from sklearn import linear_model
regr = linear_model.LinearRegression(*,)
#產生regr操作子,可命名為lmLR
*右方的參數,
表示要連名帶姓寫出參數名稱
依順序寫不行

regr.fit(x,y)
#直接對操作子regr產生影響

regr.coef_ #係數
regr.intercept_ #截距

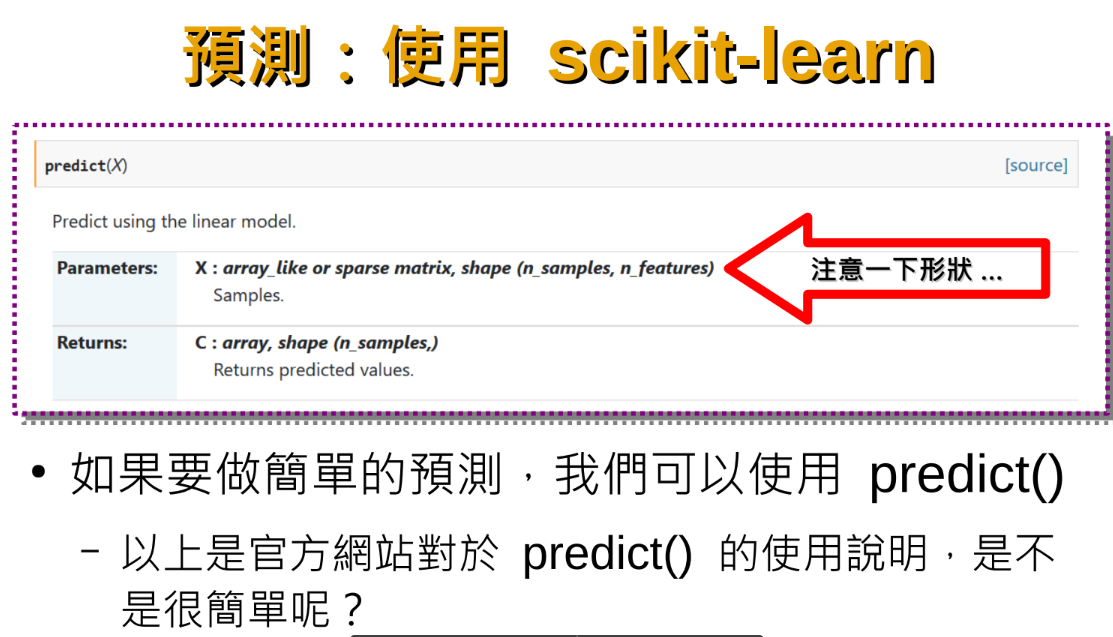
pred = regr.predict([[40],[5],[15]]) #注意shape
regression:

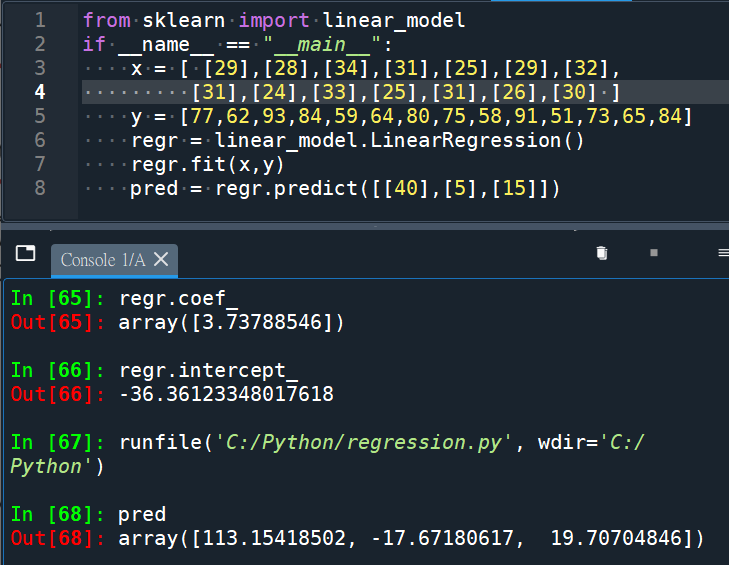
from sklearn import linear_model
if __name__ == “__main__”:
x = [ [29],[28],[34],[31],[25],[29],[32],[31],[24],[33],[25],[31],[26],[30] ]
y = [77,62,93,84,59,64,80,75,58,91,51,73,65,84]
regr = linear_model.LinearRegression()
regr.fit(x,y)
pred = regr.predict([[40],[5],[15]])
加碼題:

