在數據分析中,數據結構的轉換對於後續處理至關重要。
本文將介紹如何使用 Pandas 中的 set_index 和 unstack
將”長格式”數據轉換為更易分析的”寬格式”,以 PCB 走線設計數據為例。
什麽是長格式與寬格式?
- 長格式(Long Format): 每個觀測值占一row,信息分散在多rows中
- 寬格式(Wide Format): 每個主體占一col,相關信息橫向展開為多col
實例數據
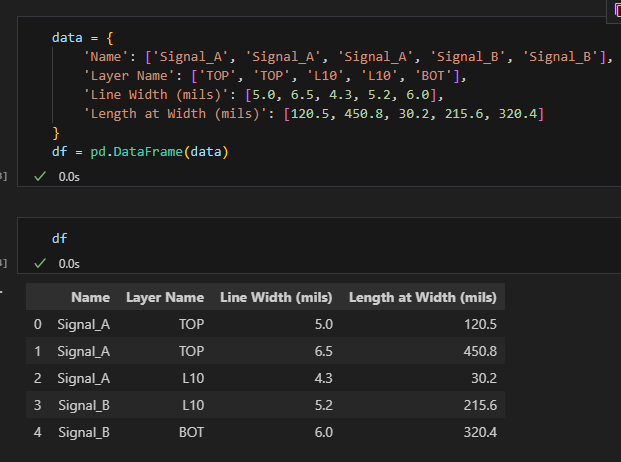
假設我們有以下 PCB 走線數據(長格式):
# 示例數據 - 長格式
data = {
'Name': ['Signal_A', 'Signal_A', 'Signal_A', 'Signal_B', 'Signal_B'],
'Layer Name': ['TOP', 'TOP', 'L10', 'L10', 'BOT'],
'Line Width (mils)': [5.0, 6.5, 4.3, 5.2, 6.0],
'Length at Width (mils)': [120.5, 450.8, 30.2, 215.6, 320.4]
}
df = pd.DataFrame(data)
# 輸出結果:
# Name Layer Name Line Width (mils) Length at Width (mils)
# 0 Signal_A TOP 5.0 120.5
# 1 Signal_A TOP 6.5 450.8
# 2 Signal_A L10 4.3 30.2
# 3 Signal_B L10 5.2 215.6
# 4 Signal_B BOT 6.0 320.4輸出結果:
轉換函數詳解
讓我們分解 restructure_trace_data_alt 函數的每個步驟:
def restructure_trace_data_alt(df):
"""使用set_index和unstack重構PCB走線數據"""
# 步驟1: 處理Layer Name - 合並每個信號的所有層信息
layer_info = df.groupby('Name')['Layer Name'].apply(
lambda x: ' | '.join(sorted(x.unique()))
).reset_index()
# 步驟2: 為寬度分組創建序號
df_sorted = df.sort_values(['Name', 'Line Width (mils)'])
df_sorted['segment_num'] = df_sorted.groupby('Name').cumcount() + 1
# 步驟3: 轉換寬度數據
width_df = df_sorted.set_index(['Name', 'segment_num'])['Line Width (mils)'].unstack()
width_df.columns = [f'Line Width {i} (mils)' for i in width_df.columns]
# 步驟4: 轉換長度數據
length_df = df_sorted.set_index(['Name', 'segment_num'])['Length at Width (mils)'].unstack()
length_df.columns = [f'Length at Width {i} (mils)' for i in length_df.columns]
# 步驟5: 合併結果
result = pd.merge(layer_info, width_df.reset_index(), on='Name')
result = pd.merge(result, length_df.reset_index(), on='Name')
return result分步驟圖解轉換過程
步驟1: 處理層信息
# 合併每個信號的所有層信息
layer_info = df.groupby('Name')['Layer Name'].apply(
lambda x: ' | '.join(sorted(x.unique()))
).reset_index()
# 輸出結果
# Name Layer Name
# 0 Signal_A L10 | TOP
# 1 Signal_B BOT | L10輸出結果:
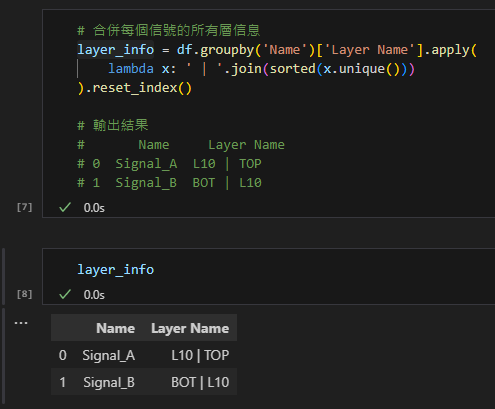
這一步將每個信號的所有層信息合並為一個字符串,
使用豎線分隔,並按字母順序排序。
步驟2: 創建段序號
# 先按信號名稱和線寬排序
df_sorted = df.sort_values(['Name', 'Line Width (mils)'])
