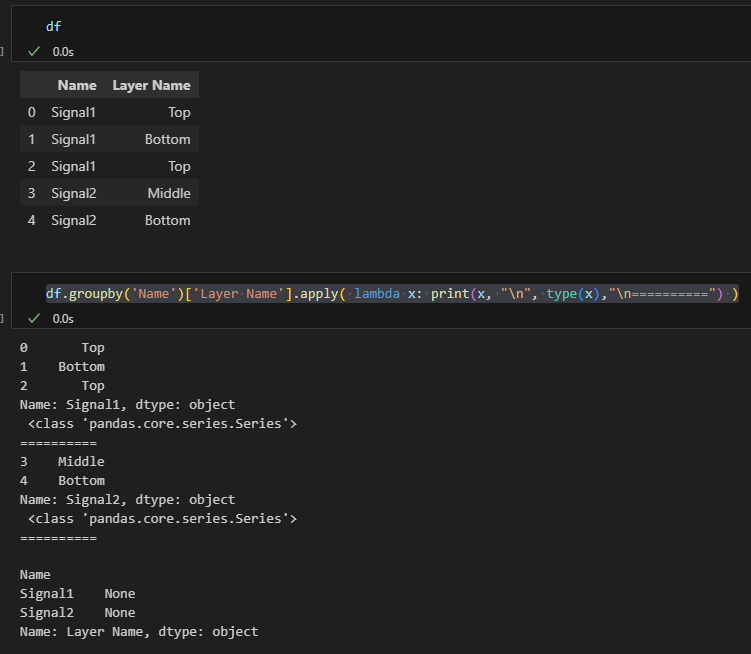
從截圖中可以看到:
x是一個 Series 對象- 每個 Series 包含對應分組(’Signal1′ 或 ‘Signal2’)的所有 ‘Layer Name’ 值
- Series 的索引保持原始 DataFrame 的索引(0, 1, 2 或 3, 4)
- 每個 Series 都有名稱(Name: Signal1 或 Name: Signal2)
這表明,當我們對 df.groupby('column_name')['another_column'] 使用 .apply() 時,
函數會應用於每個分組產生的 Series。
實際應用範例
讓我們基於截圖中的數據結構,展示一些實用的操作:
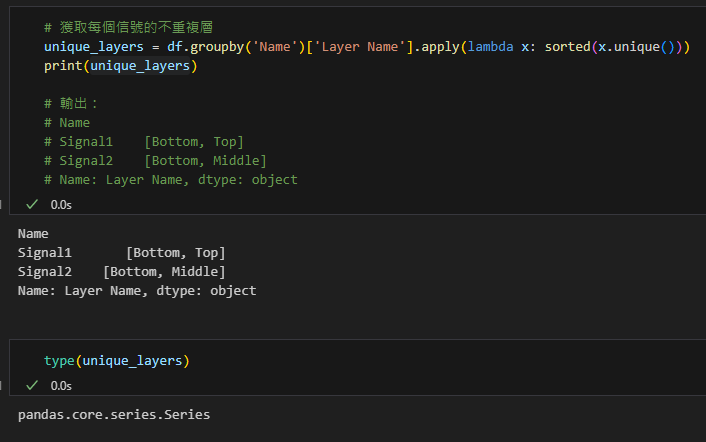
範例1:獲取每個信號的不重複層名稱
# 獲取每個信號的不重複層
unique_layers = df.groupby('Name')['Layer Name'].apply(lambda x: sorted(x.unique()))
print(unique_layers)
# 輸出:
# Name
# Signal1 [Bottom, Top]
# Signal2 [Bottom, Middle]
# Name: Layer Name, dtype: object輸出結果:
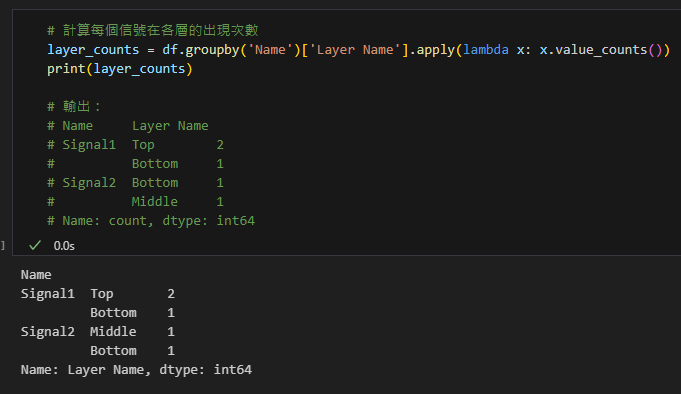
範例2:計算每個信號出現在各層的次數
# 計算每個信號在各層的出現次數
layer_counts = df.groupby('Name')['Layer Name'].apply(lambda x: x.value_counts())
print(layer_counts)
# 輸出:
# Name Layer Name
# Signal1 Top 2
# Bottom 1
# Signal2 Bottom 1
# Middle 1
# Name: count, dtype: int64輸出:
範例3:將層名連接成字符串
# 將每個信號的所有層名連接成一個字符串
layers_joined = df.groupby('Name')['Layer Name'].apply(lambda x: ' | '.join(x))
print(layers_joined)
# 輸出:
# Name
# Signal1 Top | Bottom | Top
# Signal2 Middle | Bottom
# Name: Layer Name, dtype: object輸出結果:
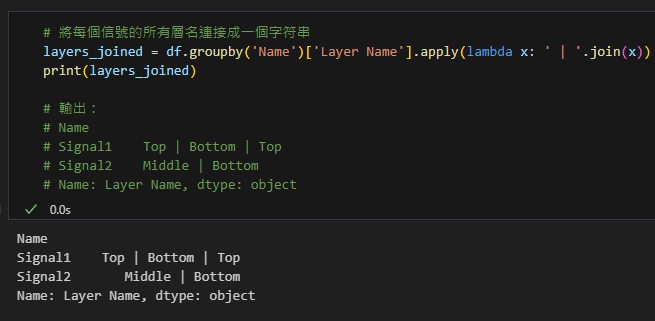
SeriesGroupBy.apply() 與 DataFrameGroupBy.apply() 的區別
讓我們比較這兩種 GroupBy 操作的區別:
- SeriesGroupBy.apply():
df.groupby('Name')['Layer Name'].apply(lambda x: ...)x是一個 Series 對象,包含該分組的 ‘Layer Name’ column 值- 適合當我們只需要處理單個 column 時使用
DataFrameGroupBy.apply():
df.groupby('Name').apply(lambda x: ...)-
x是一個 DataFrame 對象,包含該分組的所有 row 和所有 column- 適合當我們需要處理分組內的多個 column 時使用
如何選擇正確的 apply 方法?
基於上述理解,我們可以制定以下選擇準則:
- 如果需要處理單個元素:使用 Series.apply()