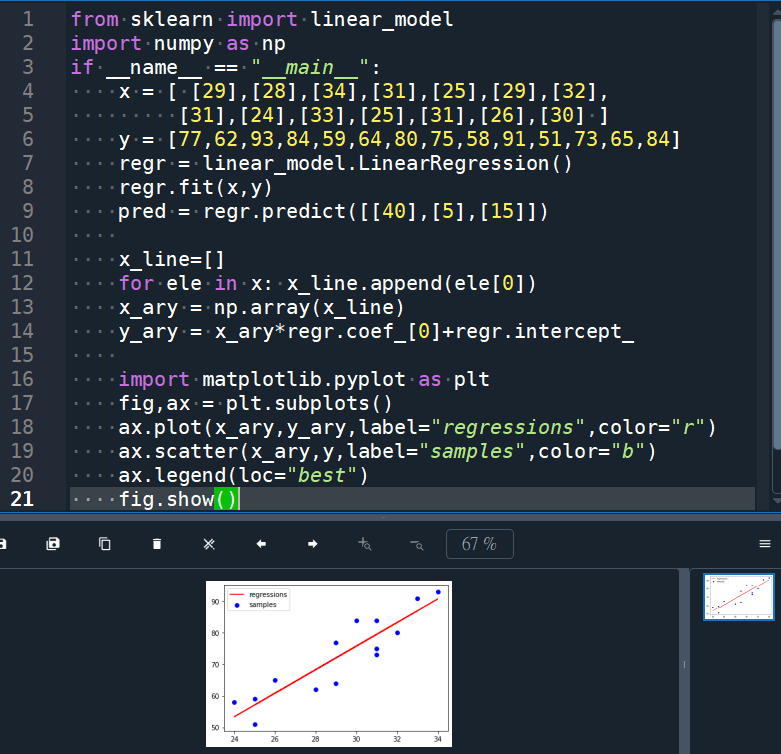
from sklearn import linear_model
import numpy as np
if __name__ == “__main__”:
x = [ [29],[28],[34],[31],[25],[29],[32],
[31],[24],[33],[25],[31],[26],[30] ]
y = [77,62,93,84,59,64,80,75,58,91,51,73,65,84]
regr = linear_model.LinearRegression()
regr.fit(x,y)
pred = regr.predict([[40],[5],[15]])
x_line=[]
for ele in x: x_line.append(ele[0])
x_ary = np.array(x_line)
y_ary = x_ary*regr.coef_[0]+regr.intercept_
import matplotlib.pyplot as plt
fig,ax = plt.subplots()
ax.plot(x_ary,y_ary,label=”regressions”,color=”r”)
ax.scatter(x_ary,y,label=”samples”,color=”b”)
ax.legend(loc=”best”)
fig.show()
參考解答:


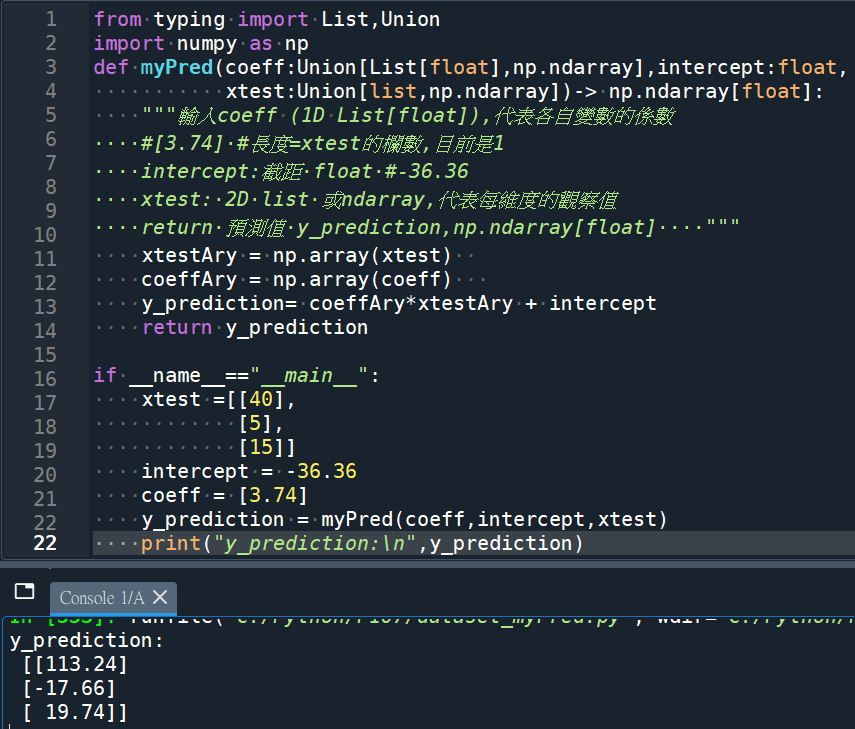
from typing import List,Union
import numpy as np
def myPred(coeff:Union[List[float],np.ndarray],intercept:float,
xtest:Union[list,np.ndarray])-> np.ndarray[float]:
“””輸入coeff (1D List[float]),代表各自變數的係數
#[3.74] #長度=xtest的欄數(.shape[1]),目前是1
intercept:截距 float #-36.36
xtest: 2D list 或ndarray,代表每維度的觀察值
return 預測值 y_prediction,np.ndarray[float] “””
xtestAry = np.array(xtest)
coeffAry = np.array(coeff)
y_prediction= coeffAry*xtestAry + intercept
return y_prediction
if __name__==”__main__”:
xtest =[[40],
[5],
[15]]
intercept = -36.36
coeff = [3.74]
y_prediction = myPred(coeff,intercept,xtest)
print(“y_prediction:\n”,y_prediction)
#y_prediction 不該是2D
#應該是因為xtest的第二維長度只有1
#幸運跑出來而已,還要繼續處理的
#coeff[0]*xtest的第0欄+coeff[1]*xtest的第1欄+…
#需要取直欄,pandas可能比較好用
#或使用array的切片方式
參考解答:
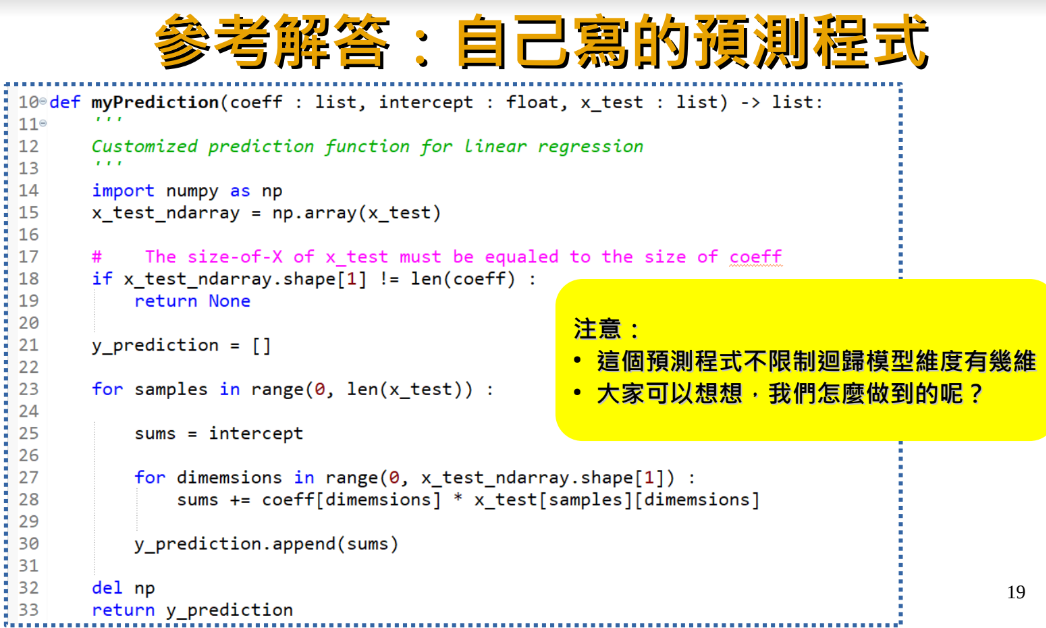

小修正:
from typing import List,Union
import numpy as np
def myPred(coeff:Union[List[float],np.ndarray],intercept:float,
xtest:Union[list,np.ndarray])-> np.ndarray[float]:
“””輸入coeff (1D List[float]),代表各自變數的係數
#[3.74] #長度=xtest的欄數(.shape[1]),目前是1
intercept:截距 float #-36.36
xtest: 2D list 或ndarray,代表每維度的觀察值
return 預測值 y_prediction,np.ndarray[float] “””
xtestAry = np.array(xtest)
coeffAry = np.array(coeff)
if len(coeff) != xtestAry.shape[1]:return [None]
for i in range(len(coeffAry)):
y_prediction= coeffAry[i]*xtestAry[:,i] #+intercept?
y_prediction += intercept
#+intercept放迴圈內可能會重複加
#本例迴圈僅有一次,所以看不出差別
return y_prediction
if __name__==”__main__”:
xtest =[[40],
[5],
[15]]
intercept = -36.36
coeff = [3.74]
y_prediction = myPred(coeff,intercept,xtest)
print(“y_prediction:\n”,y_prediction)
反轉 .sort()排序 .remove(“指定元素”)移除 .pop(index)移除, 字串.replace(old,new) .lower()小寫 .upper()大寫 .title()首字大寫")
 ; from docx.document import Document as DocxDocument #類別,非function ; from docx.table import _Cell, Table #儲存格/表格 類別")
![Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313160116_63.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame([ ]) 與 pandas.DataFrame([[ ]]) 的差別? 如何為DataFrame增加首列?")

 ; s.index ; s.values; 類比於dict.keys ; dict.values ; Series有index跟value,可以跟dict互轉;同list的切片可以取值")

")
 ; from sklearn.neighbors import KNeighborsClassifier ; from sklearn.model_selection import train_test_split")

![Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄? df['sum_AB'] = df.apply(sum_ab, axis=1) ; lambda函式 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230314200417_4-520x245.png)

近期留言