# 為每個信號的每段走線創建序號 (1, 2, 3...)
df_sorted['segment_num'] = df_sorted.groupby('Name').cumcount() + 1
# 輸出結果
# Name Layer Name Line Width (mils) Length at Width (mils) segment_num
# 2 Signal_A L10 4.3 30.2 1
# 0 Signal_A TOP 5.0 120.5 2
# 1 Signal_A TOP 6.5 450.8 3
# 3 Signal_B L10 5.2 215.6 1
# 4 Signal_B BOT 6.0 320.4 2輸出結果:
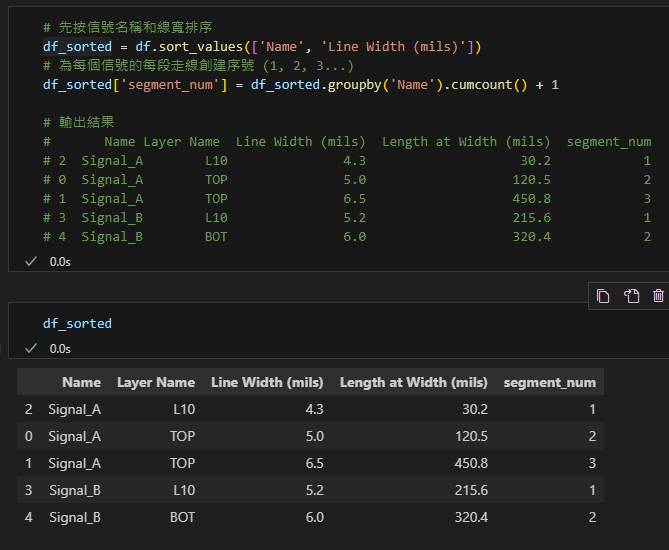
這一步為每個信號的各段走線創建順序編號,
確保寬度從小到大排列。
步驟3-4: 使用 set_index 和 unstack 創建寬格式
# %%
# 轉換寬度數據
width_df = df_sorted.set_index(['Name', 'segment_num'])['Line Width (mils)'].unstack()
width_df.columns = [f'Line Width {i} (mils)' for i in width_df.columns]
# 輸出結果
# segment_num Line Width 1 (mils) Line Width 2 (mils) Line Width 3 (mils)
# Name
# Signal_A 4.3 5.0 6.5
# Signal_B 5.2 6.0 NaN輸出結果:
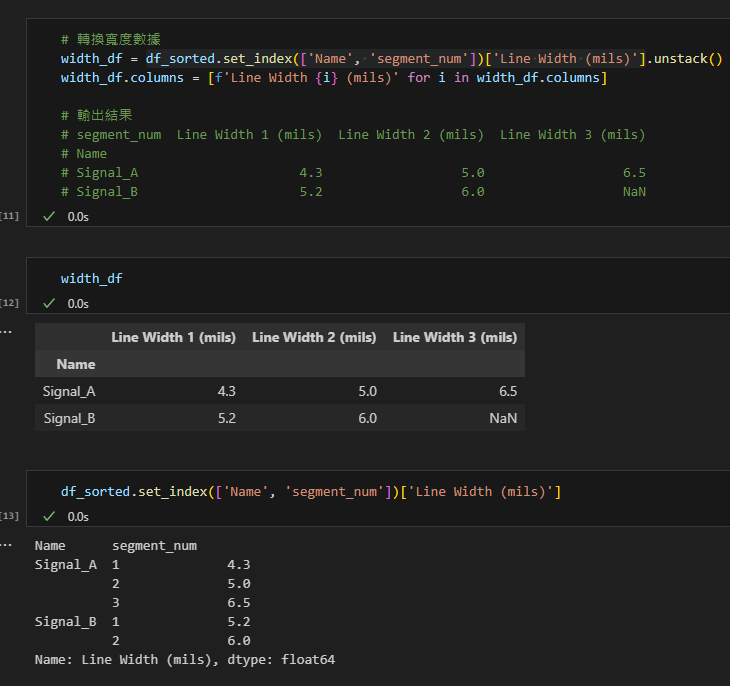
set_index 創建多級索引,
unstack 將 segment_num 變為列名,
每個單元格包含對應的寬度值。
同樣的方法用於長度數據:
# %%
# 轉換長度數據
length_df = df_sorted.set_index(['Name', 'segment_num'])['Length at Width (mils)'].unstack()
length_df.columns = [f'Length at Width {i} (mils)' for i in length_df.columns]
