config = “Config”
print( config.encode() )
config_list = list(config.encode())
print(config_list)
str1=”儲蓄保險王”
print(str1.encode()) #預設值為utf-8
print(str1.encode(“utf-8”))
str1Lst = list(str1.encode())
print(str1Lst)
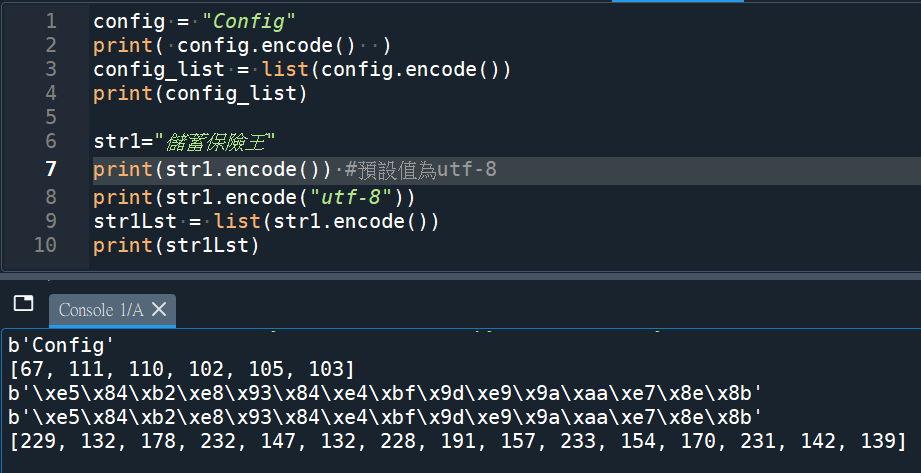
[67,111,110,102,105,103]
其實只是C o n f i g的ASCII碼(ord函數)
用以下語法也可以萃取出一樣的list:
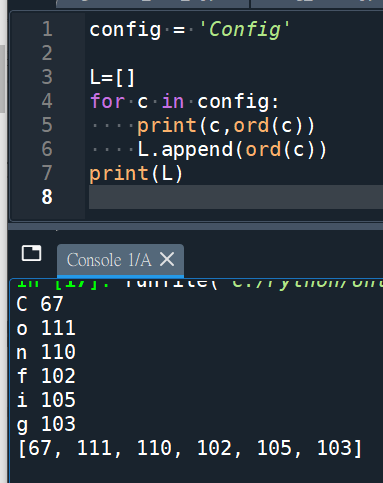
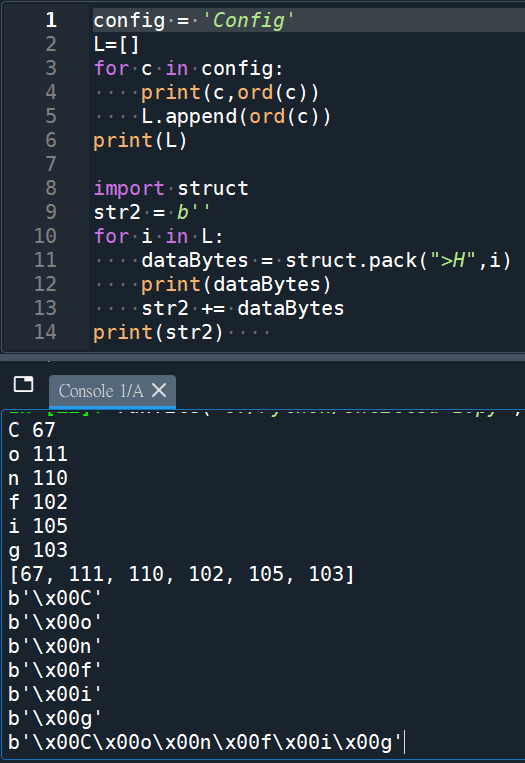
與matlab結果一致:
rx_ctrl: b’\x00C\x00o\x00n\x00f\x00i\x00g’
Control:
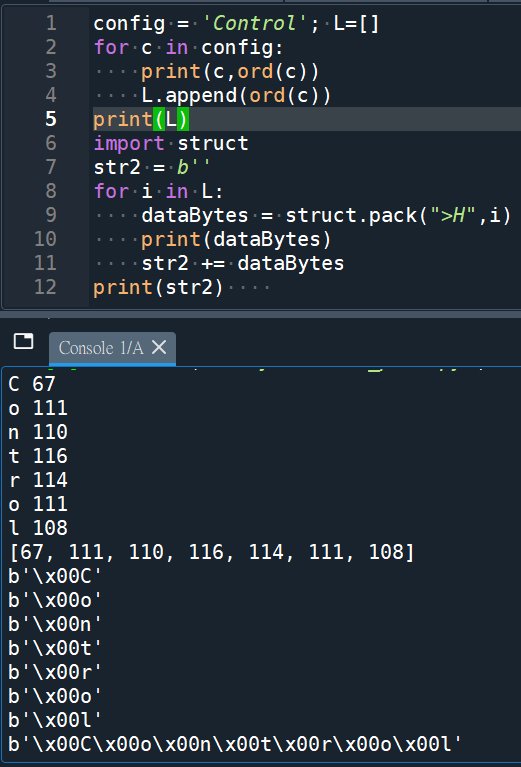
b’\x00C\x00o\x00n\x00t\x00r\x00o\x00l’
ReControl:
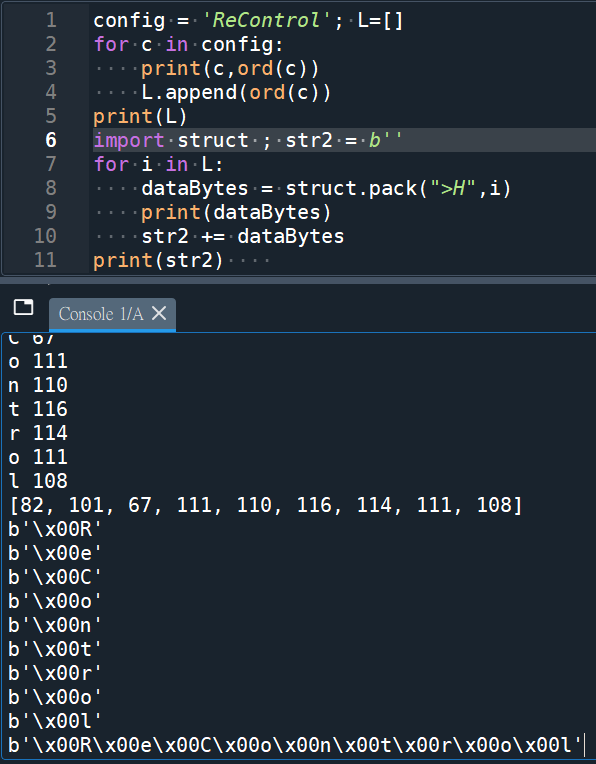
b’\x00R\x00e\x00C\x00o\x00n\x00t\x00r\x00o\x00l’
![Python如何讀寫csv逗點分隔檔(每列內容為新光增有利現金流)?pandas.read_csv(r”路徑\檔名.副檔名”),如何移除list中的nan元素?math.isnan(),如何計算新光增有利IRR?numpy_financial(array) ;輸出csv檔時如何去掉index跟header?如何選擇要寫入的直欄columns? dfFinal.to_csv(fpath, index=False, header=None, columns=[0,1])](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221110122900_3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何讀寫csv逗點分隔檔(每列內容為新光增有利現金流)?pandas.read_csv(r”路徑\檔名.副檔名”),如何移除list中的nan元素?math.isnan(),如何計算新光增有利IRR?numpy_financial(array) ;輸出csv檔時如何去掉index跟header?如何選擇要寫入的直欄columns? dfFinal.to_csv(fpath, index=False, header=None, columns=[0,1])")


 ) ) ; listbox = tk.Listbox (root, listvariable = menu)")

 ; from sklearn.neighbors import KNeighborsClassifier ; from sklearn.model_selection import train_test_split")
 as source: audio = r.record(source) ; 如何使用mic當音源? with sr.Microphone() as source: audio_data = recognizer.listen(source)")
?")
![Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2024/11/20241123194900_0_5218de.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]")

![Python: pandas.DataFrame (df) 的取值: df [單一字串] 或df [list_of_strings] 選取一個或多個columns; df [切片] 或 df [bool_Series] 選取多個rows #bool_Series長度同rows, index也需要同df.index ,可以使用.equals() 確認: df.index.equals(mask.index) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/04/20250420212553_0_6fb2c3-512x245.png)

近期留言