本篇僅為邏輯說明
magicStr = “SavingKing” #實際資料為 bytearray
offset = len(magicStr) #10
strdata = magicStr + “ab” + magicStr +”cd” + magicStr + “ef”
#’SavingKingabSavingKingcdSavingKingef’
# 簡化的資料,實際應用可能一長串 bytearray
lis_wanted=[]
while strdata:
nextIdx = strdata.find(magicStr,1)
#len(magicStr) =10
#1改成10也可以跑出一樣的結果
if nextIdx==-1:break
wanted = strdata[offset:offset+2]
#擷取到資料後,再做struct.unpack_from()的動作
#本篇簡化版略過
lis_wanted.append(wanted)
strdata = strdata[nextIdx:]
#print(strdata)
print(lis_wanted)
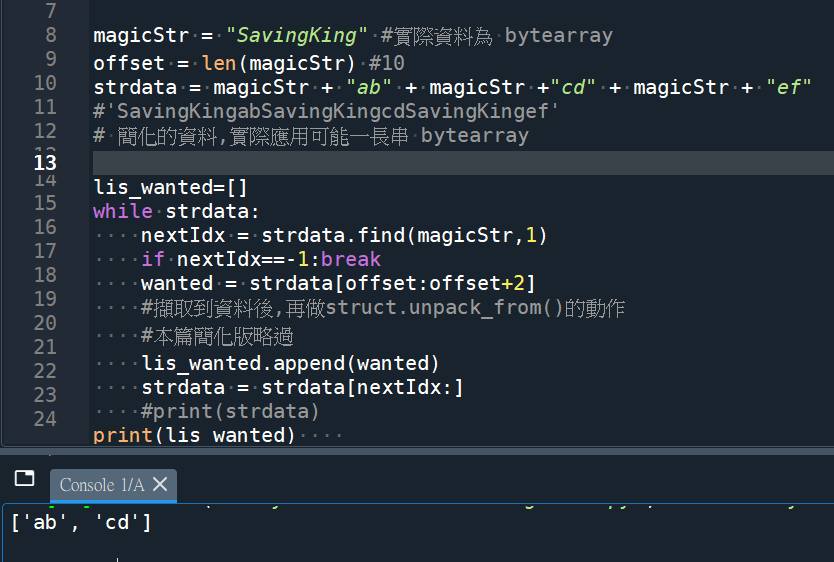
str.find()的效果:
若搜尋不到則返回-1
if nextIdx==-1:break
搜尋不到則跳出迴圈
簡化版程式輸出:
[‘ab’, ‘cd’]
看起來少抓了最後一個”ef”
但真實資料,最後一個迴圈
因為長度不足,會出現:
error: unpack requires a buffer of 36 bytes
實際應用是正確的
推薦hahow線上學習python: https://igrape.net/30afN

 切割資料(波士頓地區房價)為訓練資料跟測試資料; from sklearn.model_selection import train_test_split ; xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.3, random_state=42, shuffle=True)")
")
 讀取逗點分隔檔並忽略空列,跳過某些列? dfRaw = pd.read_csv (fpath, skip_blank_lines = True, skiprows =6)")
 vs 非貪婪 (Lazy) ; .* vs .*?")
from openai import AsyncAzureOpenAI")


![Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230502163945_79.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5)")

你好,我也是遇到了同样的问题,需要将AWR1443上保存的dat文件在python上解码观察数据,是否方便提供一下完整的python代码?如果有需要可以有偿。谢谢