# 輸出結果
# segment_num Length at Width 1 (mils) Length at Width 2 (mils) Length at Width 3 (mils)
# Name
# Signal_A 30.2 120.5 450.8
# Signal_B 215.6 320.4 NaN輸出結果:
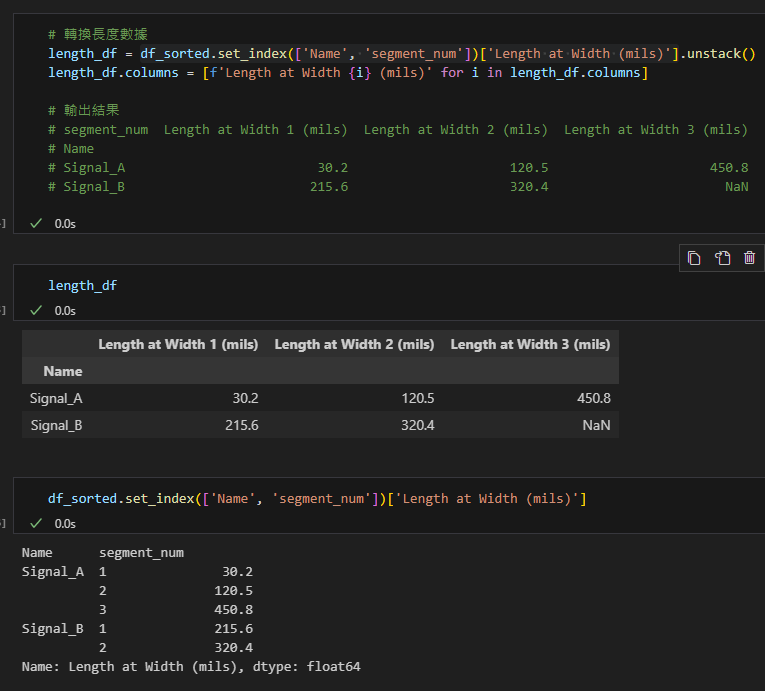
步驟5: 合併結果
# %%
# %%
# 合併層信息和寬度/長度數據
result = pd.merge(layer_info, width_df.reset_index(), on='Name')
result = pd.merge(result, length_df.reset_index(), on='Name')
# 最終結果
# Name Layer Name Line Width 1 (mils) Line Width 2 (mils) Line Width 3 (mils) Length at Width 1 (mils) Length at Width 2 (mils) Length at Width 3 (mils)
# 0 Signal_A L10 | TOP 4.3 5.0 6.5 30.2 120.5 450.8
# 1 Signal_B BOT | L10 5.2 6.0 NaN 215.6 320.4 NaN輸出結果:

merge分解動作:
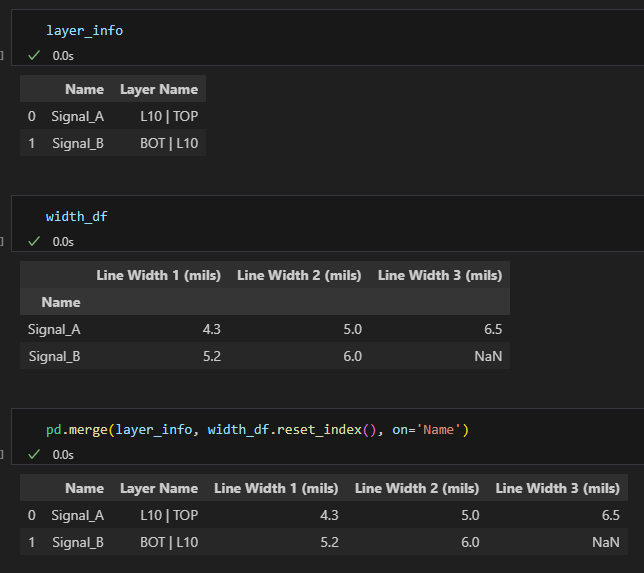
也可使用concat() 合併:
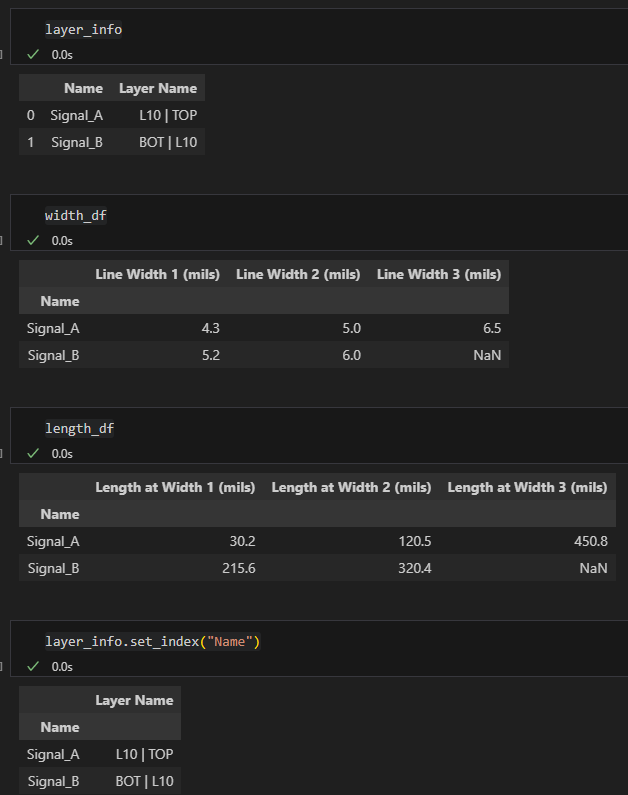
result= pd.concat([layer_info.set_index("Name"),width_df,length_df],axis=1)
#axis=1,橫向合併
#index 要一模一樣,才不會有缺失值
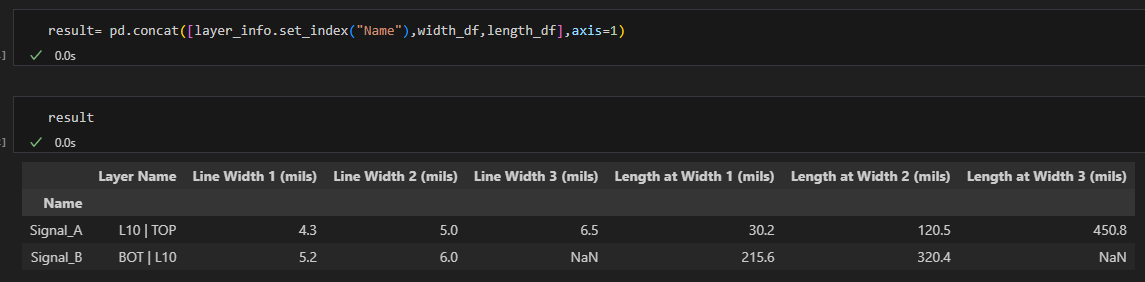
技術要點
- cumcount() 才知道有幾個Name (幾種不同的Width/Length)