df['Layer Name'].apply(lambda x: x.upper())如果需要處理整個 row 或 column:使用 DataFrame.apply()
df.apply(lambda row: process_row(row), axis=1) # 處理 row如果需要分組後處理單個 column 的數據:使用 SeriesGroupBy.apply()
df.groupby('Name')['Layer Name'].apply(lambda x: process_group_series(x))如果需要分組後處理多個 column:使用 DataFrameGroupBy.apply()
df.groupby('Name').apply(lambda x: process_group_dataframe(x))實用技巧:使用 print 進行調試
從截圖中的例子可以看出,使用 print() 來檢查 x 的內容和類型是一個非常有用的調試技巧。當您不確定 .apply() 中的 x 是什麼時,可以使用以下代碼進行調試:
df.groupby('Name')['Layer Name'].apply(lambda x: print(f"Type: {type(x)}\nContent: {x}\n"))這將幫助您了解函數參數的確切結構,從而編寫更準確的處理邏輯。
總結
理解 pandas 中 .apply() 在不同上下文中的行為差異是高效數據分析的關鍵。特別是:
- Series.apply():操作的是單個元素
- DataFrame.apply():操作的是整個 row 或 column
- SeriesGroupBy.apply():操作的是分組後的 Series
- DataFrameGroupBy.apply():操作的是分組後的 DataFrame
在實際工作中,選擇正確的方法不僅能讓代碼更簡潔,還能提高處理效率。希望本文的實際案例分析能幫助您更好地掌握 pandas 的強大功能。
實踐建議:在處理新的數據分析任務時,不妨先使用 print(x, type(x)) 檢查 .apply() 函數中的參數,這樣可以確保您正確理解了數據的結構,從而編寫更準確的處理邏輯。
推薦hahow線上學習python: https://igrape.net/30afN


 與 .get() 的使用指南; dict.pop() 支援第二個參數#key不存在的話,返回第二個參數, list.pop() 不支援第二個參數")
 ; OrderedDict.fromkeys()")

串接; numpy.concatenate() ; pandas.concat() ; 擴充ndarray的維度 np.expand_dims()")

:台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免")
 #獲取時間戳; localtime = time.localtime( timestamp ) #獲取localtime; fmt= ‘%Y-%m-%d %H:%M:%S’ ; strftime = time.strftime(fmt, localtime) 等效於 datetime.datetime.now().strftime(fmt) #獲取strftime #str format time ;")
![Python: 如何使用 os.environ[“PATH”] 設定環境變數?與 sys.path.append() 差別為何?](https://savingking.com.tw/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

近期留言