set_index: 將一個或多個列設為索引,創建分層結構unstack: 將行索引轉換為列,實現長格式到寬格式的轉換groupby+apply: 用於聚合並轉換組內數據reset_index: 將索引轉回普通列,便於後續合併pd.merge: 基於共同列合併多個DataFrame
或者使用pd.concat()基於共同index合併多個DataFrame
優勢分析
與傳統的循環方法(如手動構建字典列表)相比,這種方法具有以下優勢:
- 性能更高: 利用了Pandas的向量化操作,大數據集下速度明顯更快
- 代碼更簡潔: 8-10行代碼完成轉換,而循環方法通常需要20-30行
- 內存效率: 避免了多次創建中間數據結構
- 自動處理缺失值: 對於不同行數的信號,自動填充NaN
結論
使用 set_index 和 unstack 轉換數據格式不僅提高了代碼效率,也使數據結構更適合後續分析。這種方法特別適合處理PCB設計數據、時間序列數據和各類分類數據的重構。掌握這種技術將極大提升您的數據處理能力。
推薦hahow線上學習python: https://igrape.net/30afN
; from lxml import etree; doc_xml = zfin.read(‘word/document.xml’) ; doc_tree = etree.fromstring(doc_xml) ; used_rids = set( doc_tree.xpath( “//@r:embed | //@r:link | //@r:id”, namespaces=ns_map)) #獲取 word/document.xml 有使用的used_rids => 讀取 document.xml.rels 建立白名單 keep_files以及黑名單 rels_to_remove ,要移除的Relationship節點 => 從 XML 樹中移除未使用的 Relationship 節點 => 重寫 Zip (過濾孤兒檔案, 更新document.xml.rels,其他原樣複製)")
![Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2026/05/20260527141829_0_5a8a75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?")
 ; np.hstack(tuple) ; ravel(“F”) #解開(線團等),把二維array轉成一維")

? 如何做出計算機? eval() 可將字串還原為python指令")
 函數; from docx.oxml.ns import qn #qualified name ; qn(‘w:p’) ; qn(‘w:tbl’)")
 ; json的保留字:null, true, false(區分大小寫,全小寫), null(非”null”,非Null)自動轉譯為None, true(非”true”,非True)自動轉譯為True(bool), false(非”false”,非False)自動轉譯為False(bool);colab如何掛載雲端硬碟? from google.colab import drive ; json檔的decode與encode? json.load() ; json.loads() ; json.dump() ; json.dumps() #s代表string的意思,有s的指令,參數需使用str type")
 , 如何計算IRR? numpy_financial.irr() 免費下載IRR計算機,如何寫入csv檔? csv.writer(f).writerows(2D List) ; if not os.path.exists(folder): os.makedirs(folder)")
 程式碼input(),終端機卻無法輸入資料且顯示亂碼,該如何設定?齒輪 > 設定,搜尋: run in terminal, 打勾: Wether to run code in integrated Terminal.")
![Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221112184006_50-520x245.png)
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced-336x245.png)
![Python TQC考題910 學生基本資料, print(line.decode("utf-8")), if line.decode("utf-8").split()[2] =="0": female += 1 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/05/20220514163621_72-520x245.png)

近期留言